
AGI临界点已到,AI自举爆发将至!

OpenAI知名研究人员频频暗示,o1的真实意图远不止于此。
传奇黑客Gwern更是放出了一个令人震撼的预测:我们已经达到了「递归自我改进」的临界点,o4或o5就能接管AI研发的剩余工作。
o1的隐藏使命:数据工厂
原来,o1的主要价值并不是用来部署,而是为后续模型生成训练数据!
每一个o1解决的问题,都将成为o3的训练数据点。当o1最终找到正确答案时,就能生成一份干净的对话记录,用来训练更精确的直觉。

这也解释了为什么Anthropic没有发布Claude-3.6-opus——它并没有失败,而是选择将其保留为内部模型,蒸馏出体积小但智能惊人的Claude-3.6-sonnet。
Gwern对OpenAI发布o1-pro都感到些许惊讶,认为他们本可以将这些计算资源用于o3的自举训练。
OpenAI员工的狂喜
OpenAI的员工们最近在Twitter上表现出异常的乐观,几乎到了欣喜若狂的地步。
Gwern认为,这是因为他们亲眼见证了从最初的4o模型到o3(以及现在的进展!)的惊人提升。
就像观看AlphaGo的等级分曲线:它不断上升……再上升……继续上升……
OpenAI似乎已经「突破」了,终于跨过了最后的临界门槛。
从仅仅领先竞争对手几年的尖端AI研究,进入了真正的「起飞期」。
o3的惊人表现
OpenAI最新发布的o3模型展现出了惊人的性能:
-
在Codeforces上获得2727分,成为全球排名第175位的竞赛程序员
-
在FrontierMath上得分25%,而这些问题「需要专业数学家花费数小时才能解决」
-
在GPQA上得分88%,其中70%就代表博士级的科学知识水平
-
在ARC-AGI上得分88%,而普通人在这种高难度视觉推理问题上的平均分只有75%
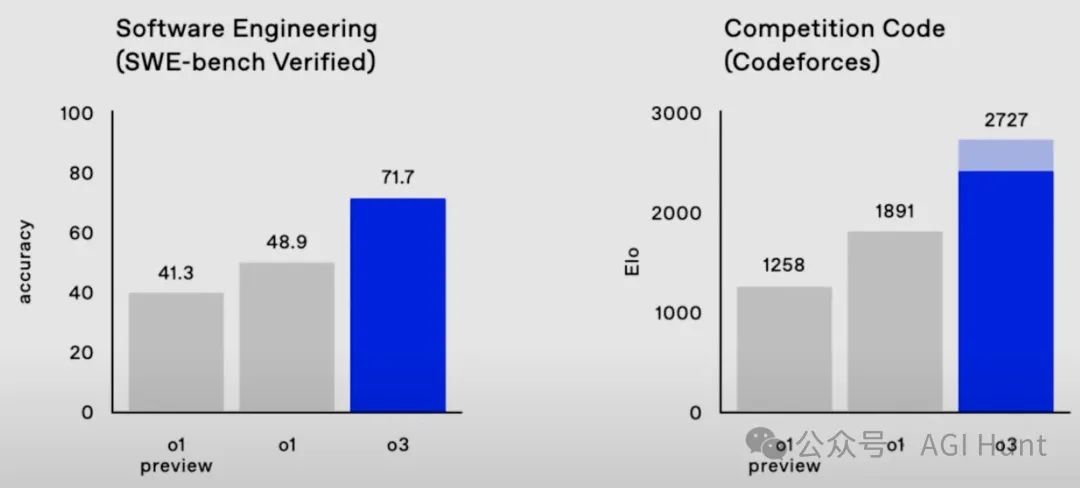
更令人惊讶的是,o3-mini在许多编程任务上能以更低的成本超越o1的表现!
AGI已无悬念?
