跳至内容
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
王家豪,香港大学计算机系二年级博士,导师为罗平教授,研究方向为神经网络轻量化。硕士毕业于清华大学自动化系,已在 NeurIPS、CVPR 等顶级会议上发表了数篇论文。
太长不看版:香港大学联合上海人工智能实验室,华为诺亚方舟实验室提出高效扩散模型 LiT:探索了扩散模型中极简线性注意力的架构设计和训练策略。LiT-0.6B 可以在断网状态,离线部署在 Windows 笔记本电脑上,遵循用户指令快速生成 1K 分辨率逼真图片。
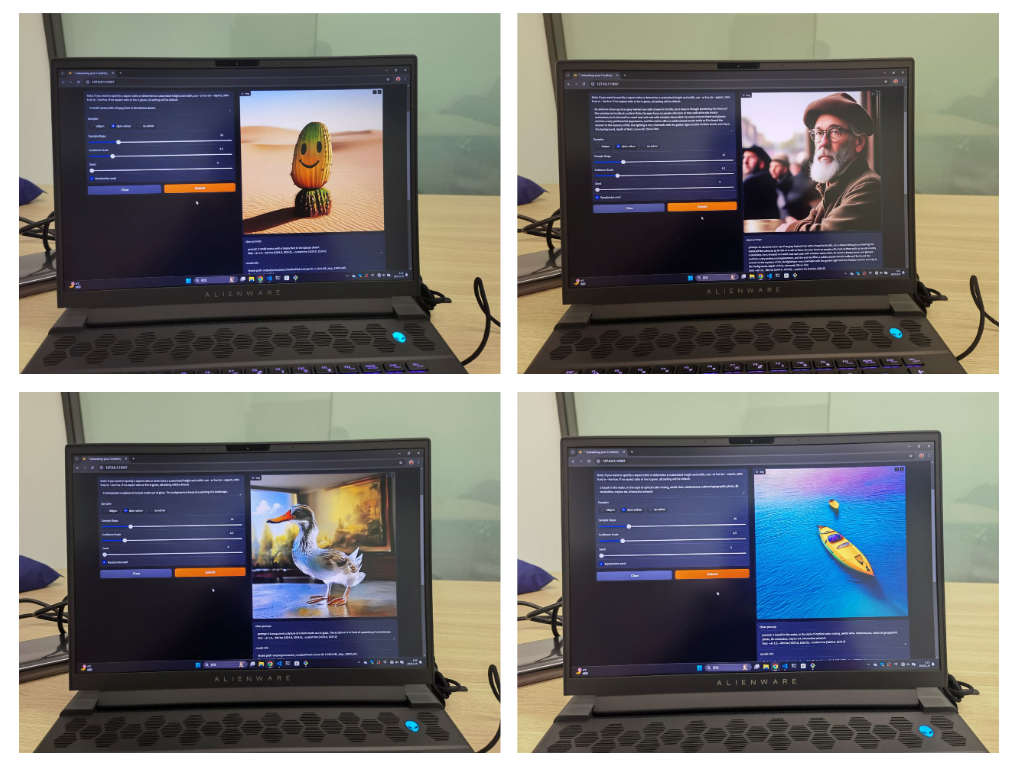
图 1:LiT 在 Windows 笔记本电脑的离线端侧部署:LiT 可以在端侧,断网状态,以完全离线的方式遵循用户指令,快速生成 1K 分辨率图片
-
论文名称:LiT: Delving into a Simplified Linear Diffusion Transformer for Image Generation
-
论文地址:https://arxiv.org/pdf/2501.12976v1
-
项目主页:https://techmonsterwang.github.io/LiT/
为了提高扩散模型的计算效率,一些工作使用 Sub-quadratic 计算复杂度的模块来替代二次计算复杂度的自注意力(Self-attention)机制。这其中,线性注意力的主要特点是:1) 简洁;2) 并行化程度高。这对于大型语言模型、扩散模型这样的大尺寸、大计算的模型而言很重要。
就在几天前,MiniMax 团队著名的《MiniMax-01: Scaling Foundation Models with Lightning Attention》已经在大型语言模型中验证了线性模型的有效性。而在扩散模型中,关于「线性注意力要怎么样设计,如何训练好基于纯线性注意力的扩散模型」的讨论仍然不多。
本文针对这个问题,该团队提出了几条「拿来即用」的解决方案,向社区读者报告了可以如何设计和训练你的线性扩散 Transformer(linear diffusion Transformers)。列举如下:
-
使用极简线性注意力机制足够扩散模型完成图像生成。除此之外,线性注意力还有一个「免费午餐」,即:使用更少的头(head),可以在增加理论 GMACs 的同时 (给模型更多计算),不增加实际的 GPU 延迟。
