

Datawhale学术
作者:MMNTP Team
介绍一下最近和来自北大,北航,港大,国科大等学校的同学以及阿里, Microsoft, Humanify 等研究机构呕心沥血的综述工作《Next Token Prediction Towards Multimodal Intelligence: A Comprehensive Survey》
Datawhale学术
作者:MMNTP Team
介绍一下最近和来自北大,北航,港大,国科大等学校的同学以及阿里, Microsoft, Humanify 等研究机构呕心沥血的综述工作《Next Token Prediction Towards Multimodal Intelligence: A Comprehensive Survey》

简介
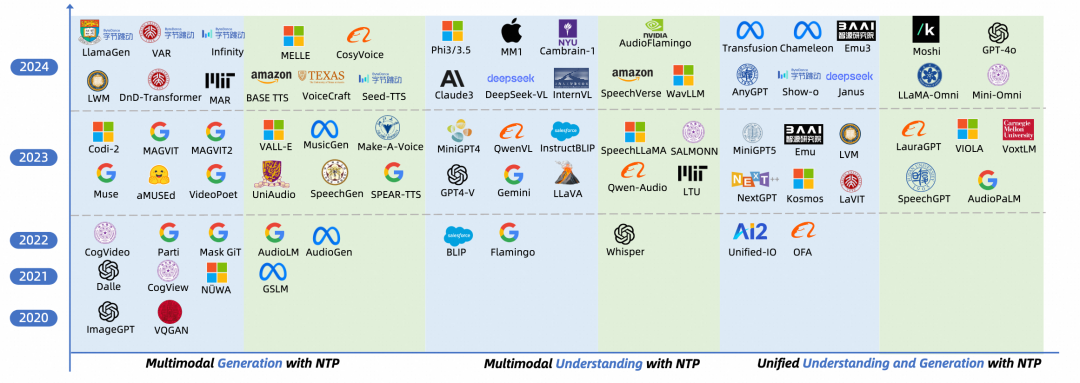

-
多模态的 Tokenization 技术 -
MMNTP 模型架构设计 -
训练方法与推理策略 -
性能评测体系 -
现存挑战与未来方向
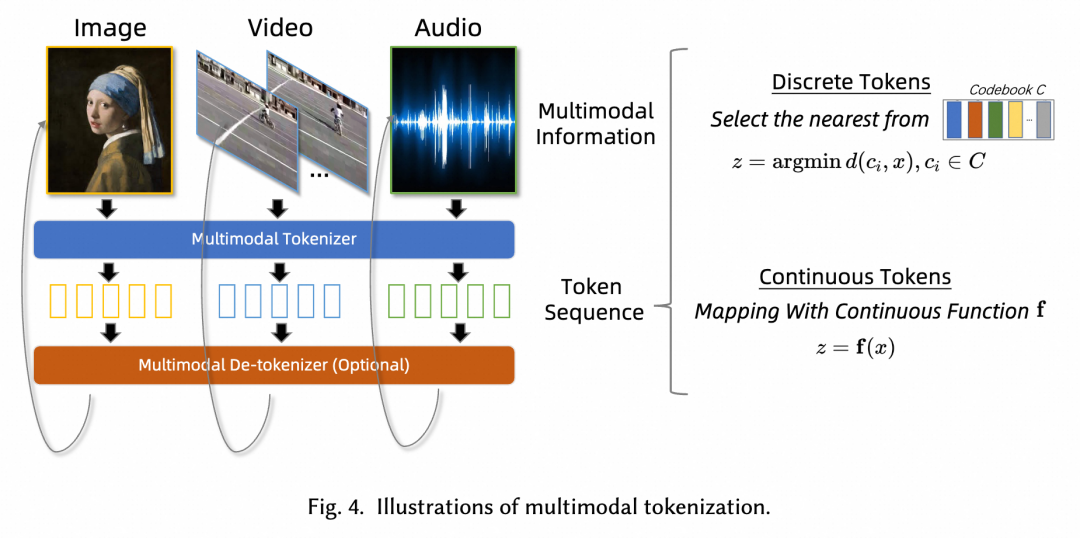
多模态的 Tokenization
