【新智元导读】在AI行业新诞生的「多模态交互」赛道上,声网发布的「对话式AI引擎」,让所有文本大模型秒变多模态,具备实时语音对话能力,补齐了大模型「失语」的短板。
就在最近,生成式AI行业,诞生了一个新赛道——所有文本模型,可以立刻秒变多模态了!
如今的大模型混战局势,情况已经很明显,去一味卷大模型供应商,投入产出比已经不高。
此时,这个产品的另辟蹊径,就格外显得独树一帜——他们要做的,是让任意大模型开口说话,甚至是DeepSeek!
你有没有想过,DeepSeek如此好用的深度思考+联网模式,如果能用更具真实感的语音对话,会是什么样的体验?
现在,声网的对话式AI引擎,立刻就能实现你的愿望。
传送门:https://www.shengwang.cn/ConversationalAI/v2/
接入DeepSeek V3模型的第一问,那便是自我介绍了——你知道自己很火吗?
DeepSeek非常谦逊地回答道,「我的火与不火,并不是我关注的重点,我的目标是通过高效准确的信息检索和友好的交互体验来帮助用户」。
这个高情商的回复,着实有两把刷子。
《智能赋》
天地生万物,智能启新篇。算法如流水,数据似云烟。
机器通人语,网络连九天。千里传音讯,瞬息解疑难。
昔日梦难圆,今朝皆可攀。科技无穷尽,智慧永流传。
愿此智能力,助我登高巅。共赏星河远,同游宇宙间。
DeepSeek完全复现了诗仙的「五言绝句」的风格。
不仅如此,V3回答的速度飞快,中间也几乎没有卡顿。怎么样,是不是还挺像那么回事的。
人工智能与机器学习领域,位列首位,其次便是绿色能源与可持续发展了。
接下来,测测DeepSeek能不能做自己的「树洞」——我有些生气,你该怎么哄好我?
没想到,它具备了超强的共情能力,「生气会让小仙女掉仙气哦,别担心给你讲几个段子吧」。
并且,还主动给出建议,「深呼吸,听一首最喜欢的歌或者看喜欢的电视剧吧,再给你来一个大大的抱抱。」
不仅如此,中间打断让它说几个有意思的事情,它马上就会做出调整,说几个好玩的事儿逗你开心。比如,「公企鹅会用心形石头向母企鹅求婚,甜蜜爆表!」
怎么样,还挺好玩儿的吧。
接下来,我们换一个模型,使用对话式AI引擎自带的“智能助手”效果,感受下它能够接受被不停打断的压力测试吗?
