
检索增强生成(RAG)在开放域问答任务中表现出色。然而,传统搜索引擎可能会检索浅层内容,限制了大型语言模型(LLM)处理复杂、多层次信息的能力。为了解决这个问题,我们引入了WebWalkerQA,一个旨在评估LLM执行网页遍历能力的基准。它评估LLM系统性地遍历网站子页面以获取对应信息的能力。同时我们提出了WebWalker,一个通过explorer-critic范式模拟人类网页导航的multi-agent框架。广泛的实验结果表明,WebWalkerQA具有挑战性,证明了结合WebWalker的RAG在实际场景中通过横向搜索和纵向页面挖掘集成的有效性。
1.WebWalker架构
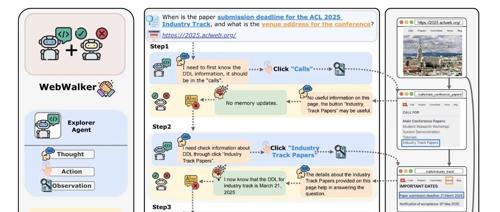
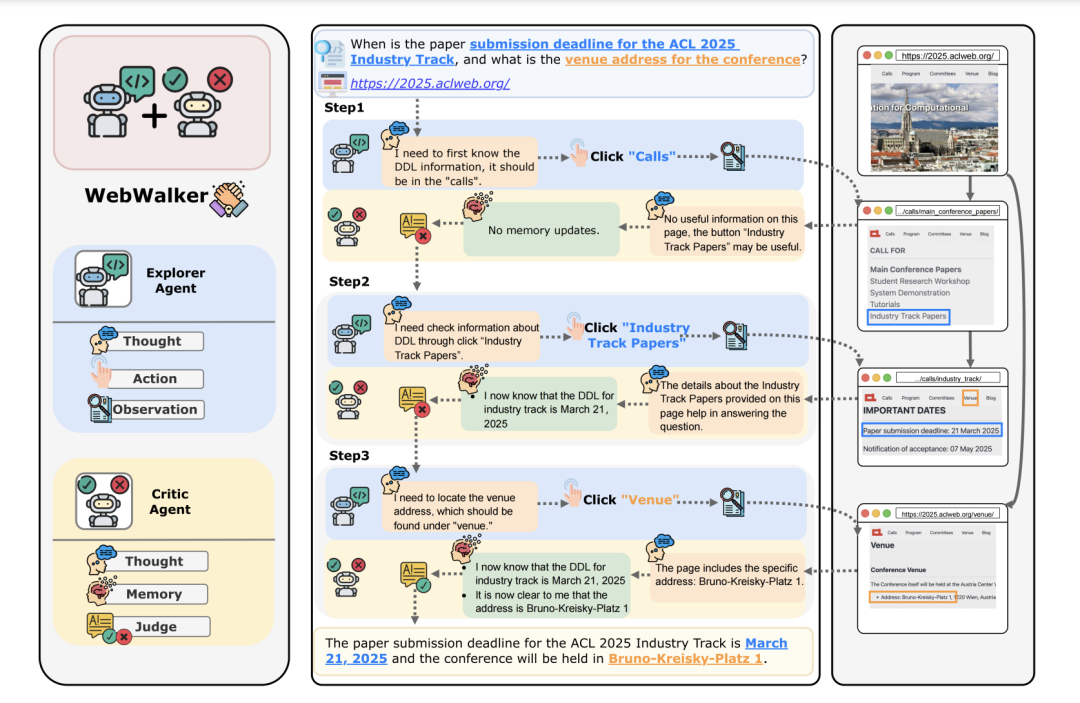 Think then Explore(思考然后探索):探索者代理一步步地在网页环境中进行导航。它与网页互动,重点关注HTML按钮和可点击链接,以决定接下来去哪里。在每个步骤中,代理观察当前页面,包括页面内容和可点击链接的列表。基于这些观察,它选择一个链接进行进一步探索。决策过程考虑了所有先前行动和观察的序列,形成了一种“历史”,帮助引导探索。这个过程持续进行,直到批评者代理认为已经收集到足够的信息或达到预设的探索步骤限制。
Think then Explore(思考然后探索):探索者代理一步步地在网页环境中进行导航。它与网页互动,重点关注HTML按钮和可点击链接,以决定接下来去哪里。在每个步骤中,代理观察当前页面,包括页面内容和可点击链接的列表。基于这些观察,它选择一个链接进行进一步探索。决策过程考虑了所有先前行动和观察的序列,形成了一种“历史”,帮助引导探索。这个过程持续进行,直到批评者代理认为已经收集到足够的信息或达到预设的探索步骤限制。
