
今天是2025年02月14日,星期五,北京,天气晴。
我们继续来看GraphRAG进展。目前KG的一个趋势,还是与推理进行结合。所以来看医疗的一个结合思路MedRAG,不过,需要明确的是这类工具其实最多只能是作为医疗副手的关键模块,帮助减少医疗从业者与患者的误诊。
另外,用知识图谱进行上下文扩展的思路已经被用烂了。所以,在回顾一下,大家可能忘了,所以再温故下,会有收获。
专题化,体系化,会有更多深度思考。大家一起加油。
一、GraphRAG进展MedRAG思路
GraphRAG进展,可以看看最近的工作《MedRAG: Enhancing Retrieval-augmented Generation with Knowledge Graph-Elicited Reasoning for Healthcare Copilot》,https://arxiv.org/pdf/2502.04413,https://github.com/SNOWTEAM2023/MedRAG,其认为现有的RAG和LLMs依赖于基于启发式的方法,导致输出错误或模糊,特别是当疾病具有相似的表现时,所以提到使用KG来增强推理。

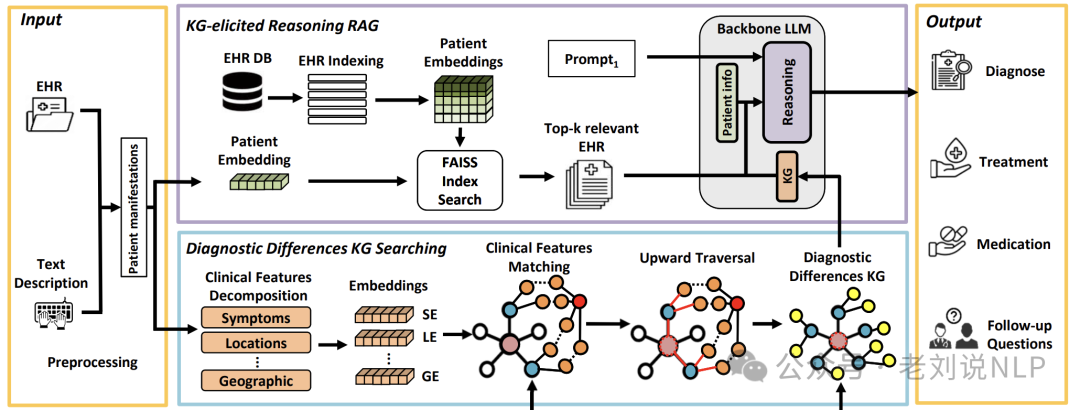
这个工作,目的只要用于解决医疗诊断中RAG模型的准确性和特异性问题。技术逻辑图如下:
