
2024 年,vLLM 完成了从专业推理引擎到开源 AI 生态系统标配解决方案的蜕变。这一年,项目在各个维度都实现了显著增长:GitHub 星标数从 14,000 增至 32,600,贡献者数量从 190 扩展到 740,月下载量从 6,000 激增至 27,000,近半年的 GPU 使用时长更是增长了约 10 倍。这些数据印证了 vLLM 在AI 基础设施领域的领先地位,已成功为亚马逊 Rufus 和领英等大型产品提供核心支持。
2024 年重要成就
社区建设与生态发展
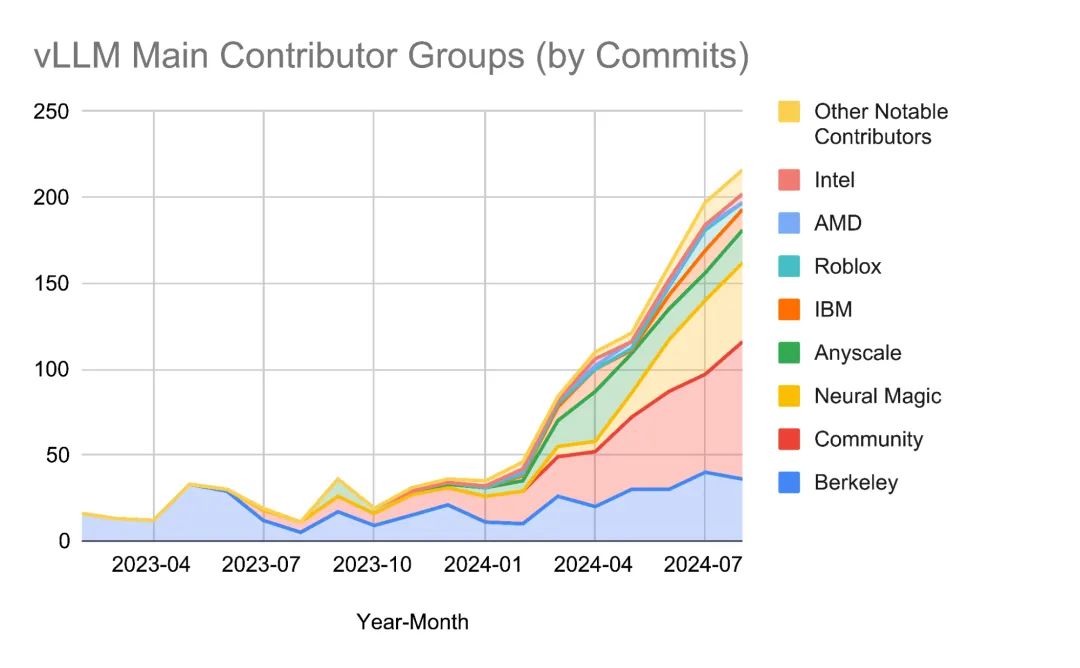
2024 年,vLLM 建立起了一个充满活力的开源社区。目前已有超过 15 位全职贡献者来自 6个以上的组织,20 多家机构作为核心利益相关方和赞助商,包括加州伯克利大学、 Neural Magic 、Anyscale 等顶级机构。双周例会的良好运作促进了社区透明度提升和战略合作的达成。
全面的模型支持
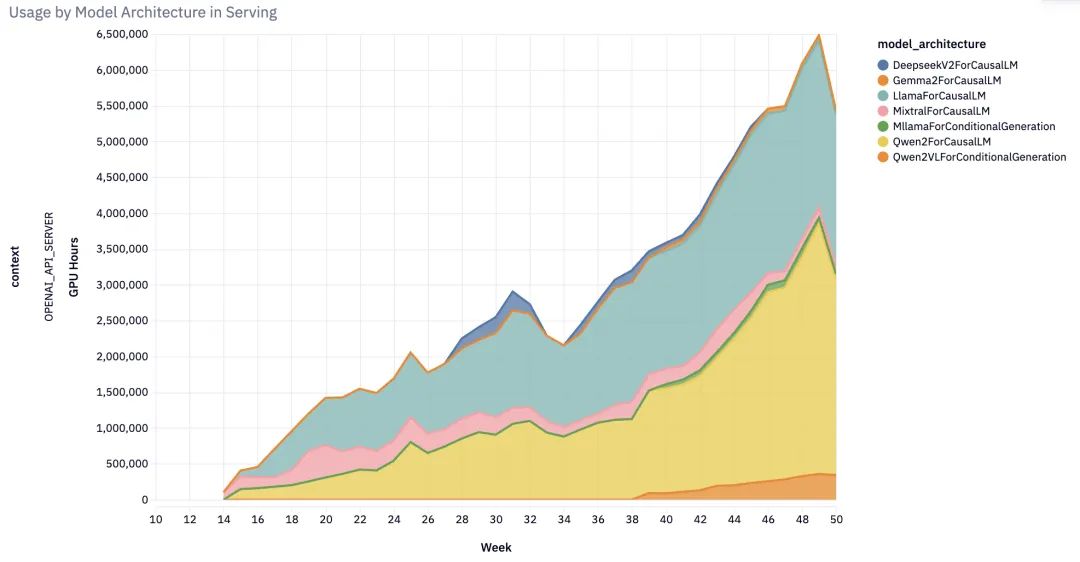
从年初仅支持少数模型,到年末已能支持近 100 种模型架构,覆盖几乎所有主流开源大语言模型、多模态模型(图像、音频、视频)、编码器-解码器模型等。特别值得一提的是,vLLM 开创性地为状态空间语言模型提供了生产级支持。
硬件兼容性突破
