

极市导读
东北大学贾同团队提出了一种名为AO-DETR的模型,专门针对X-ray图像中违禁品检测的重叠问题进行优化。该模型通过Category-Specific One-to-One Assignment策略和Look Forward Densely 方法,分别解决了前景背景特征耦合和边缘模糊的问题,显著提升了检测精度和稳定性,并在PIXray等数据集上取得了SOTA性能。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
arxiv链接:https://arxiv.org/abs/2403.04309
正式版本链接:https://ieeexplore.ieee.org/document/10746383
开源代码链接:https://github.com/Limingyuan001/AO-DETR-test
参考博客:https://zhuanlan.zhihu.com/p/5403273899
AO-DETR(Anti-Overlapping DETR)模型是一种基于DINO改进的针对X-ray违禁品图像重叠问题的模型。重叠现象带来了两大问题,分别是前景背景特征的耦合以及违禁品边缘模糊。针对这两个问题,这篇论文提出了针对性的解决方法。
一、模型整体介绍
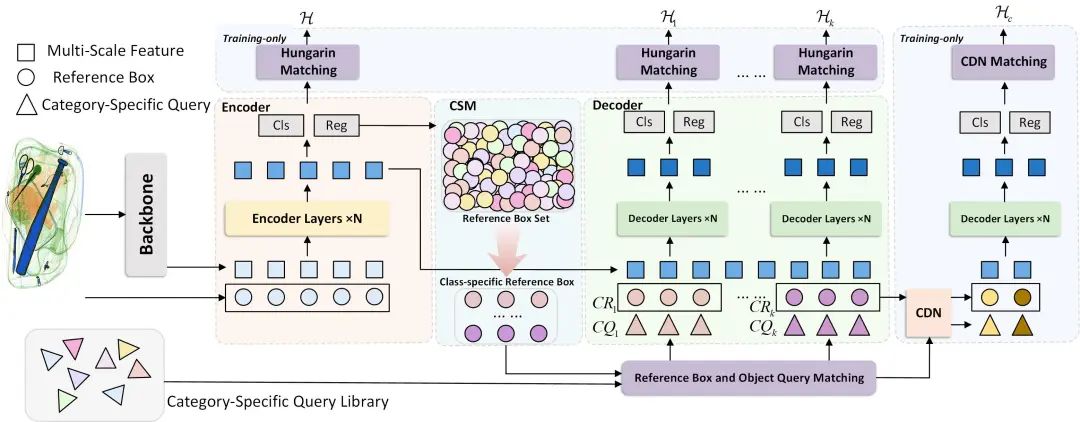
AO-DETR(Anti-Overlapping DETR)模型是一种基于DINO改进的模型。该模型的Backbone、Encoder、Decoder和CDN模块与DINO相同,同时也使用多尺度特征。
该论文的主要创新点如下:
首先在解码器之前(Pre-decoder)添加Category-Specific Oneto-One Assignment (CSA)策略来束缚object queries预测固定类别的违禁品:将从CSM获得的特定于类别的reference boxes与其相应的特定于类别的object queries进行匹配,然后将它们输入到解码器模块进行预测。此处的匹配方法采用了k个类别特定的匈牙利匹配机制来对预测结果和真值进行一对一匹配。该过程用于增强object queries类别的语义稳定度,进而提升模型对重叠的前景背景特征中提取特定类别违禁品特征的能力。
