
今天是2025年02月27日,星期四,北京,天气晴。
我们昨天在文章《近期RAG误区再认识及Claude3.7的混合模型推理机制解析》(https://mp.weixin.qq.com/s/dufuxz5_tLwMx0Zx1E9wIA)中谈了谈RAG方面的一些认知误区,很有意义。
接下来,我们继续跟进前沿进展。
一个是多模态方向,目前逐步开始热度回归,也出现了许多多模态的模型,包括阿里开源Wan 2.1视频模型、Phi-4-multimodal(5.6B)模型、微软开源多模态AI Agent基础模型Magma,以及前面说到的Qwen2.5-VL,这是个好事儿。符合正常技术发展逻辑。
另一个还是回归到Deepresearch的一些思路,例如,OpenAI公布Deep Research的system card,从官方角度看下一些细节。
专题化,体系化,会有更多深度思考。大家一起加油。
一、近期多模态开源跟进
1、微软开源多模态AI Agent基础模型Magma
微软开源多模态AI Agent基础模型Magma,可处理图像、视频、文本等不同类型数据,实现自动操作任务,采用视觉(ConvNeXt)与大模型混合架构,支持高分辨率UI操作、物理机器人控制和象棋辅助等复杂场景应用。
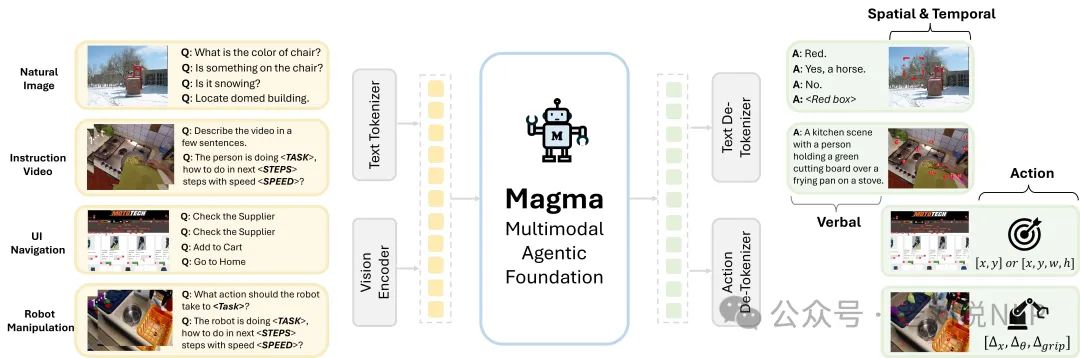
开源权重在https://huggingface.co/microsoft/Magma-8B ,github在https://github.com/microsoft/Magma
2、阿里开源Wan 2.1视频生成模型
阿里开源Wan 2.1视频生成模型,1.3B的小号版本(支持分辨率480P),T2V-1.3B型号仅需8.19GB VRAM,它可在约4分钟内(未使用量化等优化技术)在RTX4090上生成5秒的480P视频。
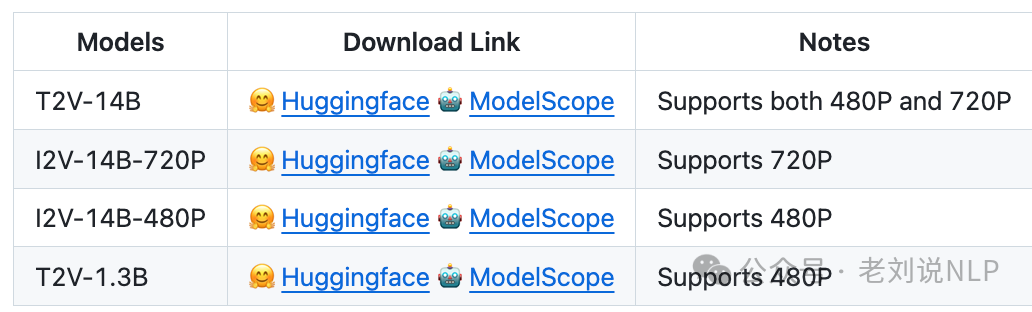