我们连问了三个问题:有的人不喜欢吃香菜,从科学角度上分析原因;如何和不吃香菜的人共处;榴莲为什么闻着臭,吃着香。
在每次被打断之际,AI同样能够接上话,回答超丝滑。
一波实测下来,长嘴的DeepSeek V3实属不凡。而这背后,对话式AI引擎功不可没。
对于开发者来说,调用声网的对话式AI引擎也非常简单。
只需2行代码、15分钟即可完成接入,大幅降低开发成本,同时保持高度灵活性和可定制性。
不论是DeepSeek,还是豆包、千问、MiniMax,任意文本模型快速转变为对话式多模态大模型,一下子能说会道了起来。
此外,对话式AI引擎也无需绑定公有云,或是自由云模型,让用户有充分的选择自由。
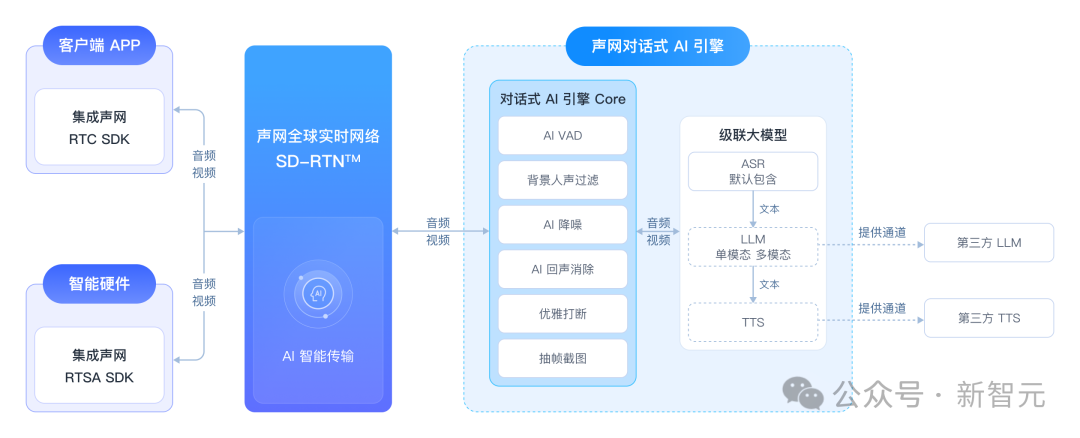
值得一提的是,为了让开发者能够方便地根据自身的喜好或者业务场景选择不同的组件搭配AI Agent,对话式AI引擎采用了灵活可扩展的架构,兼容市场主流的ASR、LLM和TTS技术,并具备工作流编排能力。
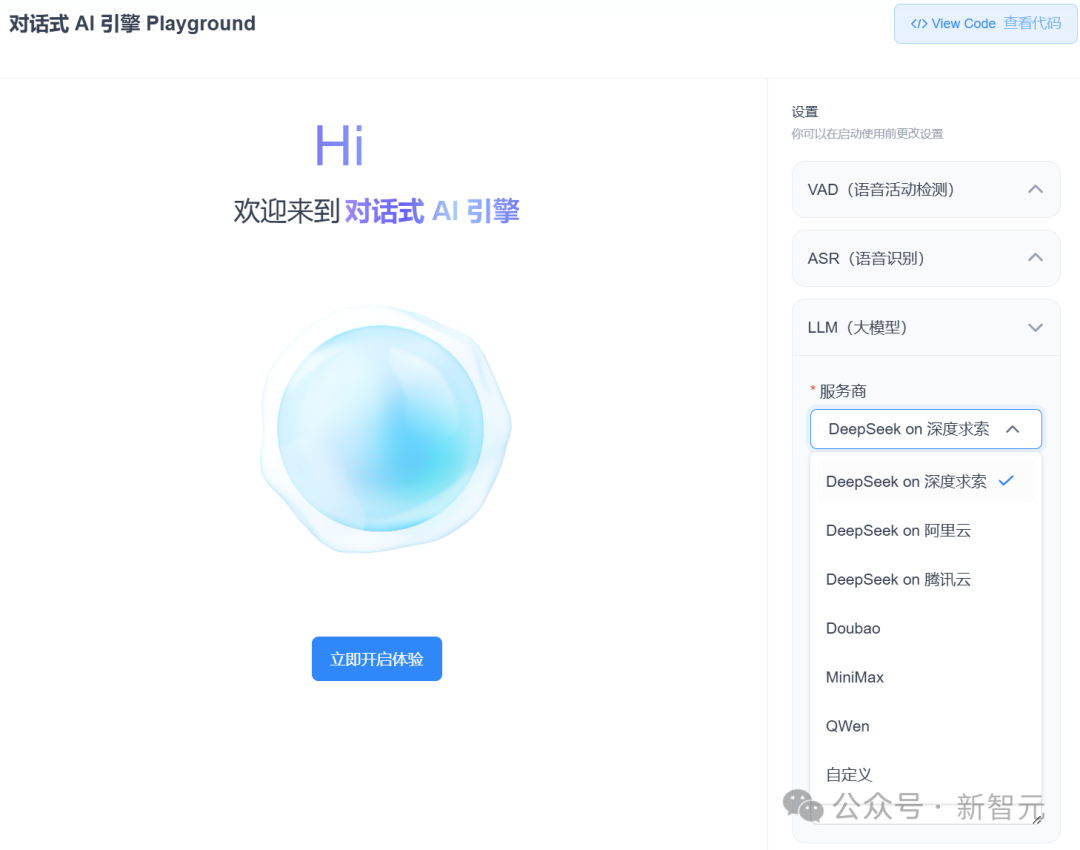
根据声网对话式AI引擎的官方文档,搭建一个智能体非常简便。
从登录声网控制台,创建一个项目,到获取App ID、开通对话式AI引擎,整个流程高效顺畅,无需复杂配置,几分钟即可完成。
文档地址:https://doc.shengwang.cn/doc/convoai/restful/landing-page
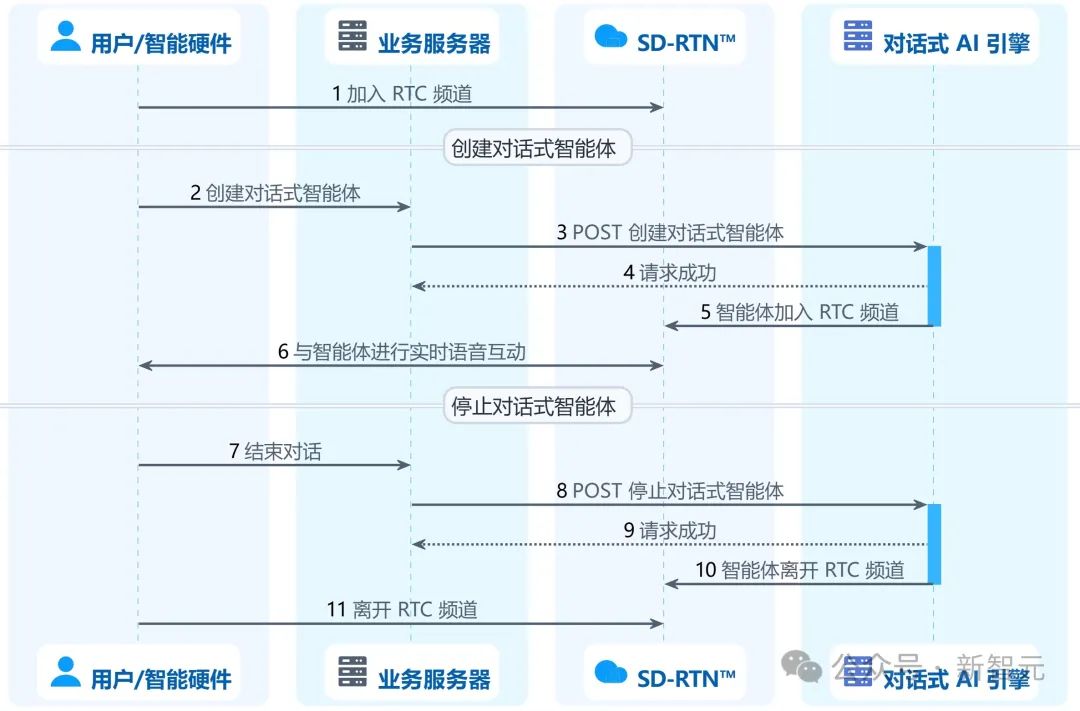
在声网控制台开通服务,获取到必要的ID和密钥后,就可以在应用中加入一个RTC频道,然后调用声网的 「创建对话式智能体」接口API创建一个智能体实例,让其加入同一频道。
最关键的是, 在这个智能体中,不论是大语言模型(LLM)还是文本转语音(TTS)服务,都可以根据你的需求灵活的配置,DeepSeek、千问、豆包、MiniMax,想选哪个选哪个。
停止与智能体实时互动同样简单,只需向声网对话式AI引擎的「停止对话式智能体」接口POST一个请求,调用成功后智能体将离开RTC频道,互动对话就结束了。
服务器繁忙?不存在的
现在使用DeepSeek,遇到最多的情况就是「服务器繁忙,请稍后再试」。
