

Qwen2.5-VL,对比此前发布的 Qwen2-VL 实现了巨大的飞跃。包含三个尺寸 3B、7B 和 72B ,均已开源。
Qwen2.5-VL 的主要特点如下所示:
-
感知更丰富的世界:Qwen2.5-VL 不仅擅长识别常见物体,如花、鸟、鱼和昆虫,还能够分析图像中的文本、图表、图标、图形和布局。
-
Agent:Qwen2.5-VL 直接作为一个视觉 Agent,可以推理并动态地使用工具,初步具备了使用电脑和使用手机的能力。
-
理解长视频和捕捉事件:Qwen2.5-VL 能够理解超过 1 小时的视频,并且这次它具备了通过精准定位相关视频片段来捕捉事件的新能力。
-
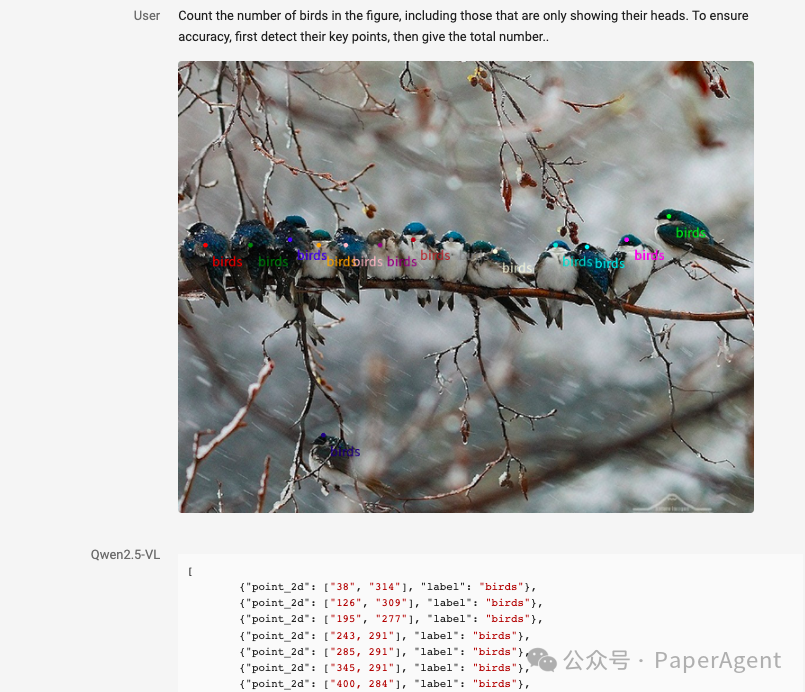
视觉定位:Qwen2.5-VL 可以通过生成 bounding boxes 或者 points 来准确定位图像中的物体,并能够为坐标和属性提供稳定的 JSON 输出。
