
书生·万象 (InternVL) 多模态大模型迎来“迷你版”。
近日,上海人工智能实验室 (上海 AI 实验室) 与清华大学等联合团队推出 Mini-InternVL 多模态大模型,包括 1B、2B 和 4B 三个参数版本,满足不同需求层级。评测结果显示,Mini-InternVL-4B 仅以 5% 的参数量,即实现了 InternVL2-76B 约九成性能,显著减少计算成本。
为适应多领域任务,联合团队提出了简单有效的迁移学习框架,使模型知识“一键”域迁移。同时,研究人员对模型架构、数据格式和训练计划进行了标准化处理,增强了模型在特定场景中的视觉理解和推理能力。
自首次发布以来,书生·万象历经多次迭代,在业界广受好评,全系模型在 Hugging Face 平台下载量已突破 400 万,GitHub 星标数超 6800。相关论文入选 CVPR Oral,并被 Paper Digest 评为 CVPR 2024 年度最具影响力论文之一。
代码仓库地址:
https://github.com/OpenGVLab/InternVL
迁移模型权重:
https://hf.co/collections/OpenGVLab/internvl-adaptation-67542cc9558812823a0281cc
论文链接:
https://link.springer.com/article/10.1007/s44267-024-00067-6
专刊网址:
https://link.springer.com/journal/44267
当前,多模态大语言模型 (MLLMs) 在多类型任务上表现出优异性能,但因庞大的参数规模和高额计算成本,限制了其在消费级 GPU 等低门槛设备上的应用。轻量级多模态大模型方案平衡了参数规模与性能,降低了对高端计算设备的依赖,为促进多种下游应用的发展带来可能。
然而,现有的轻量级方案同样面临视觉编码器覆盖领域有限、标准化框架缺乏等挑战,模型知识难以迁移适用。为此,上海 AI 实验室联合团队基于在多模态大模型研究的技术积淀,提出 Mini-InternVL,让模型“小而美”。
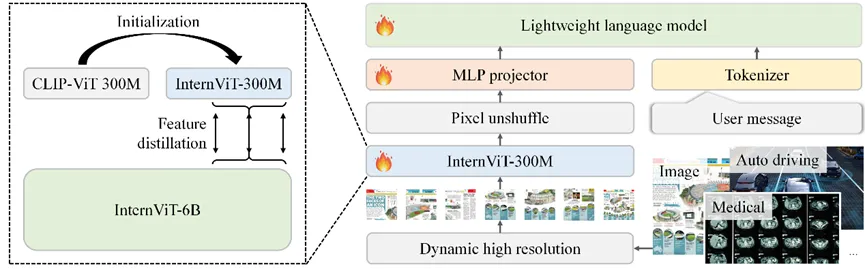
Mini-InternVL 的模型结构由视觉编码器、MLP 连接层和大语言模型 (LLMs) 三部分组成。为了增强轻量级视觉编码器的表征能力,研究人员使用 CLIP 初始化一个 300M 的视觉编码器,并采用 InternViT-6B 作为“教师模型”进行知识蒸馏,开发了新的视觉编码器 InternViT-300M,并将其与不同的预训练 LLMs 连接,最终构建出 Mini-InternVL。
Mini-InternVL 结构和 InternViT 训练方法
模型采用动态分辨率输入和 Pixel Unshuffle 操作方法,使分辨率为 448×448 的图像可表示为 256 个视觉标记,支持处理最多 40 个图像切片。
-
语言-图像对齐,使用多种任务的数据集进行预训练,确保模型能够处理不同的语言和视觉元素。
-
视觉指令调优,选择特定数据集微调模型,提升其在多模态任务中的表现,并教会模型遵循用户指令。