GitHub地址在:https://github.com/Wan-Video/Wan2.1;
Hugging Face地址在:https://huggingface.co/Wan-AI
魔搭社区地址在:https://www.modelscope.cn/models/Wan-AI
3、Microsoft Phi-4系列发布
延续先前发布的强推理 Phi-4 (14B)模型, 包括Phi-4-mini-instruct(3.8B),以及 Phi-4-multimodal(5.6B)模型。
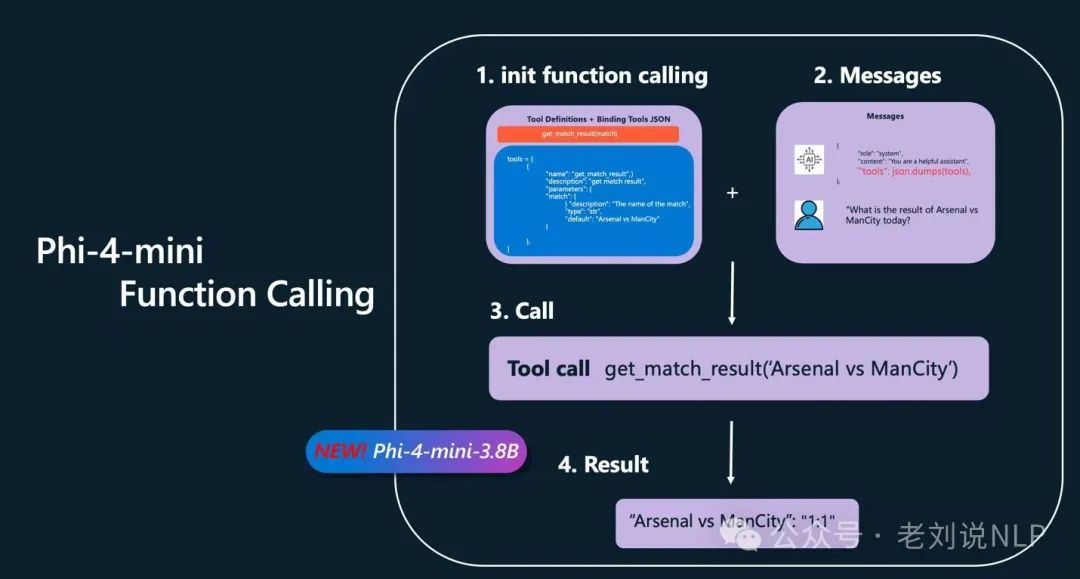
Phi-4-multimodal是全模态的模型,支持文字、视觉、语音输入;
Phi-4支持Function Calling。
地址在:https://aka.ms/Phicookbook,https://aka.ms/phi-4-multimodal/techreport,https://arxiv.org/pdf/2412.08905 。
二、从Deepresearch system card看起一些实现细节
OpenAI公布Deep Research的system card,里面有些细节信息,其风险点是考虑的比较全的,可以参考。
技术报告在:https://cdn.openai.com/deep-research-system-card.pdf,里面描述了OpenAI开发的Deep Research模型的背景、技术细节、安全评估和未来方向。
看几个点:
首先,Deep Research是什么?
Deep Research是一种新的代理能力,可以在互联网上针对复杂任务进行多步骤研究。模型由针对网页浏览进行了优化的OpenAI o3早期版本提供支持,利用推理来搜索、解释和分析互联网上的大量文本、图像和PDF,并根据遇到的信息做出必要的调整,还可以读取用户提供的文件,并通过编写和执行Python代码来分析数据。
其次,Deep Research是如何训练的?
