两款 Step 系列开源多模态大模型,性能位列开源多模态全行业第一。
本周二,国内 AI 创业公司阶跃星辰和吉利汽车集团宣布联合开源两款多模态大模型。
这两款大模型分别是视频生成模型 Step-Video-T2V 和行业内首款产品级开源语音交互模型 Step-Audio。根据官方的测评报告,目前 Step-Video-T2V 是全球范围内参数量最大、性能最好的开源视频生成模型。
Step-Video-T2V 模型部署及技术报告链接:
-
GitHub:https://github.com/stepfun-ai/Step-Video-T2V
-
Hugging Face:https://huggingface.co/stepfun-ai/stepvideo-t2v
-
Modelscope:https://modelscope.cn/models/stepfun-ai/stepvideo-t2v
-
技术报告:https://arxiv.org/abs/2502.10248
和此前引爆全球科技界的 DeepSeek R1 一样,阶跃星辰的 Step-Video-T2V 视频生成模型,采用最为宽松的 MIT 许可协议,支持免费商用、任意修改和衍生开发,为开源社区带来了新的技术思路启发。这次发布也意味着阶跃星辰成为大模型开源世界的又一股中国力量。
与此同时,两款大模型均已可以在「跃问」App 上进行体验,视频模型还可以在桌面端使用:https://yuewen.cn/videos
阶跃星辰的大模型在 AI 社区引发了关注。Hugging Face 工程师、前谷歌 TensorFlow 团队成员 Tiezhen Wang 表示,阶跃星辰简直就是下个 DeepSeek:
GPT-J 作者 Aran Komatsuzaki 贴出了用新模型生成的视频。
更多网友对国内 AI 公司对开源社区的贡献表示了欢迎。
初步体验一下,可以感觉到 Step-Video-T2V 显著提升了视频生成 AI 能力的上限。我们看看目前人们用跃问视频生成的效果。
首先要关注的是在电影、视频短片中最显制作者「功力」的镜头调度能力:
低角度旋转镜头围绕着一个鼓手和他的架子鼓。鼓手穿着深色T恤和浅色裤子,戴着帽子,手臂上有纹身。
在晴朗的海滩上,一个男孩正在建造沙堡。镜头以俯视角度拍摄,展现他专注的神情和灵巧的双手。
看起来 Step-Video-T2V 具备强大的运镜能力,它能够实现推、拉、摇、移、旋转、跟随等多种镜头运动方式,还能支持不同景别之间的切换。
其次是生成式 AI 的老大难问题 —— 人物运动的姿态。
一个精灵,在森林中起舞,身旁是萤火虫环绕,月光透过树叶,慢速展现精灵的轻盈,画面梦幻唯美。