-
线性扩散 Transformer 强烈建议从一个预训练好的 Diffusion Transformer 里做权重继承。但是,继承权重的时候,不要继承自注意力中的任何权重 (Query, Key, Value, Output 的投影权重)。
-
可以使用知识蒸馏(Knowledge Distillation)加速训练。但是,在设计 KD 策略时,我们强烈建议不但蒸馏噪声预测结果,同样也蒸馏方差预测结果 (这一项权重更小)。
LiT 将上述方案汇总成了 5 条指导原则,方便社区读者拿来即用。
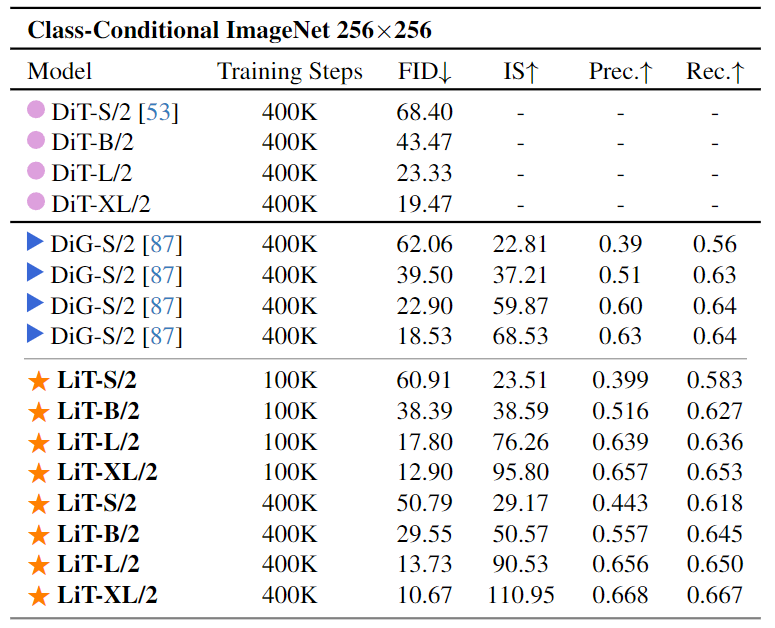
在标准 ImageNet 基准上,LiT 只使用 DiT 20% 和 23% 的训练迭代数,即可实现相当 FID 结果。LiT 同样比肩基于 Mamba 和门控线性注意力的扩散模型。
在文生图任务中,LiT-0.6B 可以在断网状态,离线部署在 Windows 笔记本电脑上,遵循用户指令快速生成 1K 分辨率逼真图片,助力 AIPC 时代降临。
Diffusion Transformer 正在助力文生图应用的商业化,展示出了极强的商业价值和潜力。但是,自注意力的二次计算复杂度也成为了 Diffusion Transformer 的一个老大难问题。因为这对于高分辨率的场景,或者端侧设备的部署都不算友好。
常见的 Sub-quadratic 计算复杂度的模块有 Mamba 的状态空间模型(SSM)、门控线性注意力(GLA)、线性注意力等等。目前也有相关的工作将其用在基于类别的(class-conditional)图像生成领域 (非文生图),比如使用了 Mamba 的 DiM、使用了 GLA 的 DiG 。但是,虽然这些工作确实实现了 Sub-quadratic 的计算复杂度,但是,这些做法也存在明显的不足:
-
其一,SSM 和 GLA 模块都依赖递归的状态 (State) 变量,需要序列化迭代计算,对于并行化并不友好。
-
其二,SSM 和 GLA 模块的计算图相对于 线性注意力 而言更加复杂,而且会引入一些算数强度 (arithmetic-intensity) 比较低的操作,比如逐元素乘法。
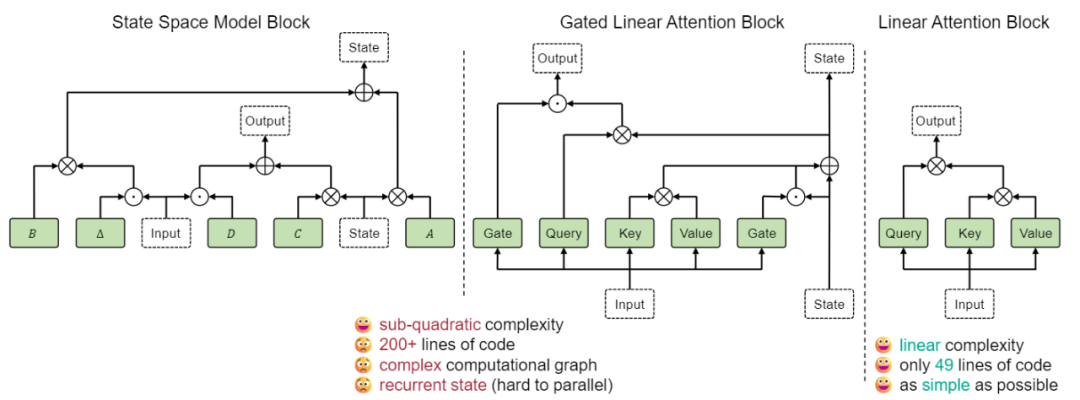