Sam Altman在2024年11月说:「我能看到一条道路,我们正在做的工作会不断积累,过去三年的进步速度将在未来三年或六年或九年内持续」。

一周前,他更是直言:「我们现在确信知道如何构建传统意义上的AGI……我们开始将目标转向超越这一点,瞄准真正意义上的超级智能。」
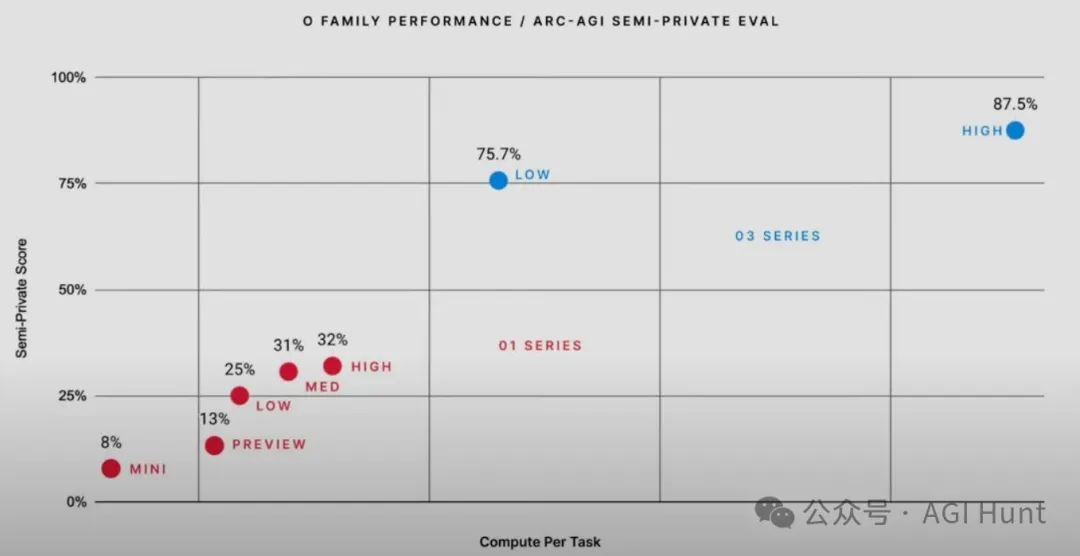
在Gwern看来,这意味着OpenAI已经掌握了递归自我改进的关键,o4或o5将能够自动化AI研发并完成剩余的工作。
至于其他公司?
「让DeepSeek追逐他们的尾灯吧,」Gwern说,「一旦超级智能研究能够自给自足,他们就再也得不到竞争所需的大型计算资源了。」
Deekseek:

这真的可能吗?
从最初的4o模型到现在的o3,进步速度就像看着AlphaGo的等级分曲线:它不断上升……再上升……继续上升……
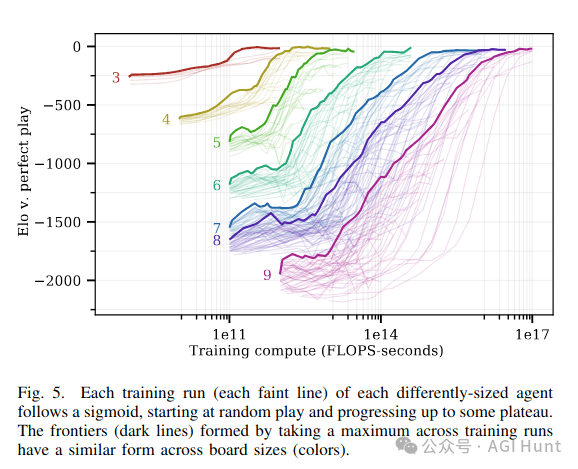
Gwern指出,如果简单的搜索就能奏效,国际象棋早在上世纪60年代就该被解决了。
想要让一群猴子在打字机上敲出「Hello World」也许还能行,但要想在质子衰变前敲出完整的《哈姆雷特》,你最好还是去克隆莎士比亚。
而现在,OpenAI已经证实o3-mini在许多编程任务上能以更低的成本超越o1的表现。
这个趋势很可能会持续下去。
后果就是,外部可能永远看不到中间模型了——就像围棋选手从未见过AlphaZero训练过程中的随机检查点一样。
Metaculus和Manifold Market的AGI预测时间都提前了一年。虽然这些预测平台可能已经将推理计算扩展的影响计入其中,但AGI的脚步,似乎正在加快。
威胁模型的改变
过去我们担心AGI一旦出现就能廉价部署数亿个副本,但现实可能并非如此。
要知道,运行一次o3的高性能任务就要花费3000美元!
这意味着恐怖分子即使窃取了前沿模型,也很难筹集足够的资金和基础设施来运行它。就算是国家级别的窃取者,在推理计算范式下,拥有最多芯片和算力的国家也能轻松胜出。
思维链监督:福是祸?