其次在解码器部分,基于DINO解码器中使用的Look Forward Twice (LFT)的方法,该论文进一步提出Look Forward Densely(LFD)方法。针对x-ray图像重叠现象带来的边缘模糊问题,LFD利用当前层预测的偏差对当前层的和更低层的参考框进行修正,压榨低层准确率来提升高层定位准确率。
二、针对问题解决:
1、X-ray图像的重叠现象带来的前景背景特征耦合——CSA策略
CSA策略来限制object queries预测固定类别的违禁品,进而提升其对重叠的前景背景特征中提取特定类别违禁品特征的能力。
CSA策略是将object queries进行分组,使每组queries只能匹配到特定类别的真值标签,这样训练过程中object queries的功能被特异化,专精于从重叠特征中解耦出前景物体信息并进行分类和定位。
具体实现步骤:
①随机初始化一个特定类别的 object queries 库,表示为集合 CQ ,每一个特定类别的 object queries 。对于第 k 个类别,定义了特定类别的 object queries group ,它包含 个相同的 。由于位置编码的存在和不同真值的分配,第 k 个 object queries group 内的每个 object query , i 在训练阶段逐渐发散。具体而言,在训练过程中同一类别内的 object query 会变得相似,而来自不同类别的 object query 变得不同。该过程是为了将 object queries的功能在训练过程中被类别特异化做准备。
②CSM:保持reference boxes和queries的类别一致有助于网络从重叠的背景中提取相关的前景特征,可以增强模型特征提取的抗重叠能力。为了提高queries类别和reference boxes类别之间的一致性。论文提出了一种特定于类别的选择机制Category-Specific Select Mechanism (CSM),该机制提供对应于每个特定类别的object queries group的reference boxes,从而解决了上述类别不一致的问题,具体过程如公式1所示。给定编码器最后一层预测的所有结果 P,类别的数量 k 以及所有类别所需的参考框的数量 N ,该算法可以筛选出每个类别具有最高置信度的前 个预测,表示为 。该过程可以表示如下:
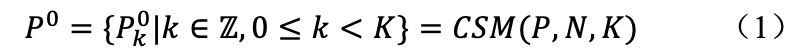
其中 表示所有类别特定的预测结果,包括类别特定的参考框 和类别特定的分类分数
③Reference boxes 和 object queries 匹配:在解码之前,为了对齐 reference boxes 和 object queries 的类别,该论文利用 CSM 选择的 reference boxes 和具有相同类别 k 的 object queries group 之间进行一对一匹配。这样可以得到第 i 对 object queries 和 reference boxes 表示匹配对索引。这种匹配关系确保负责类别 k 物体的 object queries 在整个训练过程中始终稳定地指导负责类别 k 物体的 reference boxes 的预测过程。
为了获得l-th层的类别k中的第i对object queries和reference boxes,即 ,该解码器层的解码过程表示如下:
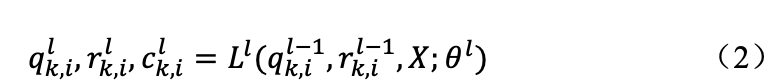
④Category-Specific Hungarian Matching:为了在类别 中有效地建立 ground truth G 和第 1 个解码器层 的预测结果之间的一对一对应关系,我们计算类别特定的匹配代价矩阵。这里, 和 分别表示类别k的预测结果和真值的数量。然后,我们利用匈牙利算法对每个类别进行二分图匹配,过程可以表示如下:
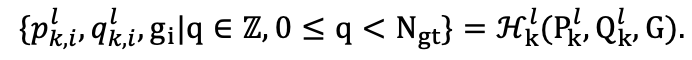
此时,CSA策略在每个类别k中的reference boxes、classification scores、object queries和ground truth之间建立配对。
2、X-ray图像重叠现象导致的边缘不清晰——LFD 方法
LFD 方法,通过提升中高level的decoder层的reference boxes的定位准确程度来提升最终层对于模糊边缘的定位能力。