-
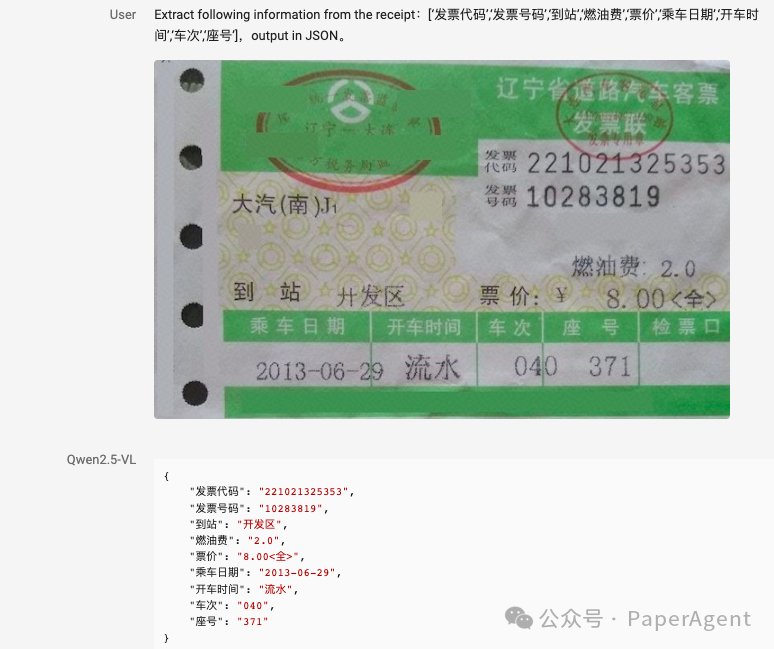
结构化输出:对于发票、表单、表格等数据,Qwen2.5-VL 支持其内容的结构化输出,惠及金融、商业等领域的应用。
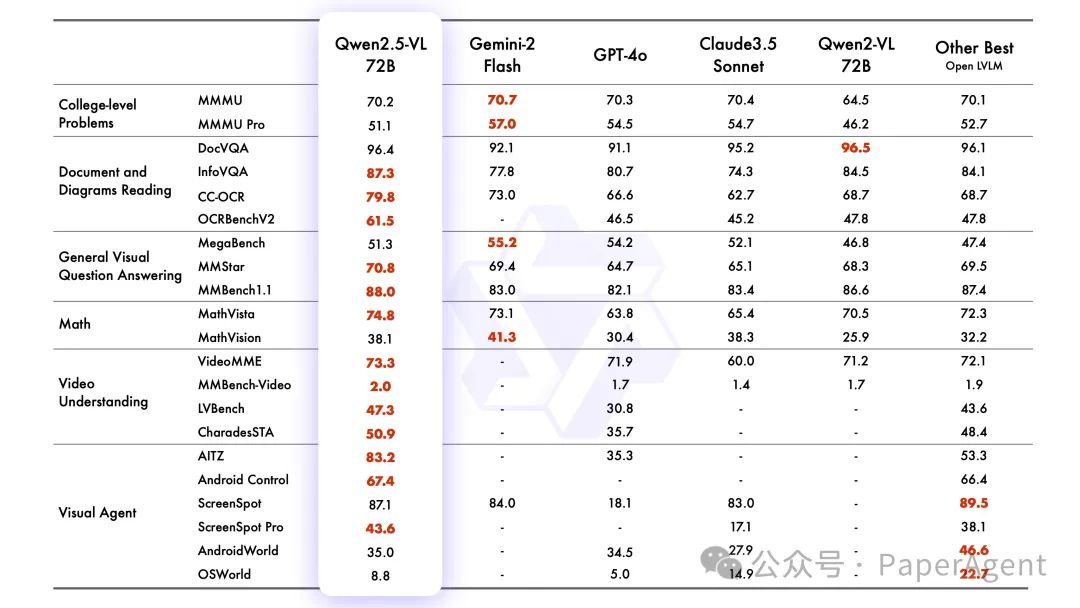
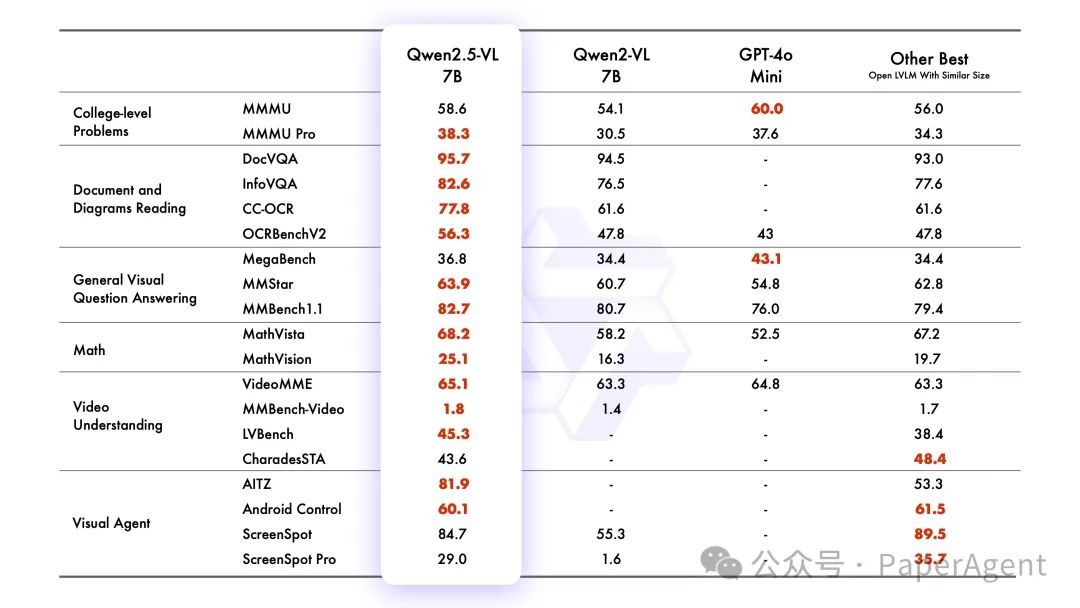
Qwen2.5-VL-72B-Instruct 的测试中,它在一系列涵盖多个领域和任务的基准测试中表现出色,包括大学水平的问题、数学、文档理解、视觉问答、视频理解和视觉 Agent。值得注意的是,Qwen2.5-VL 在理解文档和图表方面具有显著优势,并且能够作为视觉 Agent 进行操作,而无需特定任务的微调。
精准的视觉定位
全面的文字识别和理解