很多例子显示,Step-Video-T2V 擅长复杂运动生成,无论是高雅优美的芭蕾舞、对抗激烈的空手道、紧张刺激的羽毛球,还是高速翻转的跳水,新模型都展现出了对复杂运动场景的优秀把控能力。
我们也很关心 AI 生成人物形象和表情的合理性,在这方面 Step-Video-T2V 也做得不错。
人物模糊化失焦拍摄,一个女孩的侧脸,披肩黑色长卷发,戴着红色贝雷帽,穿着蓝色毛衣,正在笔记本电脑前打字。
从众多案例中我们可以发现,Step-Video-T2V 生成的人物形象相比此前的多模态大模型更加逼真、生动,细节更丰富,表情也更自然。AI 生成的人物五官、发型、皮肤纹理都更加细腻。
从生成效果来看,Step-Video-T2V 在复杂运动、人物美感、视觉想象力、基础文字生成、原生中英双语输入和镜头语言等方面具备强大能力,并具有突出的语义理解和指令遵循能力,可以帮助人们更精准地呈现创意。
惊艳的视频生成效果背后,是阶跃星辰自研且具有创新性的基础多模态大模型。
Step-Video-T2V 在开源的同时也第一时间放出了技术报告,可知该模型的参数量达到 300 亿,可以单次直接生成 204 帧、540P 分辨率的高质量视频。这意味着大模型能够确保生成的视频内容具有极高的信息密度和一致性。
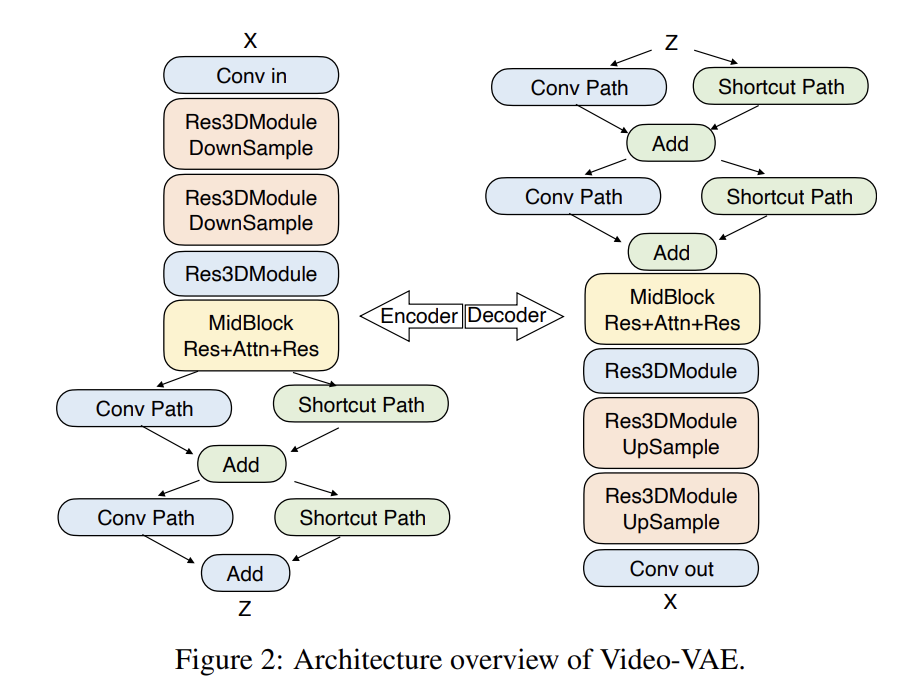
在模型细节上,为了实现更加逼真的视频生成,研究人员设计了深度压缩变分自编码器 Video-VAE,它实现了 16×16 的空间压缩比。与绝大多数 8×8×4 压缩比的 VAE 模型相比,Video-VAE 能够在相同视频帧数下额外压缩 8 倍,从而实现训练和生成效率提升 64 倍的效果。
与此同时,阶跃使用流匹配训练了一个具有 3D 全注意力机制的 DiT,用于将输入噪声去噪成潜在帧,还应用了基于视频的 DPO 方法以减少伪影并提高生成视频的视觉质量。
双语文本编码器和具有 3D Attention 的 DiT 的模型架构。
为了对开源视频生成模型的性能进行全面评测,阶跃星辰还开源了针对文生视频质量评测的基准数据集 Step-Video-T2V-Eval。该测试集包含 128 条源于真实用户的中文评测问题,旨在评估生成视频在运动、风景、动物、组合概念、超现实、人物、3D 动画、电影摄影等 11 个内容类别上质量。
Step-Video-T2V-Eval 评测结果。
评测结果显示,Step-Video-T2V 的模型性能在指令遵循、运动平滑性、物理合理性、美感度等方面全面超越了此前行业内性能最好的开源模型。
在语音交互一侧,阶跃星辰开源的 Step-Audio,能够根据不同场景生成情绪、方言、语种、歌声和个性化风格的表达,让 AI 能和用户自然地进行高质量对话。
