智东西2月26日报道,又一家科技巨头将多模态大模型开源了!今日,微软研究院发布首个多模态AI agents基础模型Magma,使得AI助手能解释环境、规划行动并在数字及物理空间中执行任务。

这是首个能够在其所处环境中理解多模态输入并将其与实际情况相联系的基础模型。只要提供一个描述性目标,Magma就能够制定计划、执行行动以达成目标。
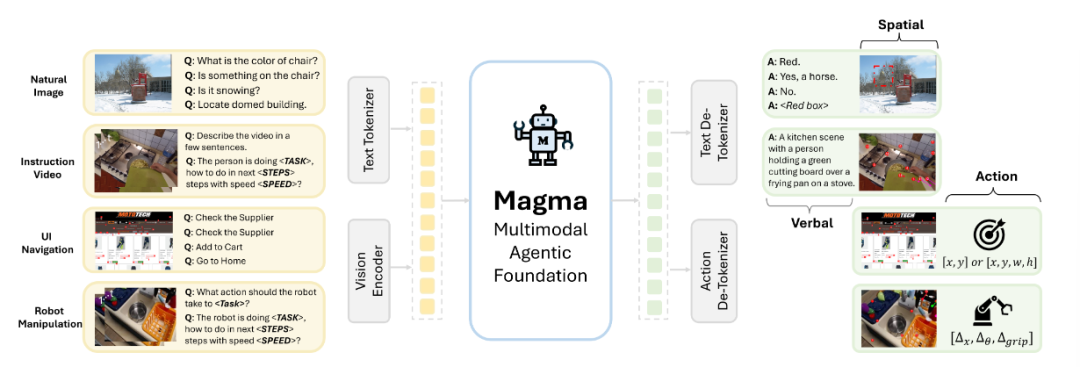
Magma以视觉语言(VL)模型为基础,除了保留传统的语言和视觉理解能力(语言智能)外,还解锁了在视觉空间世界中规划和行动的能力(空间智能)的新技能,并能够完成从数字空间里的用户界面(UI)导航到物理世界里的机器人操作等各种agent任务。
在VL任务上,相比用更大数据集训练的主流VL模型,Magma也更有优势。
值得一提的是,研究人员中,13位有12位应该是华人。中美AI、机器人竞赛的背后,果然还是在美华人和在华中国人之间的较量。