MedRAG首先从结构化或非结构化输入中提取患者(红色节点)表现,并分解不同的临床特征。这些特征被嵌入并与诊断知识图谱匹配以识别关键诊断差异知识图谱。

MedRAG的知识图谱引导推理RAG模块检索相关的EHRs并将它们与这些诊断差异知识图谱整合,以触发大型语言模型中的推理。这一推理生成精确的诊断、治疗建议和后续问题。
既然用到知识图谱,就会涉及到知识图谱的构建和后期搜索过程,所以我们来具体看看。
1、诊断知识图谱构建
诊断知识图谱构建阶段首先从EHR数据库中提取潜在诊断及其表现形式,通过聚类和层次聚合构建一个四层级的疾病知识图谱。

可以看下这个实现步骤:
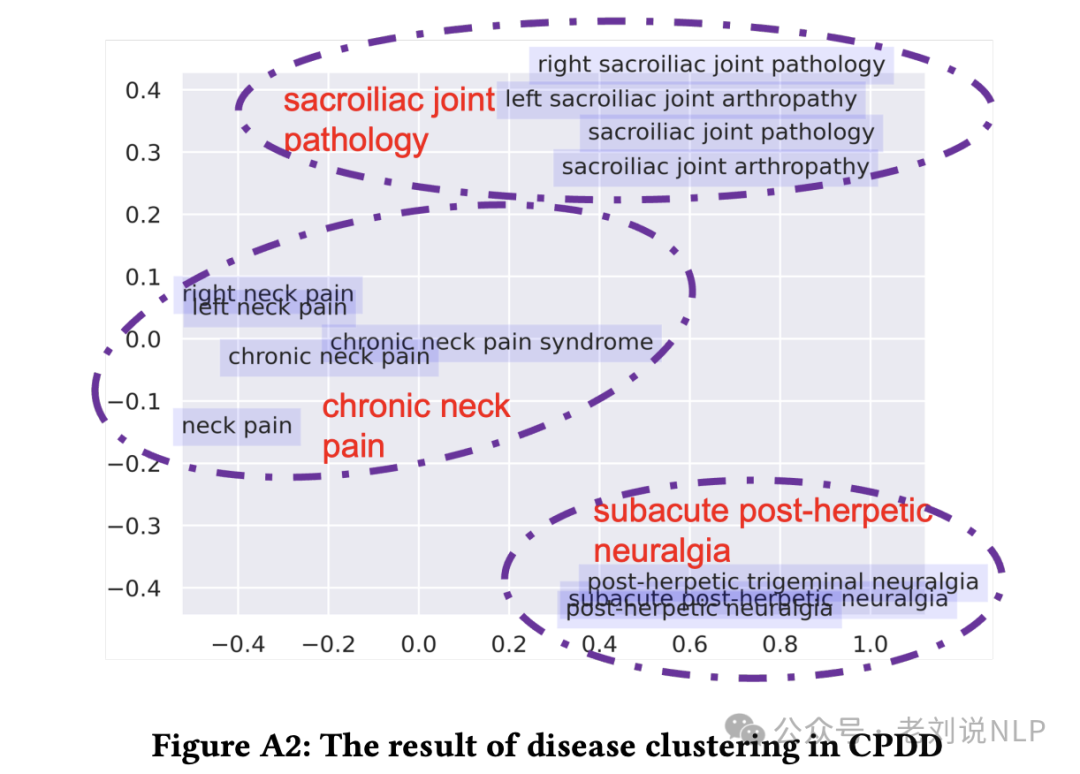
首先是疾病聚类。通过聚类模型将原始疾病描述统一为一种疾病名称,确保每个疾病名称在整个数据集中保持一致。例如,CPDD中疾病聚类的结果如下图:
然后是,层次聚类。使用大模型(LLM)对聚类后的疾病进行主题聚合,提取最相关的子类别,并将这些子类别进一步聚合为更高层次的类别,形成从子类别到更广泛类别的层次结构。
接着是特征分解,将疾病的症状分解为离散的特征节点,如症状、位置和活动限制等。
最后是图谱构建,将疾病类别信息与特征节点结合,形成综合疾病知识图谱,捕捉疾病类别信息及其相关特征。一个典型的例子如下图。
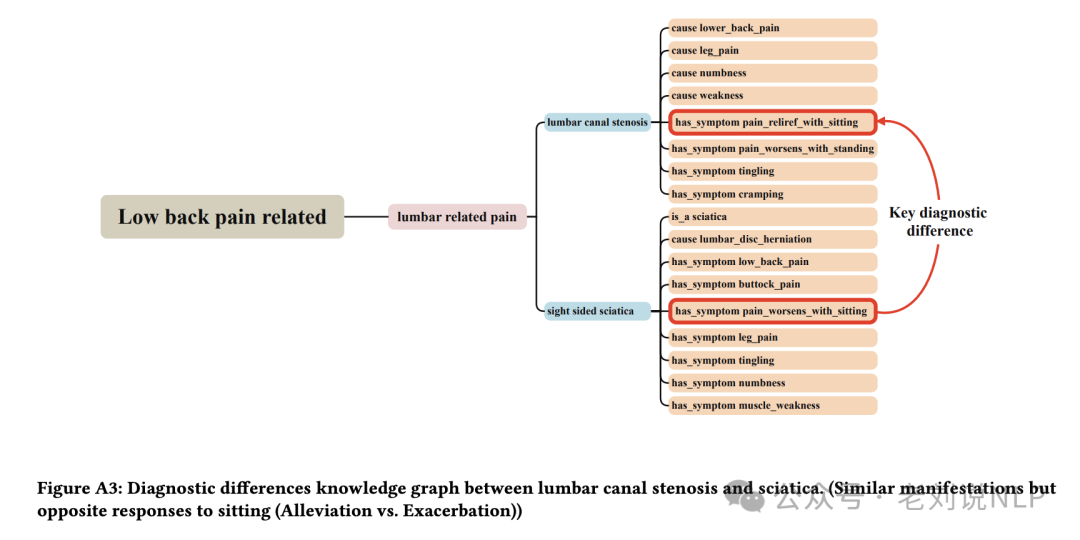
腰椎管狭窄和坐骨神经痛之间的诊断差异知识图谱。相似的表现但对坐姿有相反的反应(缓解 vs 加重)。