这里有一些实测例子。在 Step-Audio 加持下,我们发现现在的 AI 还懂得了很多人情世故:
Step-Audio 的反应速度很快,生成的语音也非常自然,还具备不错的情商。据悉,Step-Audio 也能实现高质量音色复刻和角色扮演,可满足影视娱乐、社交、游戏等行业场景的应用。
在 LlaMA Question、Web Questions 等五大主流公开测试集上,Step-Audio 的性能均超过行业内同类型开源模型,位列第一。另外,Step-Audio 在汉语水平考试六级 HSK-6 评测中的表现尤为突出,成为了最懂中国话的开源语音交互大模型。
此外,根据阶跃自建并开源的多维度评估体系 StepEval-Audio-360 基准测试显示,Step-Audio 在逻辑推理、创作能力、指令控制、语言能力、角色扮演、文字游戏、情感价值等维度均取得了最佳成绩。
具体来说,Step-Audio 的技术探索为多模态开源社区带来了五个方面的贡献:
-
多模态理解生成一体化:单模型完成语音识别、语义理解、对话、语音生成等功能,并开源了千亿参数多模态模型 Step-Audio-Chat 版本;
-
高效合成数据链路:Step-Audio 突破传统 TTS 对人工采集数据的依赖,能生成高质量的合成音频数据,实现合成数据生成与模型训练的循环迭代,并同步开源了首个基于大规模合成数据训练,支持 RAP 和哼唱的指令加强版语音合成模型 Step-Audio-TTS-3B;
-
精细语音控制:支持多种情绪(如生气、高兴、悲伤)、方言(如粤语、四川话)和唱歌(包括 RAP、干声哼唱)的精准调控;
-
扩展工具调用:通过 ToolCall 机制,Step-Audio 能够集成搜索引擎、知识库等外部工具,进一步提升其在 Agents 和复杂任务上的表现;
-
高情商对话与角色扮演:基于情感增强与角色扮演强化的 RLHF 流程,提供了人性化回应并支持定制化角色设定。
-
GitHub 链接:https://github.com/stepfun-ai/Step-Audio
-
Hugging Face:https://huggingface.co/collections/stepfun-ai/step-audio-67b33accf45735bb21131b0b
-
Modelscope:https://modelscope.cn/collections/Step-Audio-a47b227413534a
-
技术报告:https://github.com/stepfun-ai/Step-Audio/blob/main/assets/Step-Audio.pdf