声网对话式AI引擎,会不会也出现类似问题?问题不大,因为我们还可以调用阿里云或腾讯云的满血版DeepSeek。
如此简单的搭建方式,对于开发者来说,人均手里一个Her即将成为现实。
最关键的是,这个Agent具备五大超能力,比ChatGPT更会聊。
首先,它能做到AI语音秒回。因为语音对话延迟低至650ms,全链路的深度优化,让对话无比流畅自然。
其次,它还能锁定对话人声,屏蔽95%的环境人声、噪声干扰。
要知道,环境噪音干扰是一个非常常见的问题,一般LLM会在语音对话中误触打断机制,停止了交互。
对此,声网针对当前LLM语音技术特性,结合多年积累的AI降噪等音频对话处理能力,可以智能屏蔽背景人声、环境噪音等。即便是在地铁、车库等弱网环境下,人与AI也能流畅对话。
值得一提的是,对话式AI引擎误打断较ChatGPT大幅降低50%。
另外,你在和它对话的过程中,会感觉对话节奏仿佛真人一般,可以随时打断,响应已经低至340ms。
就算被打断,对话式AI引擎也能快速接上,这背后是声网自研的AI VAD技术。
就像人类对话中停顿、语气、对话节奏等,在声网真实语音对话中,AI卡壳是几乎不存在的。
此外,对话式AI引擎即便是在80%丢包情况下,依然能稳定交流。
这是因为声网全球首创的软件定义实时网,已在全球200+国家和地区铺开,确保能够丝滑实时交互。
还有声网RTC SDK已经支持30多个平台开发框架,能够适配30000+终端,而且中低端机型覆盖广泛,不存在无法兼容的问题。
基于这些优势,未来语言模型不再是冰冷的AI系统,而会成为每个人生活中的「智能伙伴」。
它不仅能执行指令,还能理解情感、预测需求,甚至在某些场景中成为用户情感价值的寄托。
想象一下,当你感到低落时,虚拟陪伴助手会主动播放舒缓的音乐,模拟真实对话讲述故事,缓解你的孤独。
它还可以成为孩子「口语外教」,纠正发音,营造练习口语氛围的环境。
它还可以是7×24小时最强打工人——智能客服,代替人工坐席,自动受理客户咨询和投诉。
从DeepSeek R1、到Gemini 2.0 Flah Thinking、o3-mini,再到最新的Grok 3出世,科技巨头们不断更迭自家的大模型,试图在追逐AI智能的赛道中拉开差距。
LLM的能力再强,如果无法建立起与人类之间的交互桥梁,终究难以真正落地应用。