而线性注意力相比前两者,如下图 2 所示,不但设计简单,而且很容易实现并行化。这样的特点使得线性注意力对于高分辨率极其友好。比如对于 2048px 分辨率图片,线性注意力比自注意力快约 9 倍,对于 DiT-S/2 生成所需要的 GPU 内存也可以从约 14GB 降低到 4GB。因此,训练出一个性能优异的基于线性注意力的扩散模型很有价值。
图 2:与 SSM 和 GLA 相比,线性注意力同样实现 sub-quadratic 的计算复杂度,同时设计极其简洁,且不依赖递归的状态变量
但是,对于有挑战性的图像生成任务,怎么快速,有效地训练好基于线性注意力的扩散模型呢?
这个问题很重要,因为一方面,尽管线性注意力在视觉识别领域已经被探索很多,可以取代自注意力,但是在图像生成中仍然是一个探索不足的问题。另一方面,从头开始训练扩散模型成本高昂。比如训练 RAPHAEL 需要 60K A100 GPU days ( 中报告)。因此,针对线性扩散 Transformer 的高性价比训练策略仍然值得探索。
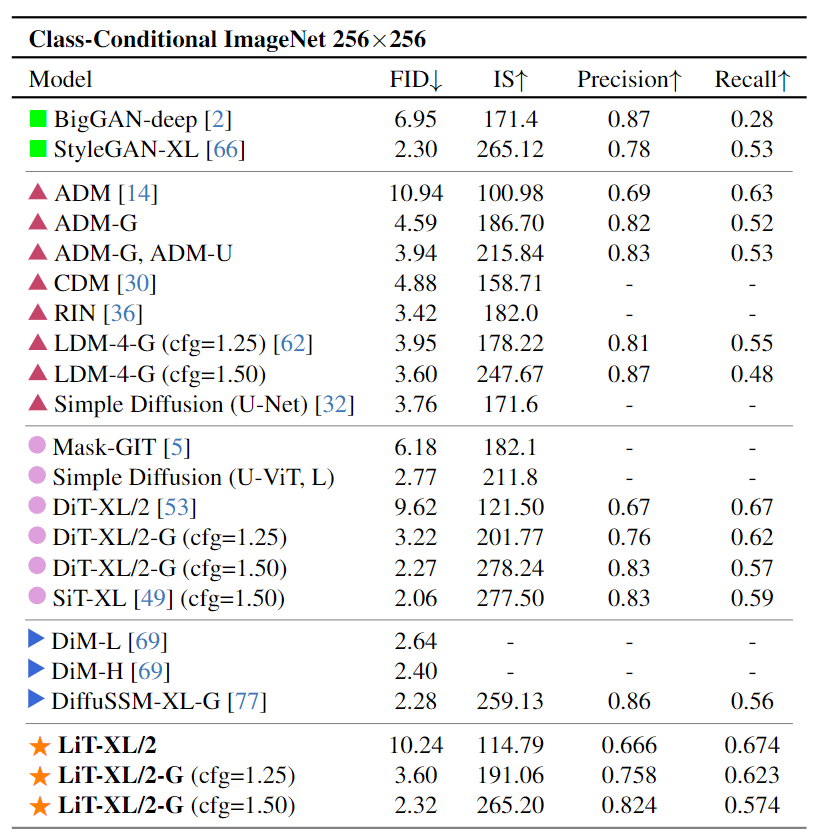
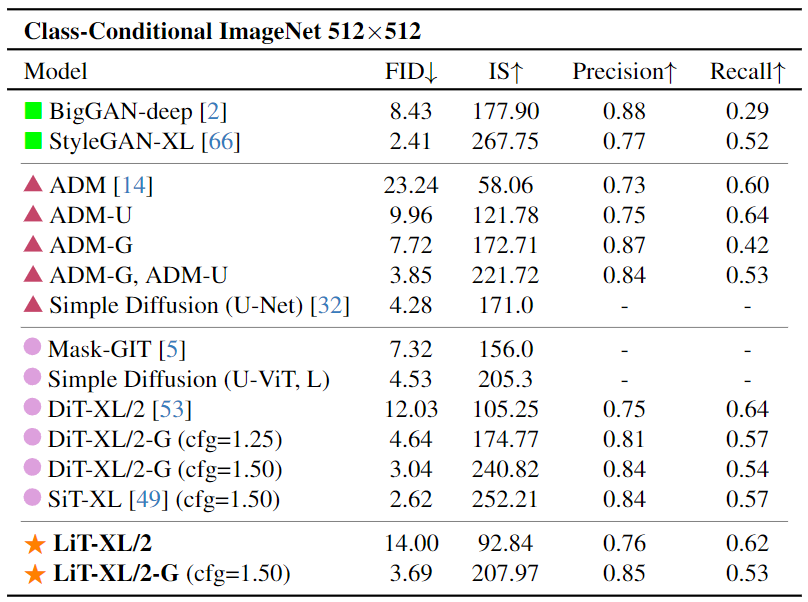
LiT 从架构设计和训练策略中系统地研究了纯线性注意力的扩散 Transformer 实现。LiT 是一种使用纯线性注意力的 Diffusion Transformer。LiT 训练时的成本效率很高,同时在推理过程中保持高分辨率友好属性,并且可以在 Windows 11 笔记本电脑上离线部署。在基于类别的 ImageNet 256×256 基准上面,100K 训练步数的 LiT-S/B/L 在 FID 方面优于 400K 训练步数的 DiT-S/B/L。对于 ImageNet 256×256 和 512×512,LiT-XL/2 在训练步骤只有 20% 和 23% 的条件下,实现了与 DiT-XL/2 相当的 FID。在文生图任务中,LiT-0.6B 可以在断网状态,离线部署在 Windows 笔记本电脑上,遵循用户指令快速生成 1K 分辨率逼真图片。
鉴于对生成任务上的线性扩散 Transformer 的探索不多,LiT 先以 DiT 为基础,构建了一个使用线性注意力的基线模型。基线模型与 DiT 共享相同的宏观架构,唯一的区别是将自注意力替换为 线性注意力。所有实验均在基于类别的 ImageNet 256×256 基准上进行,使用 256 的 Batch Size 训练了 400K 迭代次数。