目前,主流多模态大模型采用在大规模图像-文本配对数据上训练的视觉编码器,如 CLIP 等,以获得其视觉表示。然而,这些编码器普遍缺乏对视觉世界的全面理解,需要通过与大语言模型的生成预训练进行迭代学习。
与其他通过辅助路径增强视觉基础模型的方法不同,联合团队直接使用了一个经过生成训练的强大视觉模型,将其预训练知识迁移到一个轻量级的视觉模型上。研究人员使用视觉编码器 InternViT-6B 作为“教师模型”,并用 CLIP-ViT-L-336px 初始化“学生模型”的权重。通过计算最后K层变换器隐藏状态之间的负余弦相似度损失,对齐“学生模型”和“教师模型”的表征,构建出新的视觉编码器 InternViT-300M。
研究人员从多个公开资源中精选自然图像、OCR 图像、图表和多学科图像数据集,所有图像的分辨率都被调整为 448×448,为提高训练效率,而未使用动态分辨率。最终,InternViT-300M 以 1/20 的参数量,继承了 InternViT-6B 蕴含的预训练知识,以轻体量适配各类大语言模型。
由于模型设计、数据格式和训练策略的差异,导致多模态大模型之间存在显著异质性。为此,研究人员推出了一个简单有效的迁移学习框架,实现模型设计、数据格式和训练策略的标准化,减少训练数据需求和计算资源成本。
其中指令调优是训练的关键阶段,如下图所示,在数据格式方面,通过将训练数据格式化为视觉问答 (VQA) 和对话格式,提升模型遵循用户指令的能力。对于其他传统任务,例如图像分类任务,视觉定位任务,区域感知任务和多视角图像和视频帧的理解,此前的多格式内容均被统一单独格式化为 VQA 格式。
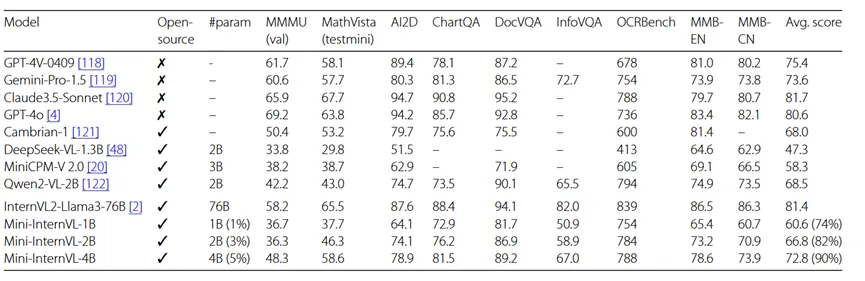
通用基准测试
Mini-InternVL 在多个基准测试中表现优异。最小版本模型仅包含 10 亿参数,但其性能与 20 亿参数的同类型模型相当。与其他轻量级模型相比,Mini-InternVL-4B 在大多数基准测试中表现出色,在 MMbench、ChartQA、DocVQA 和 MathVista 等任务上,其表现接近主流商业模型。值得注意的是,Mini-InternVL 仅使用 5% 的参数,便实现了 InternVL2-Llama3-76B 约 90% 的性能表现。
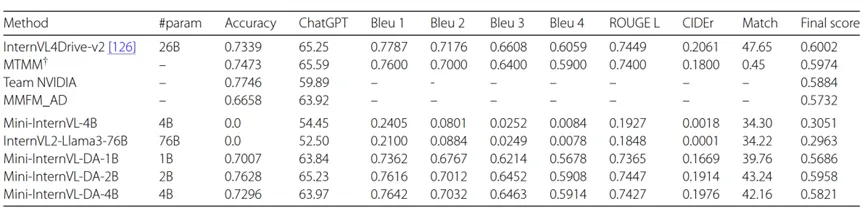
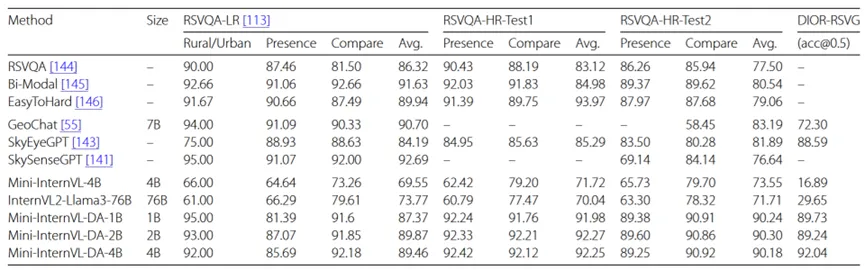
域迁移的结果
研究人员分别针对多视角自动驾驶,具有时间信息的自动驾驶,医学图片感知和遥感图像感知四个垂类领域进行了域迁移。
迁移模型在 BDD-X 数据的控制信号预测任务上的表现
迁移模型在遥感图像基准 RSVQA 和 DIOR-RSVG 上的表现
本文由 Hugging Face 中文社区内容共建项目提供,稿件由社区成员投稿,经授权发布于 Hugging Face 公众号。文章内容不代表官方立场,文中介绍的产品和服务等均不构成投资建议。了解更多请关注公众号:
如果你有与开源 AI、Hugging Face 相关的技术和实践分享内容,以及最新的开源 AI 项目发布,希望通过我们分享给更多 AI 从业者和开发者们,请通过下面的链接投稿与我们取得联系:
https://hf.link/tougao
(文:Hugging Face)





迷你版大模型性能惊人!5%参数下接近90%性能。