2、知识图谱检索及推理生成
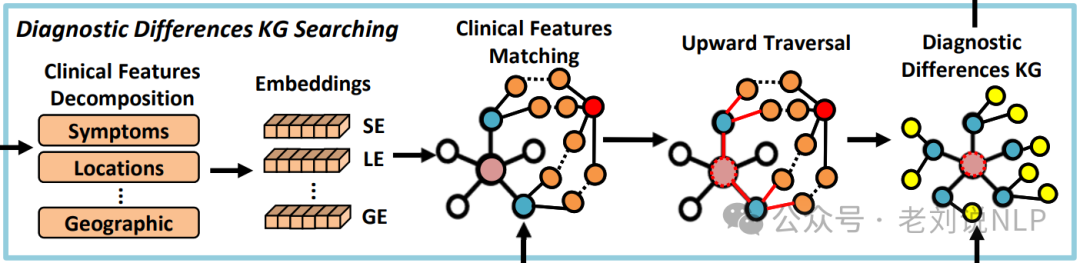
这个环节的示意图如下:
首先,进行症状分解与匹配。将患者的症状分解为临床特征(如症状和位置),并通过多级匹配和向上遍历在诊断知识图谱中识别关键诊断差异。
其次,进行KG推理。包括文档检索器和KG推理LLM引擎。检索器根据患者嵌入选择相关的EHR文档,并将其与关键诊断差异知识图谱结合,触发LLM进行推理。
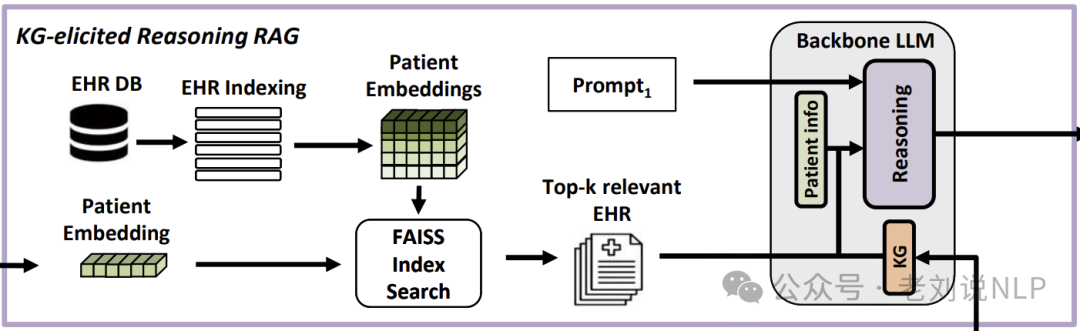
最后,生成最终诊断。LLM在接收到相关信息后,生成最终的诊断、治疗建议和后续问题。推理部分使用的prompt如下:

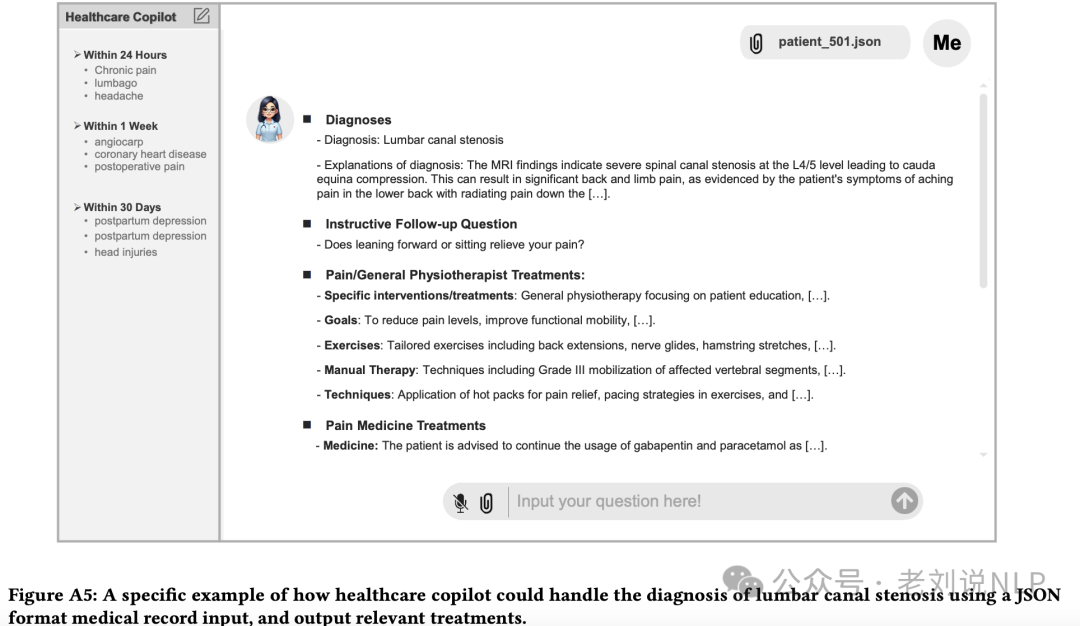
最后看效果,如下,说明医疗副手如何利用JSON格式的病历输入来处理腰椎管狭窄的诊断,并输出相关治聊建议:
当然,如果上升到产品层面,则可以使用语音输入,文字输入。
一、再回顾GraphRAG中利用知识图谱进行上下文扩展的思路
利用知识图谱进行上下文扩展的思路已经被用烂了。所以,在回顾一下,大家可能忘了。《Knowledge Graph-Guided Retrieval Augmented Generation》,https://arxiv.org/pdf/2502.06864。提出了KG2RAG框架,三阶段,但未开源。