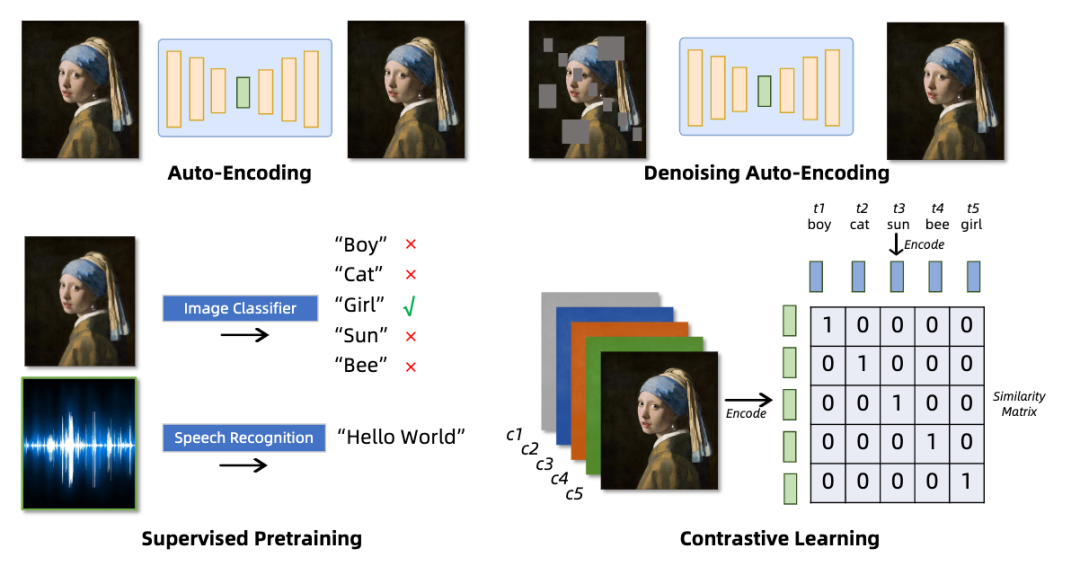
Tokenizer 训练方法
MMNTP 模型
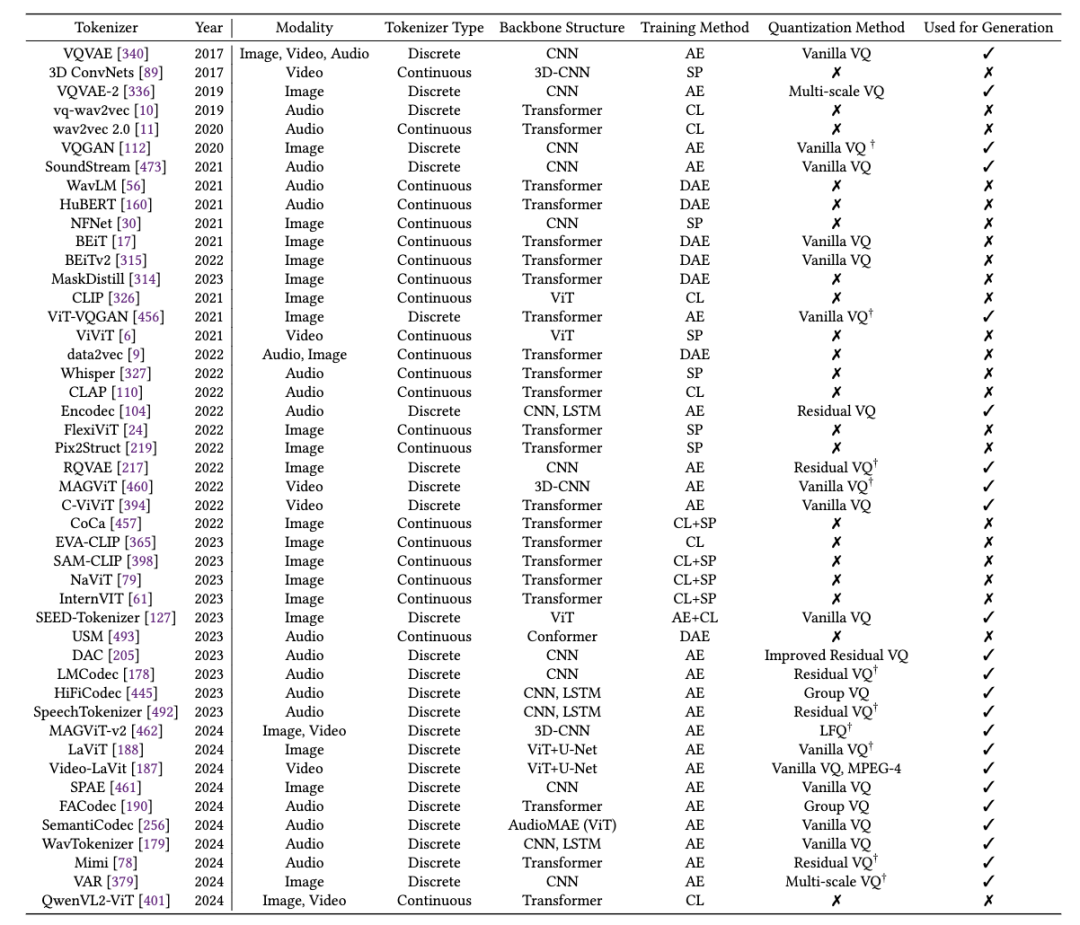
MMNTP 模型一般结构如上图所示,它主要由骨干模型(一般是一个 Transformer 模型),以及不同模态的 Tokenizer 与 De-Tokenizer 组成。Tokenizer 将不同模态的信息转换为 Token 序列,De-Tokenizer 则将 Token 序列转换为原始模态的信息。
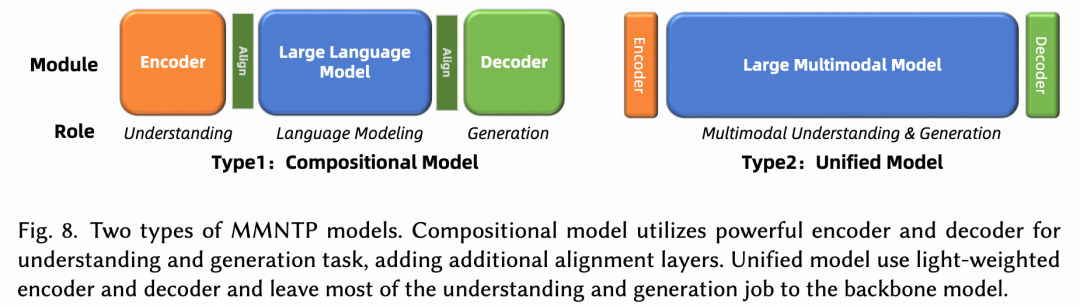
如上图所示,我们将 MMNTP 模型进一步分为两类,组合式(Compositional)和统一(Unified)式。组合模型依赖于强大的外部编码器例如 CLIP 和解码器例如 SD3 来理解和生成多模态信息,而统一模型则使用轻量级的编码器和解码器例如 VQVAE,将大部分理解和生成任务交给骨干模型。本文对这两种模型结构进行了详细讨论,并比较了它们的优缺点。
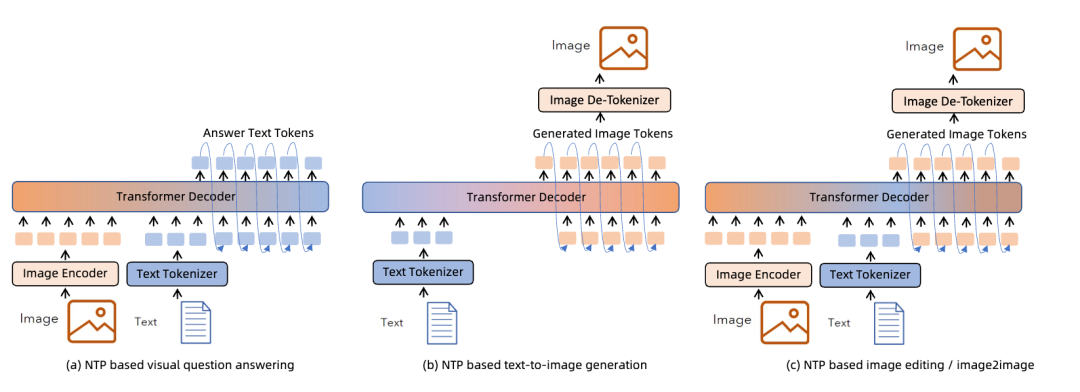
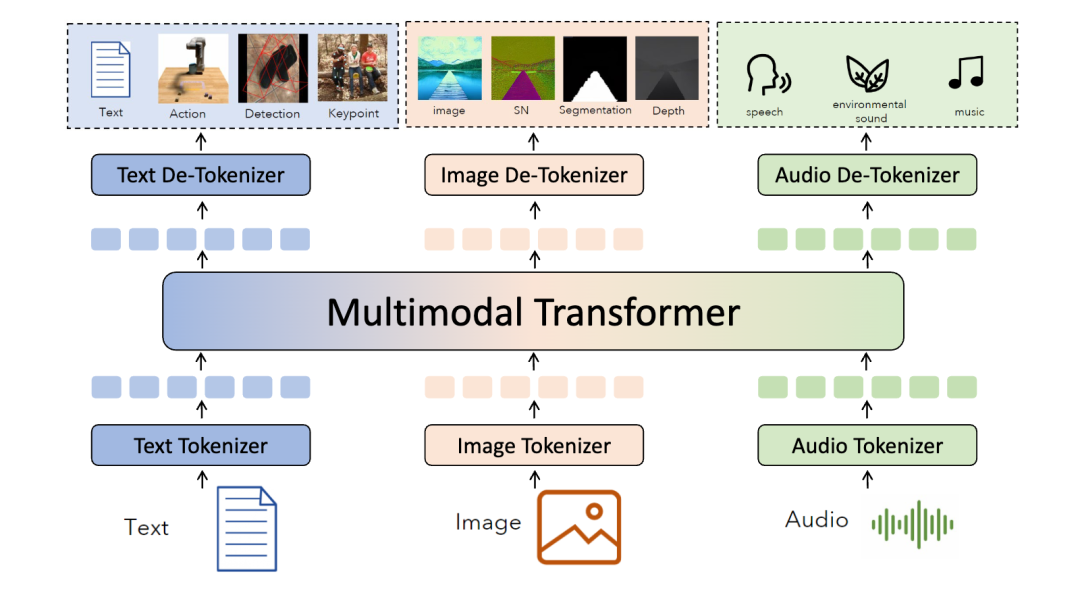