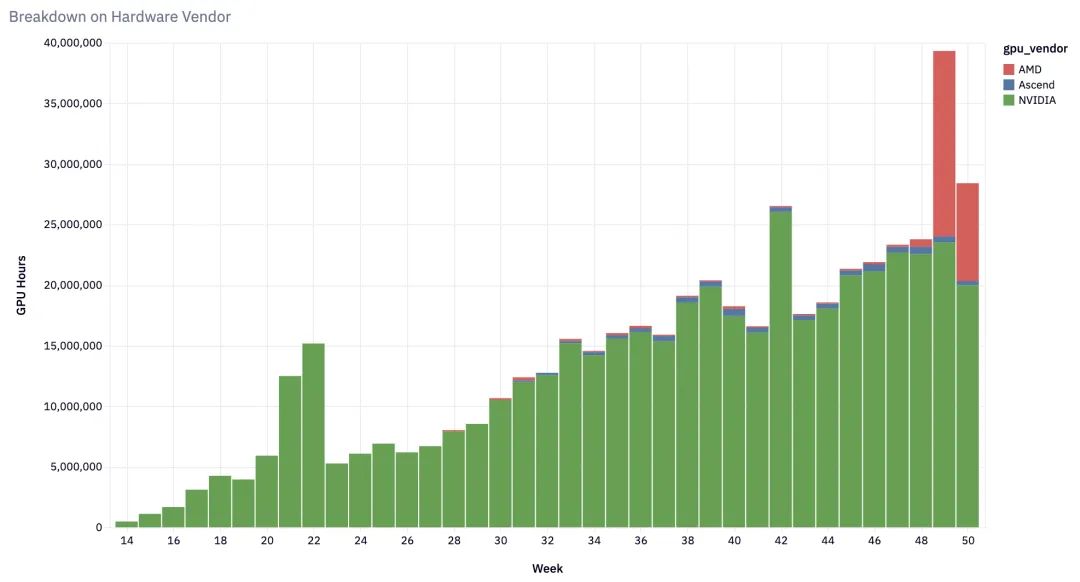
vLLM 实现了对主流 AI 硬件的全面支持:
- NVIDIA 系列:从 V100 到H100 的全系列 GPU
- AMD 产品线:MI200 、MI300 和Radeon RX 7900 系列
- 云服务商硬件:Google TPU 、AWS Inferentia/Trainium
- 其他平台:Intel Gaudi 、多种架构 CPU 等
核心特性持续创新
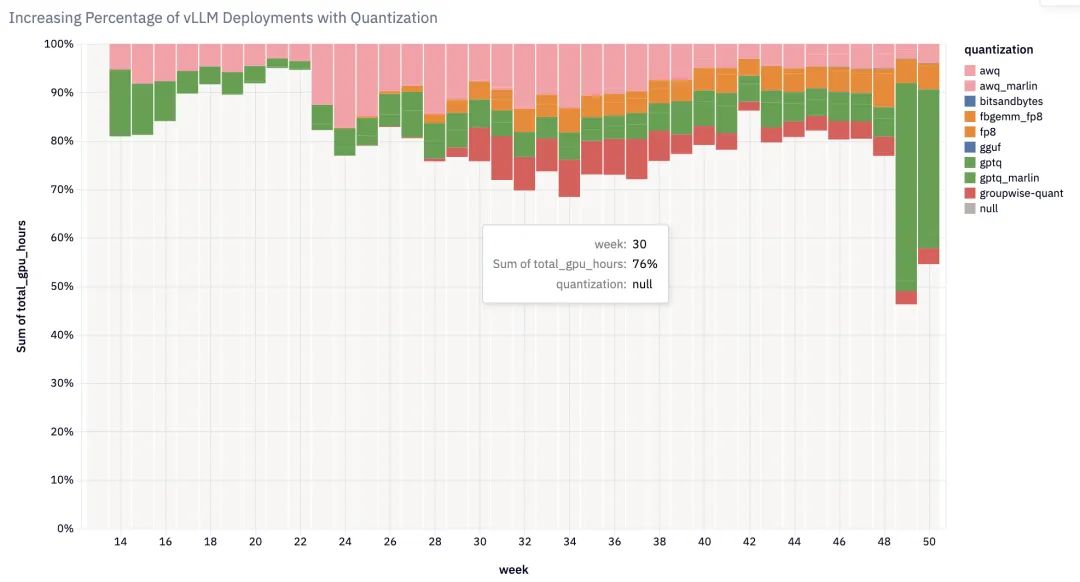
2024 年,vLLM 推出了多项重要功能升级:
- 权重和激活量化:支持多种量化方法,提升推理效率
- 自动前缀缓存:降低上下文处理成本
- 分块预填充:提升交互应用的稳定性
- 推测解码:通过并行预测加速生成
- 结构化输出:支持 JSON 等特定格式输出
- 分布式推理:实现跨 GPU 和节点的工作负载扩展
2025年发展愿景
模型能力升级
2025 年,vLLM 的核心目标是在单个 GPU 上实现 GPT-4 级别的性能,并在单个节点上支持更大规模模型的部署。为此,团队将重点优化以下方面:
- KV 缓存和注意力机制优化
- 混合专家系统(MoE)优化
- 扩展长上下文支持
生产级部署支持扩展