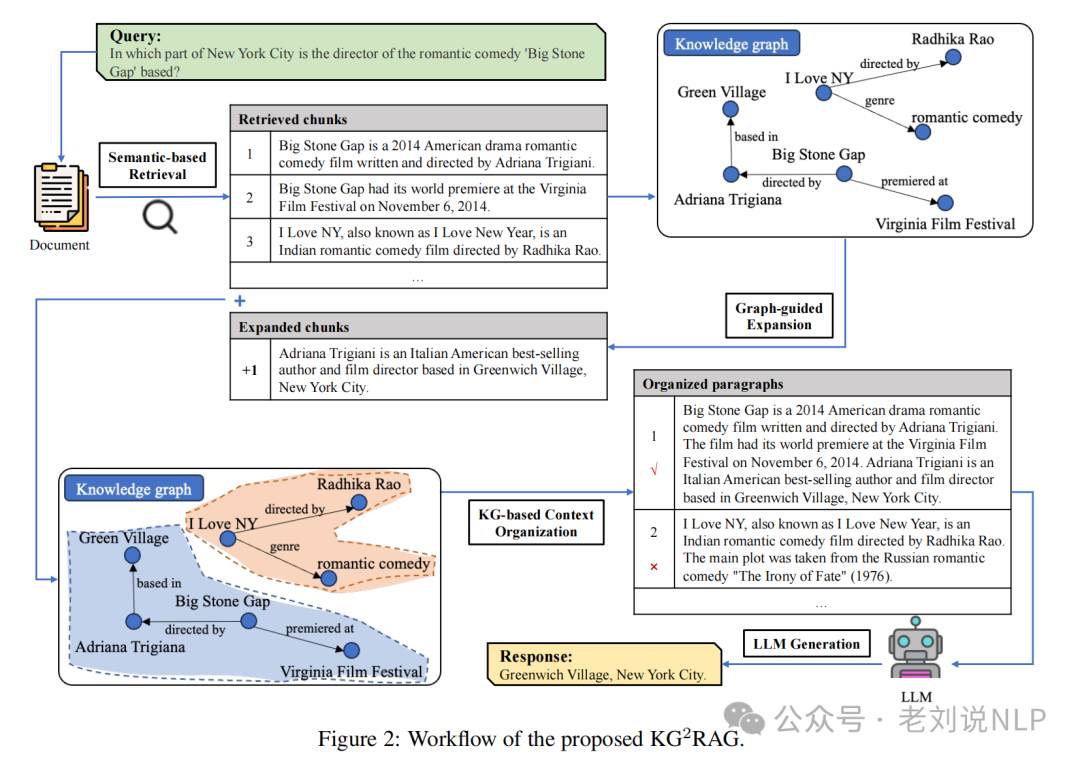
还是看几个点。
一个是看怎么构建知识图谱。步骤如下:
首先是分割文档,将所有文档按句子和段落结构分割成多个片段。
其次进行预处理,对这些片段进行预处理,如添加相关上下文、提取元信息(如标题、摘要)和生成相应的问题。
最后进行关联知识图谱,将这些片段与特定的知识图谱(KG)关联,建立片段与KG之间的链接。具体包括实体和关系识别以及链接算法,或者直接从片段中提取多个实体和关系形成子图。提取的promot如下:

一个是看KG增强片段检索。包括两阶段的检索过程,基于语义的检索和图引导的扩展。
基于语义的检索使用嵌入模型计算用户查询与所有片段的语义相似度,选择相似度最高的k个片段作为检索到的片段,作为种子片段。
基于知识图谱引导的扩展将这些片段作为种子片段,通过图遍历算法扩展子图,获取包含重叠或相关实体和三元组的扩展片段。具体,使用广度优先搜索(BFS)算法捕捉种子片段中的所有实体及其m跳邻居实体和连接这些实体的所有边,形成扩展子图,形成更全面的片段网络。这一不是扩召回的阶段。
最后,KG基础上的上下文组织阶段,在检索后,通过计算扩展片段与用户查询的语义相似度,过滤掉不相关的片段,并将片段组织成内部连贯的段落。
参考文献
1、https://arxiv.org/pdf/2502.04413
2、https://arxiv.org/pdf/2502.06864
(文:老刘说NLP)