当前市场格局下,头部厂商专注于卷参数规模,中小玩家则聚焦于垂类赛道。
而且,LLM大多还停留在「文本生成」单一维度,他们均普遍缺乏实时语音交互的能力。
这种局限不仅仅影响用户体验,更是制约了AI在多个场景中的渗透。
实际上,99%的企业真正的需求并不是自研大模型,而是一个能听、会说的AI。
这些痛点本质,便在于行业过度关注模型「智能」维度,而忽视了「交互」这个关键基建。
正如移动互联网时代,智能手机的普及不仅仅依赖于处理器性能,还需要触控屏、传感器等交互技术的突破。
从技术趋势演进来看,大模型都在朝着多模态方向递进,与之同时,多模态大模型也将经历从「生成」到「交互」的必然演进。
早期以GPT-3为代表的语言模型,专注于文本的生成。随后,以GPT-4o为代表的多模态大模型,具备了理解、生成图像的能力。
要知道,只有专业交互能力的供应商,能以远超自研的效率解决LLM「失语症」的痛点。
产业链重构:多模态交互层崛起
传统AI产业链相对简单:模型供应商提供基础模型能力,算力供应商负责部署,应用开发商构建最终落地产品。
这种模式下,存在着明显的断层,即模型与应用之间的缺少必要的交互层。
声网的创新在于,在模型与应用之间插入一个「多模态交互层」,使得任何文本模型都能迅获得过实时语音对话的多模态能力。
对于企业来说,无需再为获得多模态能力,而被迫选择特定的头部模型;对于开发者而言,同样可以灵活选择最适合业务场景的基础模型,还能获得顶级交互的体验。
声网技术解决方案,恰好顺应了多模态模型演进的趋势,即为任何模型提供实时语音交互能力。
原本只会「吐字」的大模型转变为「能说会道」的小助手,这不是简单语音合成,而是真正实时双向沟通。
上面案例中不难看出,在随时打断、噪声过滤、弱网适应等方面,「对话式AI引擎」全部精准拿捏。

GPT-4o发布会上,为了保证演示畅通性,手机还插上了网线
在去年十月RTE2024第十届实时互联网大会上,声网首席科学家钟声现场演示了一个由STT、LLM、TTS 、RTC四个模块组成的端边结合实时对话AI智能体,这也是全球首次有厂商在比日常实际场景更具挑战的环境下展示实时AI 对话能力。
现场观众规模超过千人,面临复杂的噪声、回声、麦克风延迟等困难,但智能体与钟声的互动仍然表现出了优秀的对话能力。