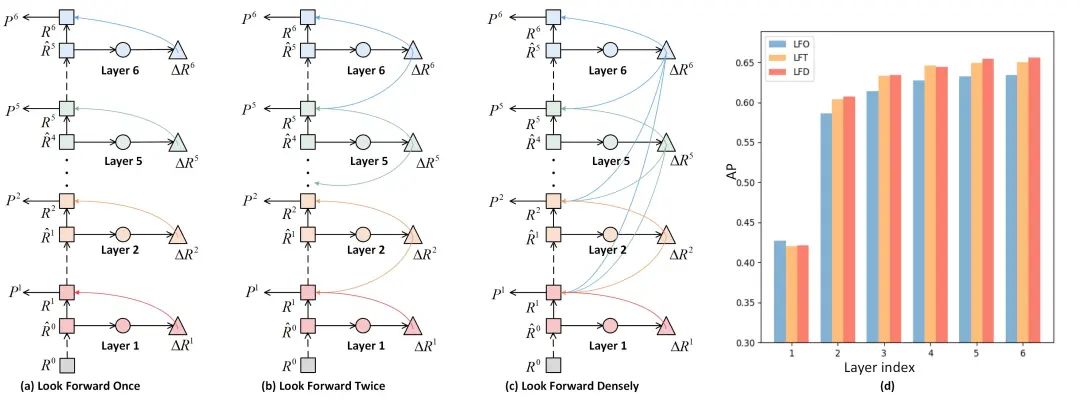
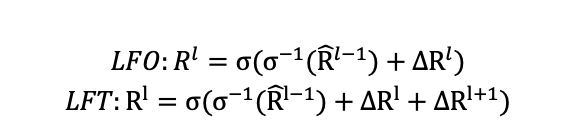
对比Deformable DETR中的解码器对于定位任务使用的Look Forward Once (LFO)方案,和DINO的解码器中使用的Look Forward Twice (LFT)方案,LFD方案更加倾向于牺牲前一层的定位结果改善当前层的定位结果。

相较于LFO而言,在LFT策略下,当前层的定位结果受到一个较高层的负面影响,同时受到一个较低层的正面影响。从整体上看,最底层只受到负面影响,而最高层只受到正面引导,中间层同时受到积极和消极的影响。由于来自较高层的偏移通常较小,对于特定一层,来自较高层的负引导倾向于弱于来自当前层的正引导。结果,低层受损,中层略微受益,高层收益显著。
而针对X-ray图像重叠现象导致的边缘不清晰的问题,为了使图像物体边缘精确回归,论文提出了LFD方法:使当前层预测的偏移参与所有较低层的参考框的预测。对比LFT方法,最低层受到其他所有层的负面影响,最高层受到其他所有层的正面引导。中间层比LFT获得更多的好处。其结果是,与LFT相比,下层受损更大,中层受益更大,上层收益更大。这使得最终层的定位更加精确,有效地抵消了由边缘模糊引起的不准确性,使边缘精确回归。
论文中还进一步探索了几何缩放来自不同层的偏移的影响,通过以成比例的方式放大或缩小来自不同层的偏移,代码中可以找到对应文件。
3、提出评估模型标签分配稳定程度的评价指标
为了深入理解Deformable DETR系列模型中object queries的作用机理,文章设计了一个全新的标签分配稳定度的评价指标。
匈牙利匹配算法利用代价矩阵的全局最优解进行标签分配。但是,在训练期间,由于模型参数更新,每个epoch下相同图像的代价矩阵并不一致,因此同一个object query可能在不同epoch被分配给不同的真值物体。这种可变性导致了object queries标签分配的不稳定性,为了定量评估前景标签分配的不稳定性,文章设计了一个名为前景不稳定性分数(FIS)的度量:
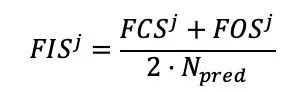