对于不同的多模态任务来说,MMNTP 模型可以以一种统一的方式处理不同任务,区别之处在于不同任务的输入输出不同。上图以图片模态为例子,列出来了同一个 MMNTP 模型结构如何进行图片理解例如 VQA,图片生成,以及基于文字指令的图片编辑任务。只需要替换输入输出的组合形式,同一个模型架构就可以完成不同的任务,这体现了 MMNTP 模型在多模态任务上的统一性。本文针对图片,视频,音频模态的 MMNTP 模型进行了详细的讨论,并根据结构类型进行了梳理,如下表所示。

训练范式
训练任务的类型
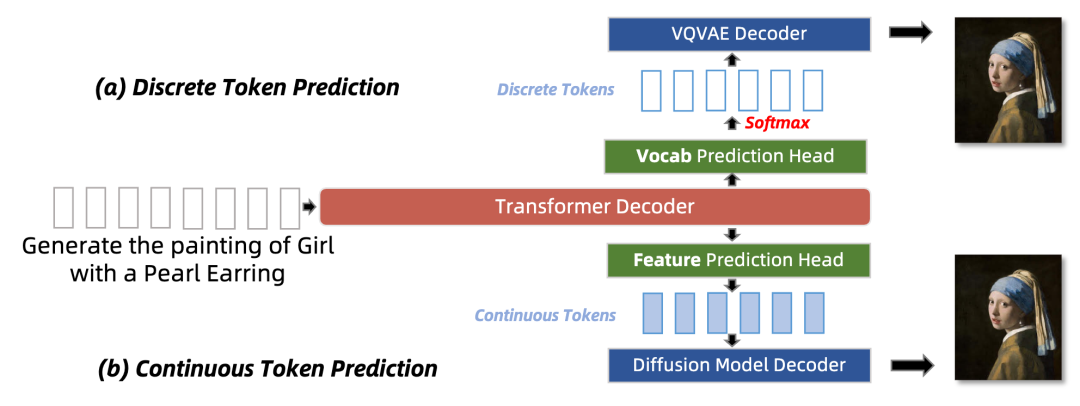
一旦将不同模态的内容转化为序列化的标 Tokens,就可以使用统一的骨 MMNTP 模型来训练,以解决各种理解和生成任务。本文将训练任务按照生成的Token类型不同分为两类,离散 Token 预测和连续 Token 预测。二者的区别在于预测的token是离散的还是连续的,这会对应不同的训练任务,以及特殊的输出头的结构。例如多模态理解任务往往以语言作为输出,则需要使用语言模型头作为输出头,进行离散 Token 预测。如果将 Diffusion 模型和 NTP 模型结合,则需要使用 Diffusion 模型头作为输出头,进行连续 Token 预测。