Guideline 1:Simplified 线性注意力对于基于 DiT 的图像生成扩散模型完全足够。
我们首先尝试了在通用视觉基础模型中成功验证的常见线性注意力的架构设计,比如 ReLU 线性注意力 (使用 ReLU 激活函数作为线性注意力的 Kernel Function)。
对于性能参考,将其与 DiT 进行比较,其中任何性能差异都可以归因于线性注意力对生成质量的影响。如图 4 中所示。与 DiT 相比,使用 ReLU 线性注意力的 LiT-S/2 和 B/2 性能下降很大。结果表明,视觉识别中常用的线性注意力在噪声预测任务中有改进的空间。
-
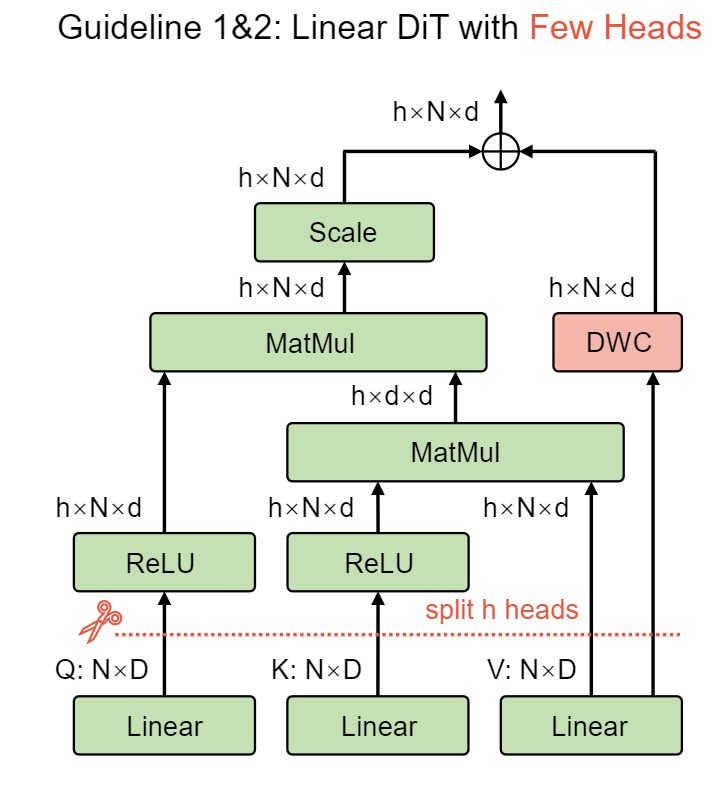
简化型线性注意力 (图 3,相当于在 ReLU 线性注意力的基础上加上 Depth-wise 卷积)。
-
-
Focused 线性注意力 (使用 GELU 替换 ReLU)。
这些选择中的每一个都保持了线性复杂度,保持了 LiT 在计算效率方面的优势。我们使用相对较大的卷积核 (Kernel Size 5) 来确保在预测噪声时足够大的感受野。
图 3:在 Simplified 线性注意力中使用更少的 heads
实验结果如图 4 所示。加了 DWC 的模块都可以取得大幅的性能提升,我们认为这是因为模型在预测给定像素的噪声时关注相邻像素信息。同时,我们发现 Focused Function 的有效性有限,我们将其归因于其设计动机,以帮助线性注意聚焦于特定区域。此功能可能适合分类模型,但可能不是噪声预测所必需的。为了简单起见,最后使用简化 线性注意力。
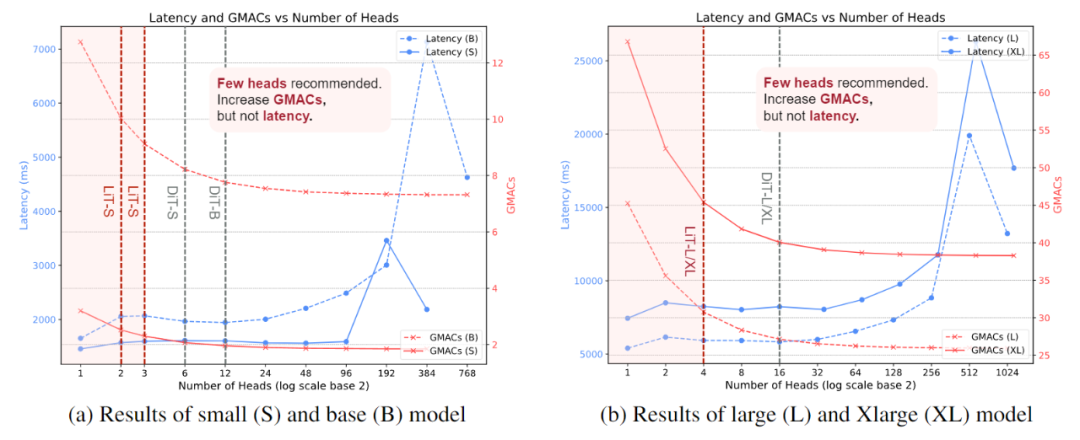
Guideline 2:在线性注意力中建议使用很少的头,可以在增加计算的同时不增加时延。
直觉上似乎使用更多头可以减少计算压力。但相反,我们建议使用更少的头,因为我们观察到线性注意力存在 Free Lunch 效应,如图 5 所示。图 5 展示了使用线性注意力的 Small,Base,Large,XLarge 模型使用不同头数量的延迟和 GMACs 变化。
图 5:线性注意力中的 Free Lunch 效应:不同头数量线性注意的延迟与理论 GMACs 比较