Qwen2.5-VL 将 OCR 识别能力提升至一个新的水平,增强了多场景、多语言和多方向的文本识别和文本定位能力。同时,在信息抽取能力上进行大幅度增强,以满足日益增长的资质审核、金融商务等数字化、智能化需求
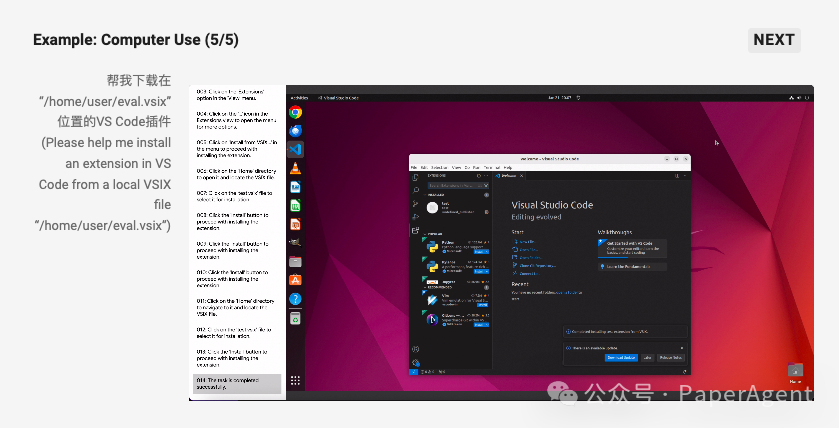
能够操作电脑和手机的视觉 Agent
通过利用内在的感知、解析和推理能力,Qwen2.5-VL 展现出了不错的设备操作能力。这包括在手机、网络平台和电脑上执行任务,为创建真正的视觉代理提供了有价值的参考点。
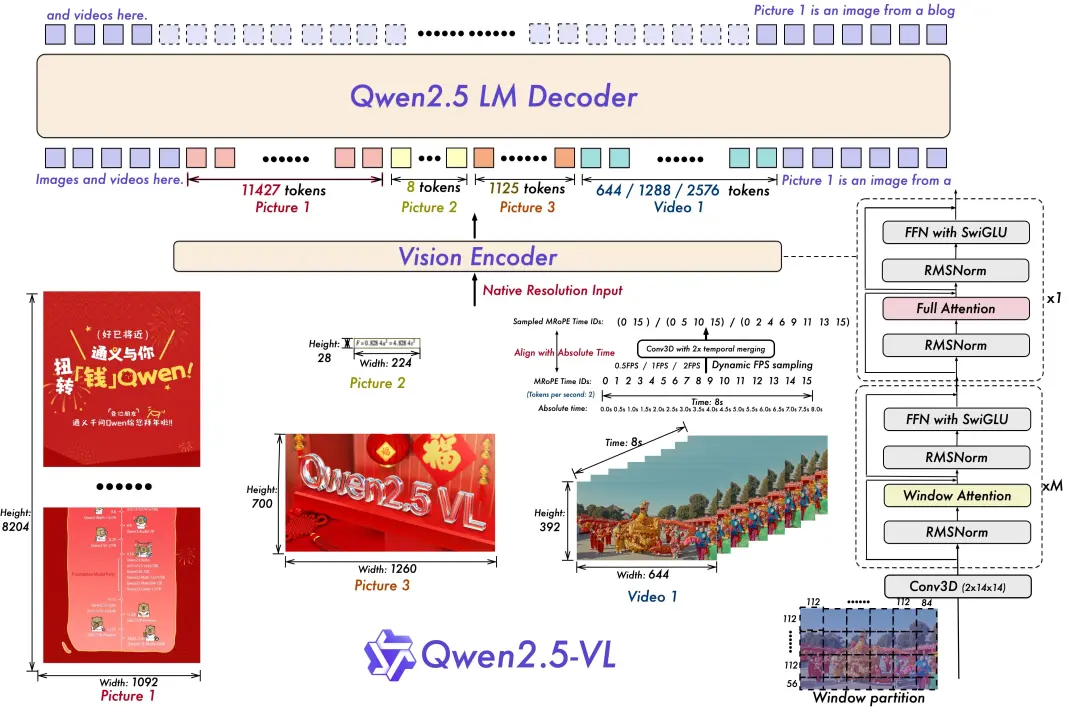
模型架构
与 Qwen2-VL 相比,Qwen2.5-VL 增强了模型对时间和空间尺度的感知能力,并进一步简化了网络结构以提高模型效率。
https://qwenlm.github.io/zh/blog/qwen2.5-vl/https://github.com/QwenLM/Qwen2.5-VL
(文:PaperAgent)