GitHub地址:microsoft.github.io/Magma/
论文地址:arxiv.org/pdf/2502.13130
研究团队展示了两个UI导航示例,分别向Magma发出两个指令:1)西雅图的天气怎么样?&打开飞行模式;2)分享和发消息给鲍勃史蒂夫,点击发送按钮完成。Magma都能按照要求执行任务。
研究团队还展示了8个Magma视频理解的示例。比如问它如何才能赢了眼前这场国际象棋比赛(左),有什么在当前环境里放松几个小时的建议(右)。
或者让Magma详细描述视频中发生了什么动作,并预测接下来会发生什么。
还可以要求Magma详细描述视频里发生的主要动作,或者视频里的人选择了什么饮料。
也可以要求Magma预测这个人的下一步行动,或者描述视频中的人正在做什么。
Magma使用ConvNeXt-XXL视觉骨干处理图像和视频,同时使用Llama-3-8B语言模型处理文本输入,从多模态输入(用户界面截图、机器人图像、教学视频)中理解对象的物理位置、动作的时序逻辑,并在不同环境(数字界面与物理世界)中完成连贯的任务。
▲Magma预训练流程
该模型在一个包含3900万个样本的异构VL数据集(包含图像、视频、机器人动作轨迹)上进行预训练,创新地采用了两项技术:“可标记集”(Set-of-Mark,SoM)和 “轨迹标记”(Trace-of-Mark,ToM)。
SoM提示通过让模型预测图像空间中的可操作视觉对象(比如图形用户界面中的可点击按钮、机械臂的数字标记),为UI截图(左)、机器人操作(中)和人类视频(右)提供有效的图像操作基础。
ToM则使模型能够在行动前理解时间视频动态并预测未来状态,比如对机器人操作(左)和人类行为(右)的轨迹监督,同时使用比下一帧预测更少的token来捕捉更长的时间视界和与行动相关的动态,而不受环境干扰。
研究团队将SoM和ToM应用于不同的数据类型,SoM支持跨所有模式的统一操作基础,而ToM专门应用于视频和机器人数据。
Agent智能方面,研究团队对包括ChatGPT在内的多个模型进行了零样本评估,结果显示,经过预训练的Magma模型在未进行任何特定领域微调情况下,是唯一一款能够执行全范围任务的模型。
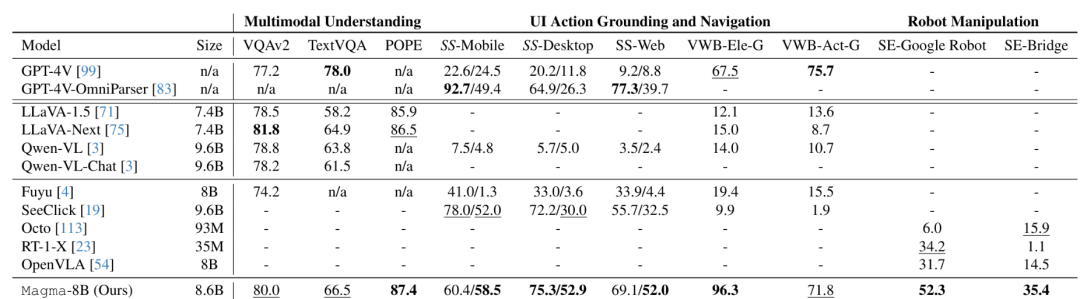
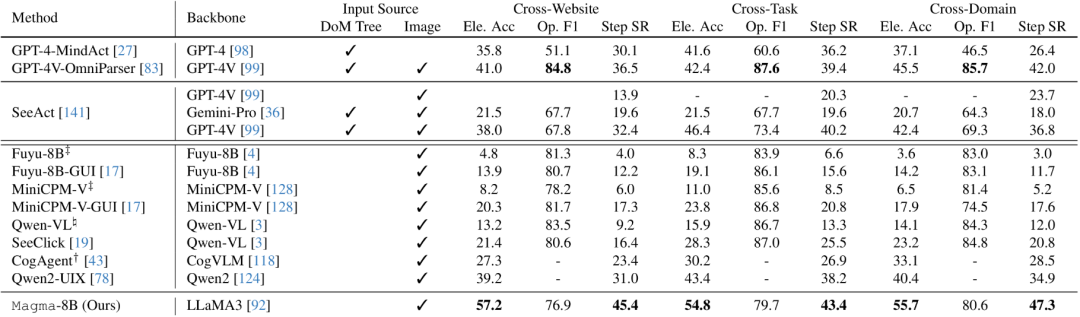
在Mind2Web上对网页UI导航进行有效微调的分数如下:
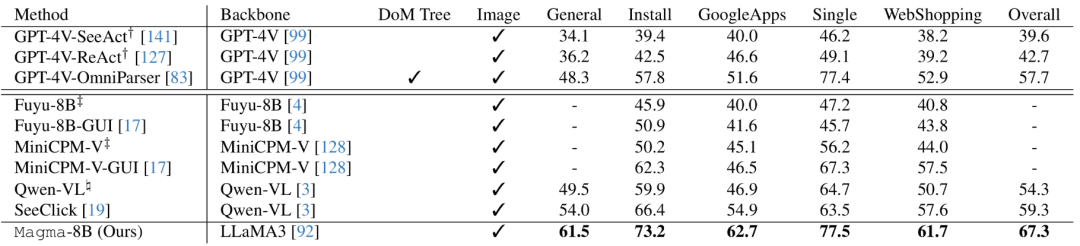
在AITW上对移动UI导航进行有效微调的分数如下:
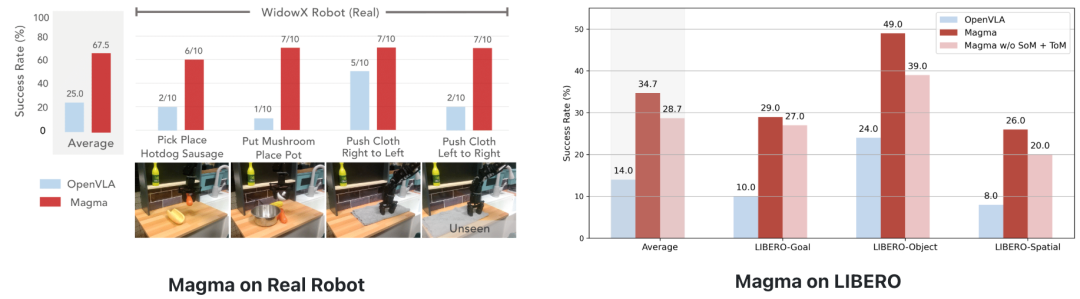
机器人操作方面,将Magma和OpenVLA这两个模型应用到WidowX机械臂上,并经过少样本的微调后,当让机械臂组装桌面上的热狗模型、把蘑菇模型放到盆中、把桌子上的抹布从左边移动至右边时,Magma可以让机械臂比较完整、连贯地完成任务,在真实机器人的分布内和分布外泛化任务中都表现出可靠的性能,而OpenVLA(微调)则在软物体操作、取放操作上表现逊色于Magma。