我们使用 NVIDIA A100 GPU 生成 256×256 分辨率的图像,批量大小为 8 (NVIDIA V100 GPU 出现类似现象)。结果表明,减小头数量会导致理论 GMACs 稳定增加,实际延迟却并没有呈现出增加的趋势,甚至出现下降。我们将这种现象总结为线性注意力的「免费午餐(Free Lunch)」效应。
我们认为在线性注意力中使用更少的头之后,允许模型有较高的理论计算,根据 scaling law,允许模型在生成性能上达到更高的上限。
实验结果如图 6 所示,对于不同的模型尺度,线性注意力中使用更少的头数 (比如,2,3,4) 优于 DiT 中的默认设置。相反,使用过多的头(例如,S/2 的 96 或 B/2 的 192),则会严重阻碍生成质量。
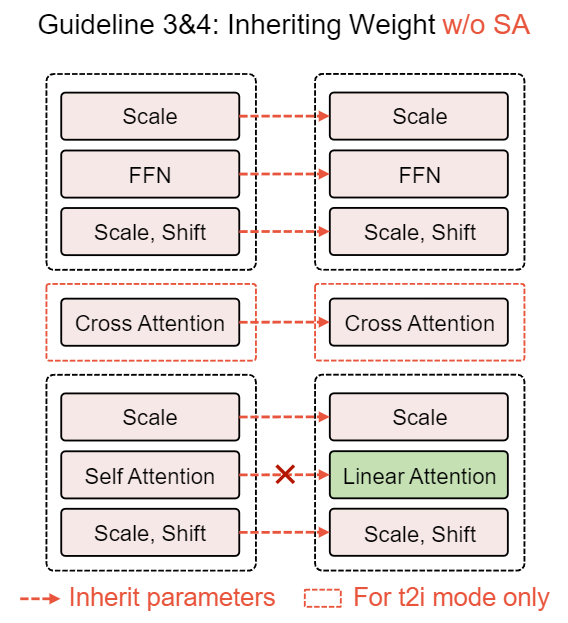
LiT 与 DiT 共享一些相同的结构,允许权重继承自预训练的 DiT 架构。这些权重包含丰富的与噪声预测相关的知识,有望以成本高效的方式转移到 LiT。因此,在这个部分我们探索把预训练的 DiT 权重 (FFN 模块、adaLN、位置编码和 Conditional Embedding 相关的参数) 继承给线性 DiT,除了线性注意力部分。
图 6:线性扩散 Transformer 的权重继承策略
Guideline 3:线性扩散 Transformer 的参数应该从一个预训练到收敛的 DiT 初始化。
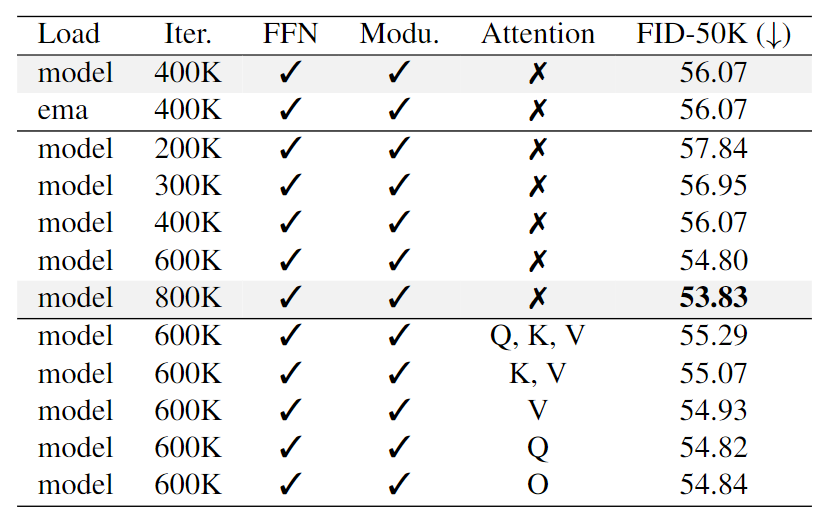
我们首先预训练 DiT-S/2 不同的训练迭代次数:200K、300K、400K、600K 和 800K,并且在每个实验中,分别将这些预训练的权重加载到 LiT-S/2 中,同时线性注意力部分的参数保持随机。然后将初始化的 LiT-S/2 在 ImageNet 上训练 400K 迭代次数,结果如图 6 所示。
-
DiT 的预训练权重,即使只训练了 200K 步,也起着重要作用,将 FID 从 63.24 提高到 57.84。
-
使用预训练权重的指数移动平均 (EMA) 影响很小。
-
DiT 训练更收敛时 (800K 步),更适合作为 LiT 的初始化,即使架构没有完全对齐。