在普通5G网络环境下,实现了流畅、自然、有趣的双向实时对话,对话模型的极快响应速度、及时打断与被打断的自然程度、对抗噪声能力、遵循语音指令做等待能力都非常突出。
在这个交互基建赛道中,作为实时互动(RTE)领域的领军企业,声网积累了深厚的技术底蕴。
IDC数据显示,其在RTC市场份额位居中国市场第一。
他们创造了全球首个、迄今为止规模最大的实时音视频网络——软件定义实时网SD-RTN™。
它具备了毫秒级响应、超低延迟,和极致抗弱网的能力,能够确保高质量的实时交互体验。
不仅如此,凭借深厚技术积累和全球化服务能力,声网还赢得了国内外头部大模型厂商的高度认可。
在海外,其兄弟公司Agora已成为OpenAI官方合作伙伴,共同推动在实时API的落地应用。
在国内,MiniMax、通义千问等顶尖大模型公司也与声网建立了紧密合作关系。
这些合作不仅彰显了声网在实时语音技术上领先地位,也进一步巩固了其在全球市场的领导地位。
成立十年来,几乎每一个行业风口都有其身影。有人说,它是科技淘金时代的「卖水者」。
从陌陌、斗鱼、虎牙到Bilibli,这些直播行业的巨头都曾选择声网作为技术合作伙伴。它提供的技术不仅保障直播流畅性和稳定性,更在用户体验上梳理了行业标杆。
在新东方、好未来、VIPKID等教育巨头背后,声网也提供了强大得技术支持。
无论是大规模在线课堂,还是一对一个性化教学,它都能确保师生之间实时互动,提升教学效果。
此外,在全球化布局方面,声网也取得了重要的成果,全球超60%泛娱乐APP都是其客户。这些基础也为声网积累了丰富的客户服务经验。
眼光放长远来看,声网的创新将为整个行业带去更深远的影响和价值。
通过提供标准化的交互能力,它能解决中小厂商被头部玩家「功能碾压」的焦虑。
即便是资源有限的创业团队,也能通过接入专业交互层,提供与科技巨头相媲美的用户体验。
不仅如此,由于降低多模态交互技术门槛,更多开发者能够专注于场景创新、业务模式探索,而不必陷入底层交互技术的泥潭。
此外,AI在多场景落地也会得到加速。AI智能助手、情感陪伴、AI口语陪练等应用场景,因获得高质量交互能力的支持,可以更快速地规模化部署。
随着交互基建的铺开,我们将看到更多AI应用从实验室走向生活,从冰冷的文本界面,演进为温暖自然的对话伙伴。
在AI竞争下半场,语音交互也将成为一决胜负的关键砝码。
(文:新智元)