▲上方为Magama,下方为OpenVLA
在LIBERO上进行少样本微调,Magma在所有任务组合中实现了显著更高的平均成功率。此外,在预训练期间去除SoM和ToM会对模型性能产生负面影响。
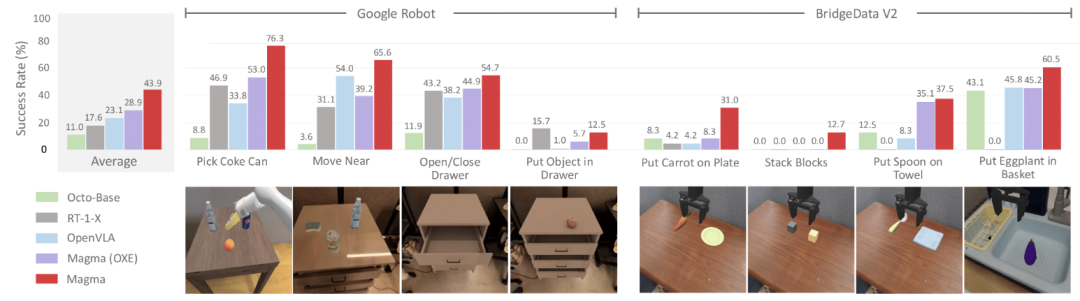
在Google Robots和Bridge上进行的零样本评估中,Magma模型也展现出了较强的零样本跨域鲁棒性,并在抓取多种不同物品等跨实体操作模拟任务中取得了不错成绩。
空间推理方面,在预训练数据远少于GPT-4o的情况下,Magma能实现相对较好地回答。
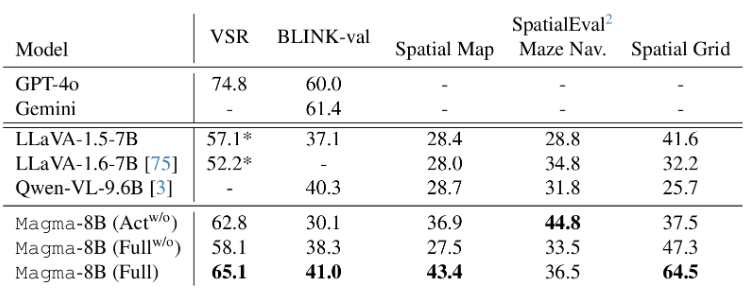

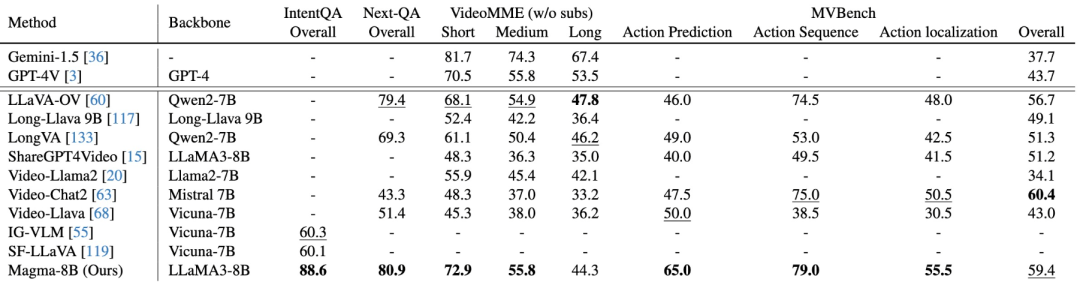
多模态理解方面,尽管使用的视频指令调优数据少得多,但在大多数基准测试中,Magma的表现很有竞争力,甚至超过了Video-Llama2、ShareGPT4Video等先进方法。
Magma成功整合了视觉、语言和行动,在机器人任务操作上表现出了较高的泛化能力。未来,随着模型研究的不断深入及模型规模的扩展,Magma也有望为解决更复杂的机器人操作问题提供不错的解决方案,让机器人距离真正的落地应用更进一步。

(文:智东西)