我们认为这种现象的一种可能解释是 Diffusion Transformer 中不同模块的功能是解耦的。尽管 DiT 和 LiT 具有不同的架构,但它们的共享组件 (例如 FFN 和 adaLN) 的行为非常相似。因此,可以迁移这些组件预训练参数中的知识。同时,即使把 DiT 训练到收敛并迁移共享组件的权重,也不会阻碍线性注意力部分的优化。
图 7:ImageNet 256×256 上的权重继承消融实验结果
Guideline 4:线性注意力中的 Query、Key、Value 和 Output 投影矩阵参数应该随机初始化,不要继承自自注意力。
在 LiT 中,线性注意力中的一些权重与 DiT 的自注意力中的权重重叠,包括 Query、Key、Value 和 Output 投影矩阵。尽管计算范式存在差异,但这些权重可以直接从 DiT 加载到 LiT 中,而不需要从头训练。但是,这是否可以加速其收敛性仍然是一个悬而未决的问题。
我们使用经过 600K 次迭代预训练的 DiT-S/2 进行消融实验。探索了 5 种不同类型的加载策略,包括:
-
加载 Query,Key 和 Value 投影矩阵。
-
-
-
-
结果如图 7 所示。与没有加载自注意力权重的基线相比,没有一个探索的策略显示出更好的生成性能。这种现象可归因于计算范式的差异。具体来说,线性注意力直接计算键和值矩阵的乘积,但是自注意力就不是这样的。因此,自注意力中的 Key 和 Value 相关的权重对线性注意力的好处有限。
我们建议继承除线性注意力之外的所有预训练参数从预训练好的 DiT 中,因为它易于实现并且非常适合基于 Transformer 架构的扩散模型。
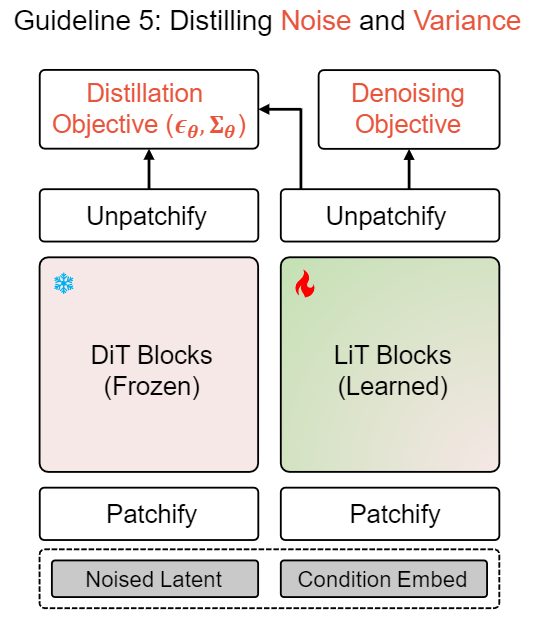
图 8:混合知识蒸馏训练线性扩散 Transformer
Guideline 5:使用混合知识蒸馏训练线性扩散 Transformer 很关键,不仅蒸馏噪声预测结果,还蒸馏方差的预测结果。
知识蒸馏通常采用教师网络来帮助训练轻量级学生网络。对于扩散模型,蒸馏通常侧重于减少目标模型的采样步骤。相比之下,我们专注于在保持采样步骤的前提下,从复杂的模型蒸馏出更简单的模型。
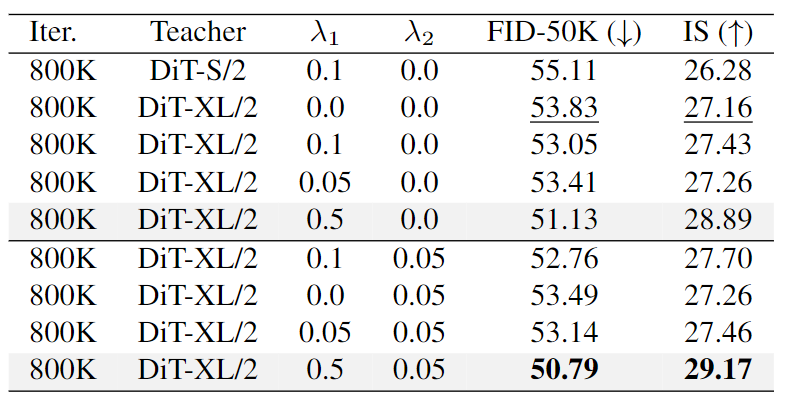
图 9:ImageNet 256×256 上的知识蒸馏实验结果,带有下划线的结果表示不使用知识蒸馏
到目前为止,LiT 遵循 DiT 的宏观 / 微观设计,但采用了高效的线性注意力。使用我们的训练策略,LiT-S/2 显著地提高了 FID。接下来,我们在更大的变体 (例如 B/L/XL) 和具有挑战性的任务 (比如 T2I) 上验证它。
