

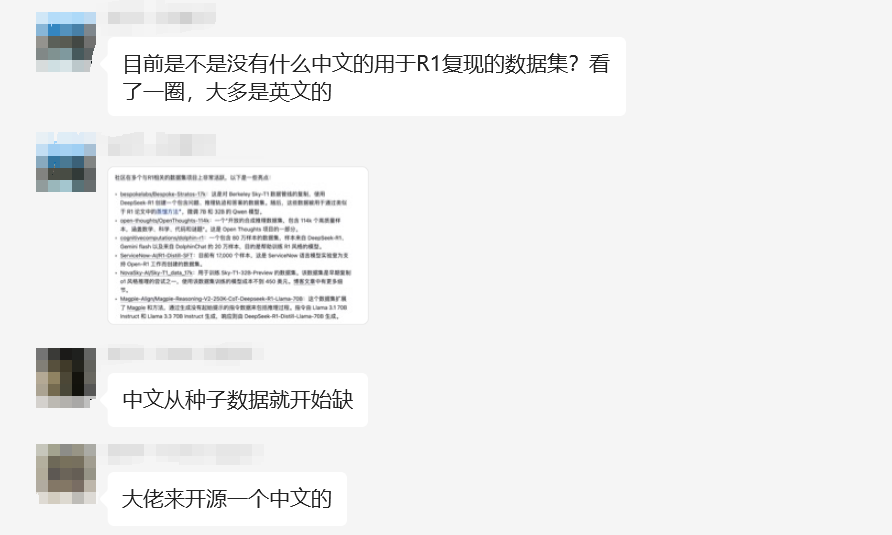
-
Math:共计36987个样本, -
Exam:共计2440个样本, -
STEM:共计12000个样本, -
General:共计58573,包含弱智吧、逻辑推理、小红书、知乎、Chat等。
数据集蒸馏细节
-
Haijian/Advanced-Math -
gavinluo/applied_math -
meta-math/GSM8K_zh -
EduChat-Math -
m-a-p/COIG-CQIA -
m-a-p/neo_sft_phase2 -
hfl/stem_zh_instruction

-
不增加额外的系统提示词 -
设置temperature为0.6 -
如果为数学类型数据,则增加提示词,“请一步步推理,并把最终答案放到 \boxed{}。” -
防止跳出思维模式,强制在每个输出的开头增加”\n”,再开始生成数据
写在最后
(文:机器学习算法与自然语言处理)