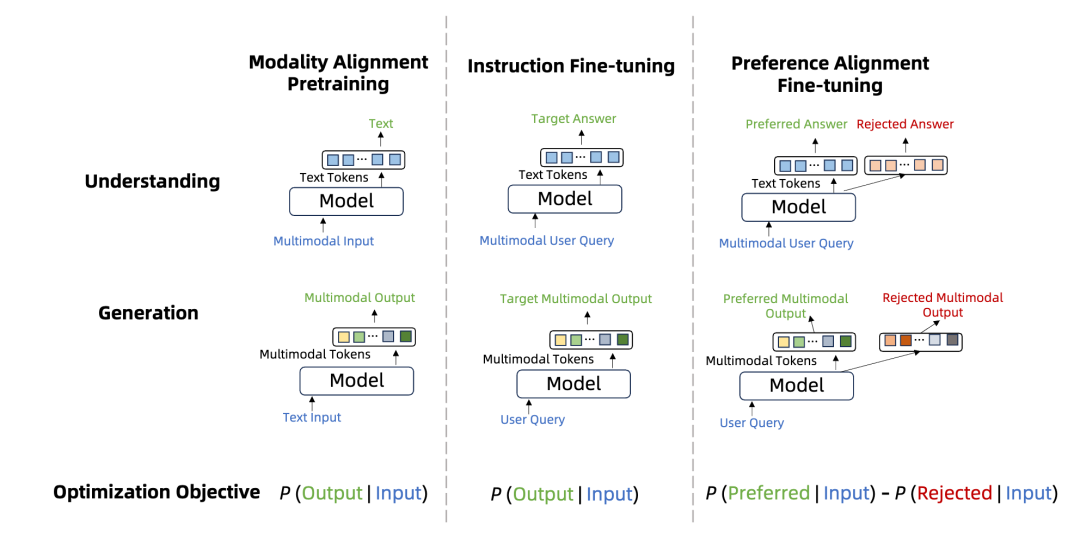
和语言模型类似,MMNTP 模型的训练也可以分为三个阶段,如上图所示,分别是模态对齐预训练,指令微调和偏好学习。这里的预训练阶段,通常指的是在多模态数据-文本对数据上进行预训练,以将不同模态的信息对齐到语言空间。指令微调阶段是针对不同的下游任务,例如理解和生成类任务,用标注好的数据进行训练。偏好学习在 MMNTP 模型中的研究刚刚起步,主要将模型的输出和人类的偏好进行对齐。本文详细这三个阶段的相关研究工作,并根据任务类型进行了归纳整理。
测试时的 Prompt 工程
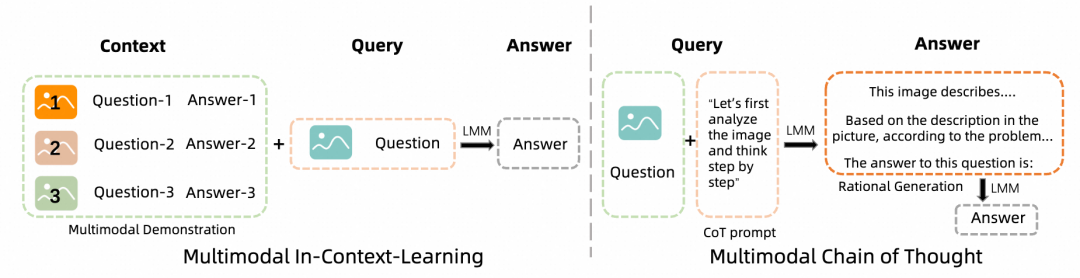
Prompt 工程是提升 LLM 模型效果的重要手段,在 MMNTP 模型中,借助了 LLM 继基座模型的能力,Prompt 工程同样重要。本文对 MMNTP 模型中的 Prompt 工程进行了详细的讨论,如上图所示,分为多模态的上下文学习(Multimodal In-Context Learning)和多模态思维链(Multimodal Chain-of-Thought)两种方法。

如上图所示,多模态的上下文学习指的是在输入中加入多模态任务的例子,以帮助模型更好地理解任务。多模态思维链则是指在输入中加入一些思维链的提示,例如“感知”,“推理过程”等,以促使模型更好地进行多模态推理。我们将这些方法进行整理,如下表所示。
训练数据集与性能评测
存在的挑战
-
如何更好地利用无监督的多模态数据来扩展 MMNTP 模型 -
克服多模态干扰并增强协同作用 -
提高 MMNTP 模型的训练和推理效率 -
将 MMNTP 作为更广阔任务的通用接口。
小结
本文从 NTP 范式的视角出发,全面梳理了多模态领域的最新进展。从 Tokenization 到模型架构,从训练范式到性能评测,我们希望这份工作能为研究者们提供一个清晰的研究全景图。
在 2025 年,随着 MMNTP 技术的不断发展,我们期待看到更多创新性的工作能够突破现有的挑战,推动多模态智能向前发展。欢迎大家引用论文并且:在评论区分享你的想法和见解;如果发现任何问题或有补充建议,欢迎邮件联系我们,我们会在新版本的综述中进行更新;如果觉得这份工作对你有帮助,别忘了给我们的 GitHub 仓库点个 star🌟。

(文:Datawhale)