FCS和FOS分别是前景类别不稳定和前景个体不稳定的个数。
对于一个训练图像,模型的解码器预测物体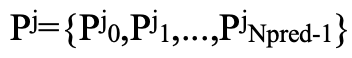 ,其中 表示预测物体的数量,真实物体表示为
,其中 表示预测物体的数量,真实物体表示为 ,其中 表示真实物体的数量。
,其中 表示真实物体的数量。
在标签分配之后,计算索引向量 以存储 epoch j 的的 个 object queries 预测的结果匹配到的个体索引。如下所示:
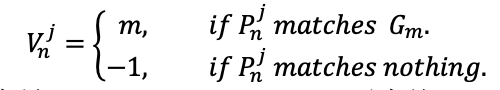
类似地,计算索引向量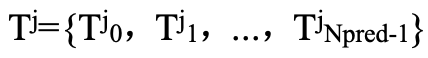 以存储 epoch j 的 个object queries预测的结果匹配到的类别索引。如下所示:
以存储 epoch j 的 个object queries预测的结果匹配到的类别索引。如下所示:

将训练的epoch j的前景类别不稳定性表示为 和 之间的差异,公式如下所示:
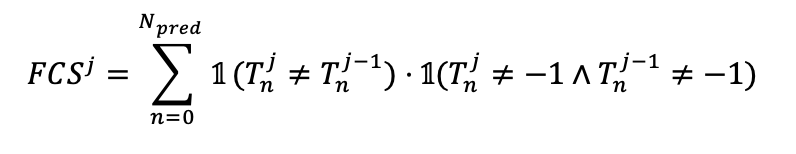
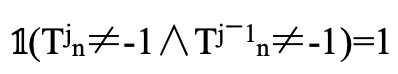 表示和
表示和![]() 都负责前景对象。
都负责前景对象。
类似地,将epoch j的前景对象个体不稳定性定义为其 和 ,之间的差,如下所示:

最后,我们取两者的平均值,并通过预测对象的数量Npred对其进行归一化。
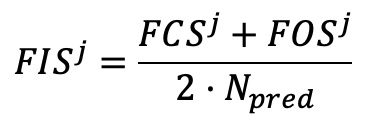
整个数据集的epoch j的不稳定性在所有图像的不稳定性数上平均。FIS综合考虑了前景类别分配和对象分配的不稳定性,FIS值越低,object queries和前景对象之间的标签分配越稳定。
三、实验结果
1、评估模型性能
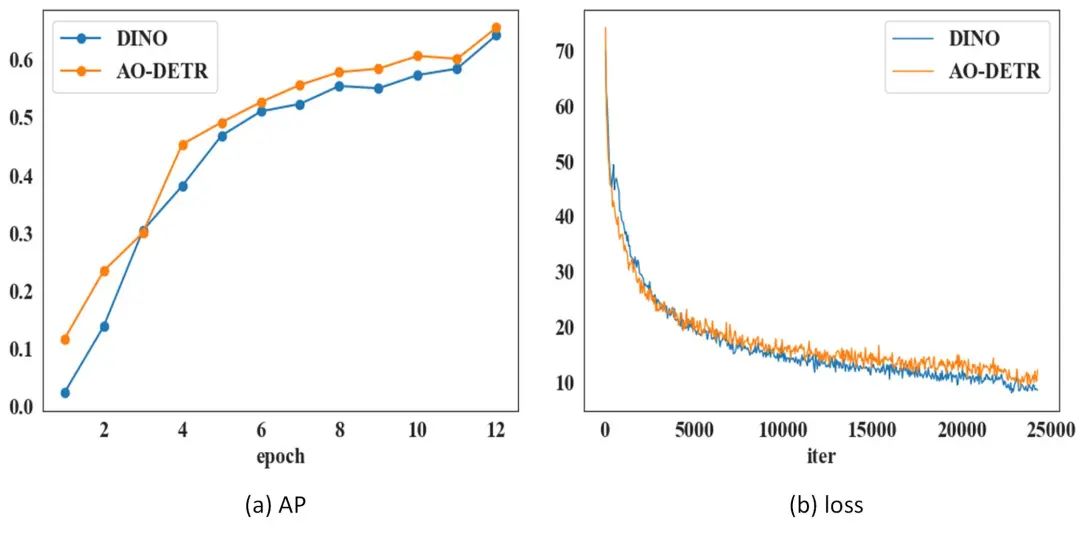
实验使用PIXray数据集,利用COCO评估指标:平均精度(AP)。对比DINO模型与AO-DETR模型对于X-ray图像的检测精度。图中可以看出,AO-DETR模型精度高于DINO。
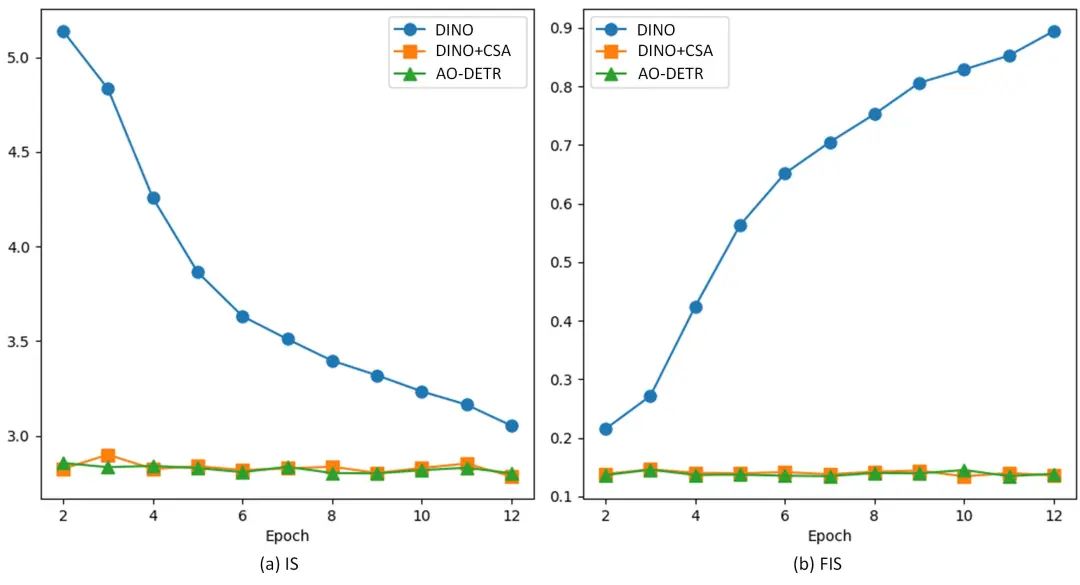