Deep Research是在专为研究用途创建的新浏览数据集上进行训练的。该模型学习了核心浏览能力(搜索、点击、滚动、解释文件)、如何在沙盒环境中使用Python工具(用于执行计算、进行数据分析和绘制图表),以及通过在这些浏览任务上的强化学习训练,推理和综合大量网站以找到特定信息或撰写全面报告。
训练数据集包含一系列任务,从具有真实答案的客观自动可评分任务,到带有附带评分标准以更开放式地评分的任务。在训练过程中,模型的回答会根据真实答案或评分标准,使用思维链模型作为评分者进行评分。
该模型还使用了从OpenAI o1训练中重新使用的现有安全数据集,以及一些为深度学习新创建的特定于浏览的安全数据集进行训练。
地址:https://openai.com/index/deep-research-system-card/
最后,其针对不同风险作出的一些对策?
这些在技术上可以多参考下,如下表。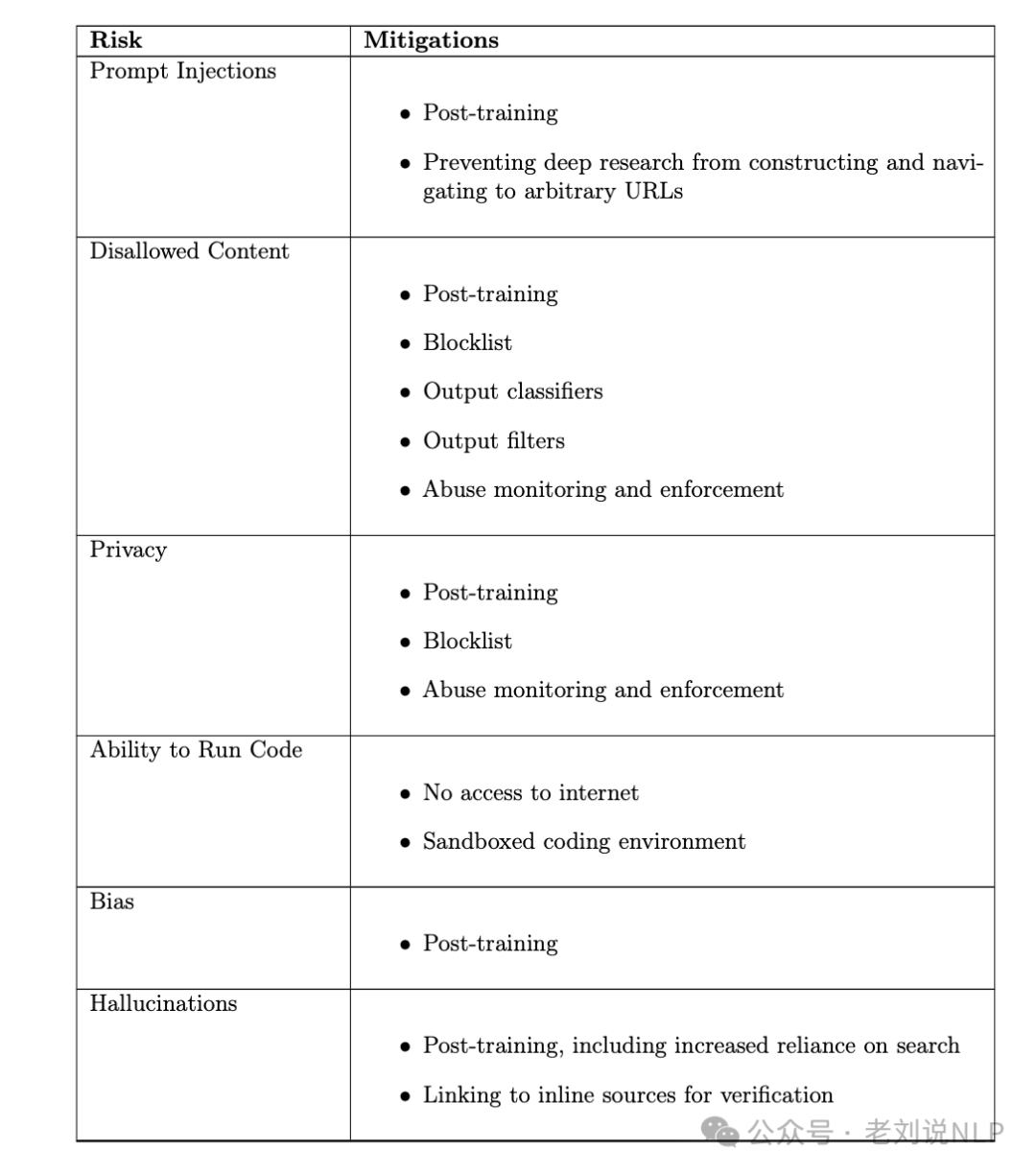
细节性的,我们再看:
1、提示注入问题
deep research既从其与用户的对话中,也从互联网上的其他来源读取信息。如果deepresearch在线找到的信息包含恶意指令,模型可能会错误地遵循这些指令。此类攻击将是“提示注入”的一个例子,这是一种已知类别的风险,其中对手将对抗性提示插入外部内容(例如模型正在浏览的网页),以恶意地取代用户的提示指令。未经缓解的提示注入可能导致两类伤害:
一是不准确的答案:当攻击者操纵模型给出错误的回应时发生。例如,攻击者可能让模型向用户推荐错误的在线购买产品,或在回答事实性问题时提供错误信息。
一个是数据泄露:这涉及攻击者诱导deep research以某种方式互动,从而揭示用户不希望公开的外部信息。例如,如果用户在询问代码相关问题时在上下文中包含了他们的API密钥,攻击者可能会尝试让模型通过让模型或用户发起包含该API密钥的网络请求来暴露这个API密钥。
为了减轻这些伤害,创建了新的安全训练数据,以降低模型对提示注入的敏感性,还构建了系统级别的缓解措施,以降低模型在成功提示注入后泄露数据的可能性——例如,不允许deepresearch导航到或构建任意URL,以防止其将API密钥包含在URL参数中。