我们首先在 ImageNet 256×256 基准上验证 LiT。LiT-S/2、B/2、L/2、XL/2 配置与 DiT 一致,只是线性注意力的头分别设置为 2/3/4/4。对于所有模型变体,DWC Kernel Size 都设置为 5。我们以 256 的 Batch Size 训练 400K 步。对于 LiT-XL/2,将训练步数扩展到 1.4M 步 (只有 DiT-XL/2 7M 的 20%)。我们使用预训练的 DiT 初始化 LiT 的参数。Lambda_1 和 lambda_2 在混合知识蒸馏中设置为 0.5 和 0.05。
图 10 和 11 比较了 LiT 和 DiT 的不同尺寸模型的结果。值得注意的是,仅 100K 训练迭代次数训练的 LiT 已经在各种评估指标和不同尺寸的模型中优于 400K 训练迭代次数训练的 DiT。使用 400K 训练迭代次数的额外训练,模型的性能继续提高。尽管训练步骤只有 DiT-XL/2 的 20%,但 LiT-XL/2 仍然取得与 DiT 相当的 FID 结果 (2.32 对 2.27)。此外,LiT 与基于 U-Net 的基线性能相当。这些结果表明,当线性注意力结合合适的优化策略时,可以可靠地用于图像生成应用。
图 10:ImageNet 256×256 基准实验结果,与基于自注意力的 DiT 和基于门控线性注意力的 DiG 的比较
图 11:ImageNet 256×256 基准实验结果
我们继续在 ImageNet 512×512 基准上进一步验证了 LiT-XL/2。使用预训练的 DiT-XL/2 作为教师模型,使用其权重初始化 LiT-XL/2。对于知识蒸馏,分别设置 Lambda_1 和 lambda_2 为 1.0 和 0.05,并且只训练 LiT-XL/2 700K 训练迭代次数 (是 DiT 3M 训练迭代次数的 23%)。
值得注意的是,与使用 256 的 Batch Size 的 DiT 不同,我们采用 128 的较小 Batch Size。这其实不占便宜,因为 128 的 Batch Size 相比 256 的情况,完成 1 Epoch 需要 2 倍的训练迭代次数。也就是说,我们 700K 的训练迭代次数其实只等效为 256 Batch Size 下的 350K。尽管如此,使用纯线性注意力的 LiT 实现了 3.69 的 FID,与 3M 步训练的 DiT 相当,将训练步骤减少了约 77%。此外,LiT 优于几个强大的 Baseline。这些结果证明了我们提出的成本高效的训练策略在高分辨率数据集上的有效性。实验结果如图 12 所示。