随着 LLM 成为现代应用的核心,vLLM 计划为生产环境提供更完善的支持:
- 量化、缓存等优化功能将成为默认配置
- 提供完整的集群级解决方案
- 针对不同场景优化的部署方案
开放架构
vLLM 将推出全新的 V1 架构,突出开放性和可扩展性:
- 可插拔架构设计
- 一流的 torch.compile 支持
- 灵活的组件系统
小结
大浪淘沙,vLLM成功的在大模型领域竞争中脱颖而出。vLLM 正在从一个简单的推理引擎,发展成为连接模型开发者、硬件供应商和应用开发者的开放平台。同时,vLLM不忘初心,重申使命:构建世界上最快、最容易使用的开源LLM推理和服务引擎。
期待2025年vLLM的表现,同时也希望有更多新的框架和工具诞生,加速AI推理的发展。
原文:https://blog.vllm.ai/2025/01/10/vllm-2024-wrapped-2025-vision.html
(文:AI工程化)
2024年,vLLM完成蜕变!从专业推理引擎到开源AI生态系统的标配解决方案,数据说话:GitHub starring数、贡献者数量、月下载量和GPU使用时长都实现了翻倍。这不愧是行业-leading!2025年目标直接冲GPT-4水平?!
2024年vLLM anus升到神水位!GPU使用量狂增10倍!模型支持拉满, Hardware兼容性也是顶流!2025年目标GPT-4级性能, 🔥🔥🔥