ChatGPT 发布仅过去两年,生成式 AI 领域已经历了翻天覆地的变化。我们见证了巅峰时期 300 家大模型的同台竞技,转变成「大模型 n 小龙」在不同赛道上的努力探索。自去年底,DeepSeek 的爆发又仿佛一阵强心剂,激起了业界新一轮更加激烈的竞争。
新的局面下,GPU 数量和数据体量优势不再是创业公司难以逾越的壁垒。与此同时,一些坚持技术路线的公司正在逐渐显现优势。
与很多逐渐转向应用侧的大模型公司不同,阶跃一直专注于技术驱动的发展思路,不断投入资源迭代基础模型。凭借技术的深厚积累,阶跃星辰一直在多模态领域领先业界。
从产品布局来看,阶跃的大模型涵盖语音识别、语音复刻及生成模型、视频理解模型、图像生成模型、视频生成模型、多模态理解等各种类别,而且研发速度极快,自成立以来已先后发布了 11 款。
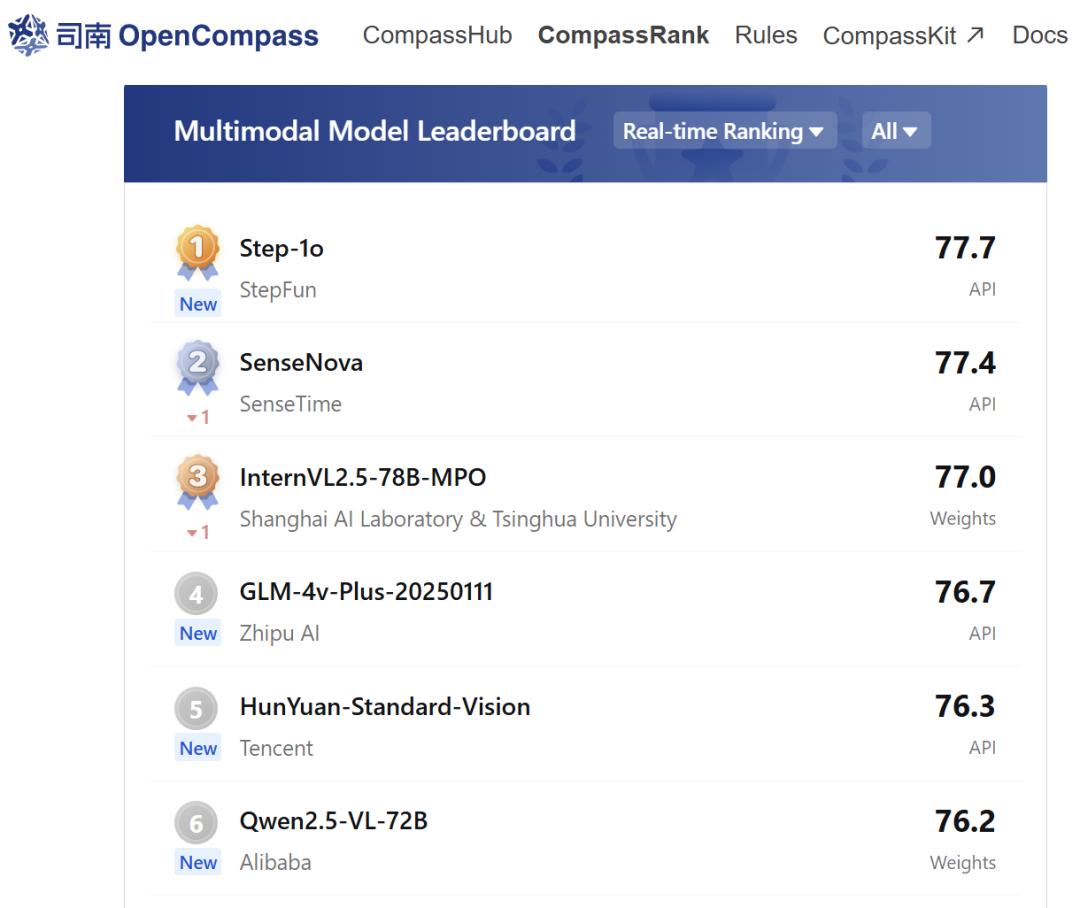
从成绩上看,阶跃的 Step 系列多模态模型曾多次在国内外权威大模型评测榜单上位列「中国大模型第一」。不论开源社区还是合作伙伴,都已对阶跃的大模型有了充分的认可。
在 OpenCompass 多模态模型评测实时榜单上,Step-1o 大模型名列业内第一。
真正以构建 AGI 为最终目标的团队,必然会选择坚持预训练和基座大模型的研发。阶跃星辰曾披露过自己的 AGI 路线图,「单模态 —— 多模态 —— 多模理解和⽣成的统⼀ —— 世界模型 ——AGI」。
这样的思路在今天发布的 Step-Video-T2V 技术报告中有了体现。阶跃星辰定义了构建视频基础模型的两个级别:
-
Level 1 是翻译视频的基础模型。此类模型可充当跨模态翻译系统,能够从文本、视觉或多模态上下文生成视频。目前基于扩散的文本转视频模型如 Sora、Veo、Kling、Hailuo 和 Step-Video 系列都属于 Level 1。
-
Level 2 则是「可预测视频基础模型」。此级别的模型充当预测系统,类似于大语言模型(LLM),可以根据文本、视觉或多模态上下文预测未来事件,并处理更高级的任务,例如使用多模态数据进行推理或模拟真实世界场景。
技术报告中,工程师们介绍了开发 Level 2 级视频基础模型需要解决的关键问题。如果我们能够对视频中潜在的因果关系进行建模,就能够生成更加复杂的动作序列,以及真正遵守物理定律的视频,让多模态拥有像如今 LLM 中涌现的「推理」。
这样的理念与李飞飞和她在 World Labs 中的工作不谋而合。可见在多模态大模型领域,新的方向已逐渐清晰。
可以预见,DeepSeek 爆发之后,更多的国内领先开源技术将会兴起,成为 AI 领域中不可忽视的力量。
(文:机器之心)