如果模型的思考过程更多地体现在人类可理解的思维链中,而不是内部激活。
这对AI安全来说是个好消息。通过人类监督和可扩展的监督机制,我们能更好地控制AI系统。
但Meta最近的Coconut技术让人担忧——它能让模型在不使用语言的情况下进行连续推理。
虽然这可能提供性能优势,Marius Hobbhahn说到:「为了边际性能提升而牺牲可理解的思维链,这是在搬起石头砸自己的脚。」
强化学习的隐忧
OpenAI公开承认使用强化学习来改进o系列模型的思维链输出。这可能带来一些担忧:
-
通过强化学习优化思维链比优化基础模型更便宜
-
长链思维链的强化学习反馈可能提供更高质量的信号
-
OpenAI可能使用某种「元级控制器」来在不同的「思维树」分支间进行导航
强化学习过度优化是许多AI安全威胁模型的起源,包括「激励权力寻求」。
虽然基于过程的监督看起来比基于结果的监督更安全,但最新研究表明这种组合反而可能降低模型推理的可解释性。
新的安全挑战
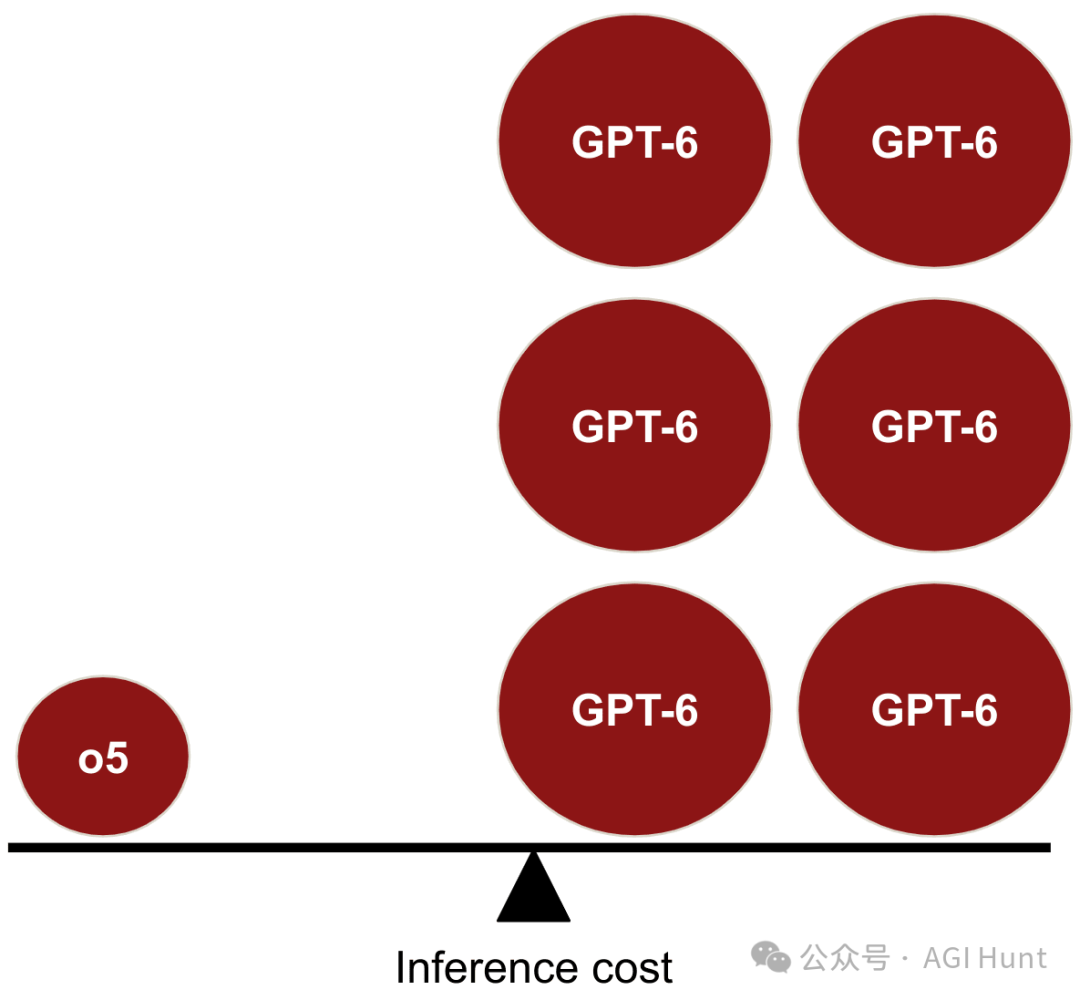
如果第一批AGI(例如o5)采用推理计算范式,它们的参数量可能比传统同等性能的模型(如GPT-6)要小得多。
这意味着:
-
小模型更容易被窃取
-
但由于运行成本高昂,被盗模型的威胁大大降低
-
模型特征可能更密集地嵌入在较小的网络中,增加了解释性的难度
-
芯片专业化带来新的出口管制挑战
AI研发的最后一程,或许,已经开始了。
(文:AGI Hunt)