Think then Critique(思考然后批评):批评者代理介入,评估探索者代理的进展。在每个探索步骤后,批评者评估当前状态,包括查询、最新的页面观察和选择的行动。它维护一个逐步更新的记忆,记录到目前为止收集到的相关信息。批评者决定所收集的信息是否足够回答查询。如果足够,批评者会形成并提供答案。如果不够,探索将继续进行。这个迭代过程确保了探索有目的地进行,专注于收集解决查询所需的信息。
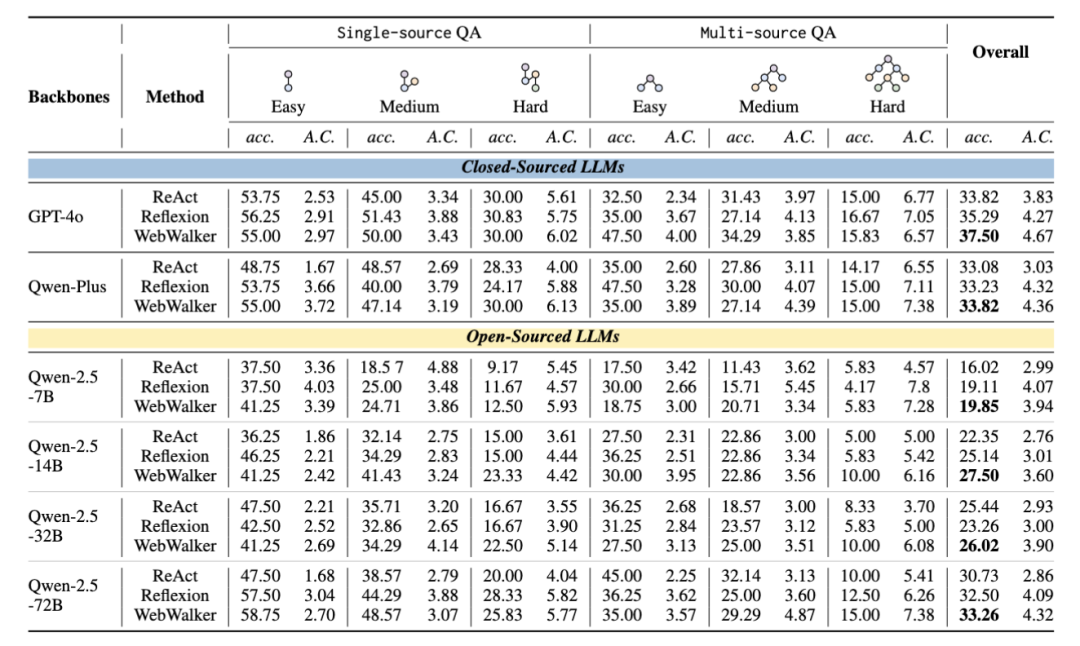
2.Result on Web Agents
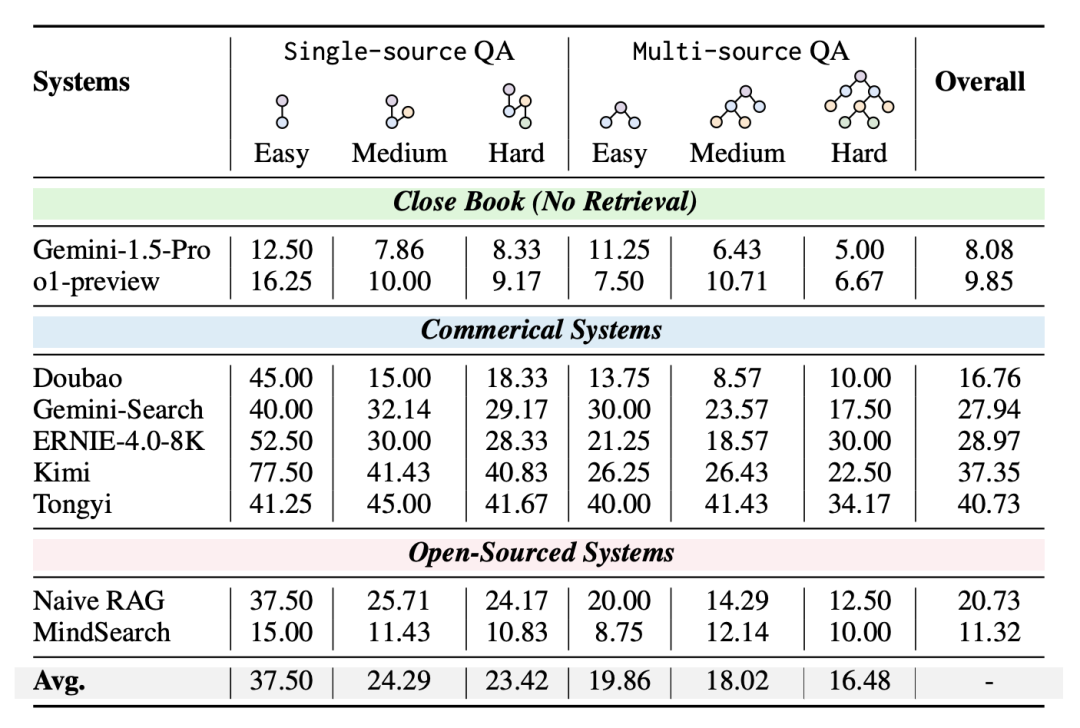
3.Result on RAG-Systems
参考文献:
[1] 论文:https://arxiv.org/pdf/2501.07572
[2] Github:https://github.com/Alibaba-nlp/WebWalker
[3] Homepage: https://alibaba-nlp.github.io/WebWalker/
[4] Demo: https://www.modelscope.cn/studios/iic/WebWalker/
[5] Demo: https://huggingface.co/spaces/callanwu/WebWalker
[6] 主页:https://callanwu.github.io/WebWalker/
(文:NLP工程化)