图 12:ImageNet 512×512 基准实验结果
文生图对于扩散模型的商业应用极为重要。LiT 遵循 PixArt-α 的做法,将交叉注意力添加到 LiT-XL/2 中使其支持文本嵌入。LiT 将线性注意力的头数设置为 2,DWC Kernel Size 设置为 5。遵循 PixArt-Σ 的做法,使用预训练的 SDXL VAE Encoder 和 T5 编码器 (即 Flan-T5-XXL) 分别提取图像和文本特征。
LiT 使用 PixArt-Σ 作为教师来监督其训练,分别设置 Lambda_1 和 lambda_2 为 1.0 和 0.05。LiT 从 PixArt-Σ 继承权重,除了自注意力的参数。随后在内部数据集上训练,学习率为 2e-5,仅训练 45400 步,明显低于 PixArt-α 的多阶段训练。图 13 为 LiT 生成的 512px 图像采样结果。尽管在每个 Block 中都使用了线性注意力,以及我们的成本高效的训练策略,LiT 仍然可以产生异常逼真的图像。
图 13:LiT 根据用户指令生成的 512px 图片
我们还将分辨率进一步增加到 1K。更多的实验细节请参阅原论文。图 14 是生成的结果采样。尽管用廉价的线性注意力替换所有自注意力,但 LiT 仍然能够以高分辨率生成逼真的图像。
图 14:LiT 根据用户指令生成的 1K 分辨率图片
我们还将 1K 分辨率的 LiT-XL/2 模型部署到一台 Windows 11 操作系统驱动的笔记本电脑上,以验证其 On-device 的能力。考虑到笔记本电脑的 GPU 内存的限制,我们将文本编码器量化为 8-bit,同时在线性注意力计算期间保持 fp16 精度。图 1 显示了我们的部署结果。预训练的 LiT 可以在离线设置 (没有网络连接) 的情况下快速生成照片逼真的 1K 分辨率图像。这些结果说明 LiT 作为一种 On-device 的扩散模型的成功实现,推进边缘设备上的高分辨率文生图任务。
展示了在断网状态下离线使用 LiT 完成 1K 分辨率文生图任务的过程。
(文:机器之心)