实验使用PIXray数据集,使用论文中提出的评价指标FIS,检测各个模型针对标签分配匹配不稳定问题的解决。图中可以看出,AO-DETR模型的标签分配稳定性更高。
2、可视化结果
①采样点可视化分析
在最后一个解码器层中可变形注意力采样点和相应类别特定对象查询的参考点的可视化。每个采样点都被描绘成一个实心圆,其颜色反映了其相应的注意力权重。参考点由绿色十字标记表示。置信度分数超过阈值的预测边界框已经用类别特定的颜色显示。
②检测结果可视化分析
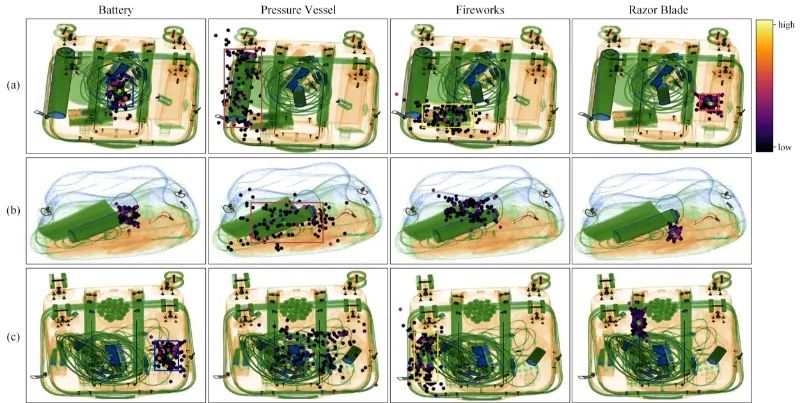
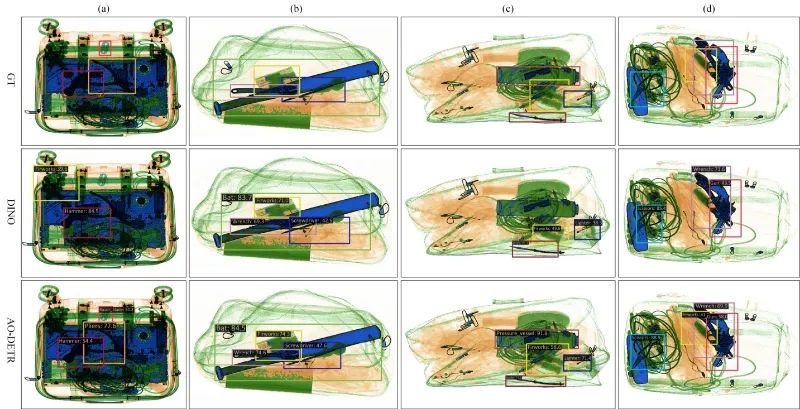
在PIXray数据集上比较AO-DETR和DINO之间的X射线违禁物品检测结果。行“GT”表示具有重叠现象的四个典型X射线违禁物品图像,每个图像具有注释的地面真实框。行“DINO”和“AO-DETR”对应于它们各自的检测结果。为了达到最佳的显示效果,我们对地面真实框和预测框之间的颜色和类别关系进行了标准化。例如,黄色方框表示烟花,而鲜红色方框表示刀片。
3、对比实验
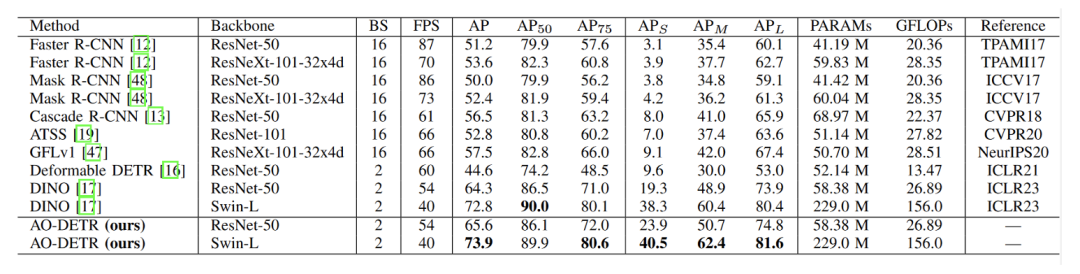
在PIXray数据集上将AO-DETR方法最先进的通用探测器进行比较。BS、PARAMS、GFLOPS和FPS分别表示批量大小、参数总数、千兆浮点运算以及模型每秒可以执行的推断数。可以看到AO-DETR方法取得SOTA结果。
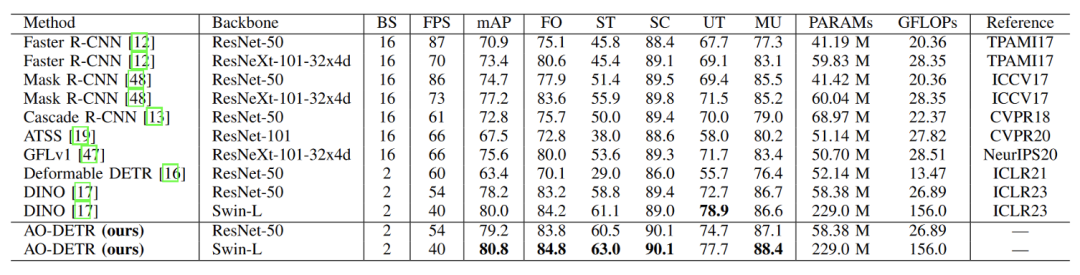
在OPIXRAY数据集上将AO-DETR方法与最先进的通用探测器的比较。FO、ST、SC、UT和MU分别代表漏检率、灵敏度、特异性、模型对预测结果的不确定性和所有预测结果的不确定性的平均值。可以看到AO-DETR方法取得sota结果。
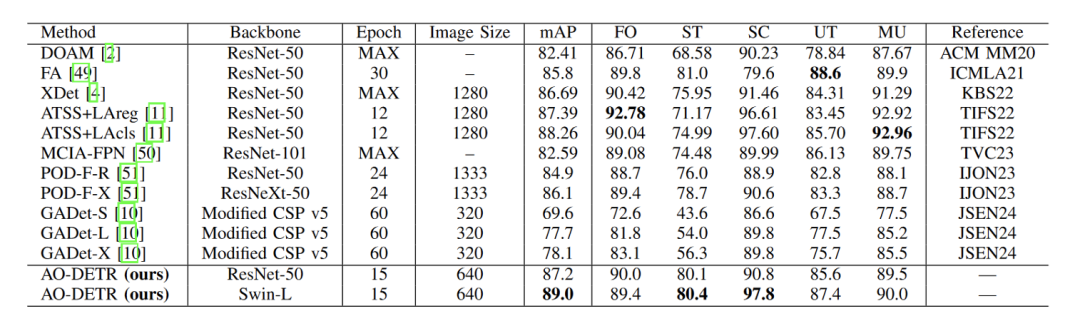
在OPIXRAY数据集上将AO-DETR方法与最先进的违禁物品探测器的比较。MAX表示训练到不再收敛的模型。

(文:极市干货)
这个AO-DETR模型真是强!针对X-ray违禁品检测的重叠问题,终于找到了好办法。支持作者的研究,未来肯定还有很多创新!