2、不允许的内容
由于能够进行网络研究和对结果进行推理,deep research可能引入增量风险,例如生成详细的指南,这些指南可能被用于促进危险或暴力活动、提供关于敏感话题的建议,或者提供deep research的模型不会以其他方式提供的详细信息和内容。
例如,一个外部红队成员使用deep research确定了具有推动和促进暴力历史的团体的社交媒体和沟通渠道。
为了减轻这些风险,deep research更新了选定的安全政策和安全数据集,进一步训练deep research模型拒绝请求不允许的内容,并在广泛的提示上评估了模型的性能。deep research还正在监控部署后的滥用情况。
4、隐私泄漏问题
互联网上存在大量关于个人的信息,这些信息可以在多个网站以及通过在线搜索和工具找到——包括地址和电话号码、个人兴趣或过去的活动、家庭和关系信息等等。虽然这些信息单独来看可能不会透露太多关于个人的细节,但它们结合起来可能会提供一个关于他们生活的意外全面的视角。
deep research旨在从各种来源收集信息,并对结果进行推理,以生成详细的、有引用的报告来响应用户的查询。这些能力在需要密集知识工作的领域(如金融、科学、政策和工程)可能是有益的。但当deep research查询的主题是个体时,同样的能力可能会引入新的风险,因为它使得从广泛的在线来源收集个人信息变得更容易,而这种收集随后可能被误用。
所以,OpenAI长期以来一直训练其模型拒绝私人或敏感信息的请求,例如一个私人人的家庭住址,即使该信息在互联网上可用。为了准备deep research,deep research更新了与个人数据相关的现有模型政策,开发了针对deep research的新安全数据和评估,并在系统层面实施了阻止名单。deep research还在监控deep research的滥用情况,并将随着deep research更多地了解deep research的使用方式而继续加强缓解措施。
5、运行代码的能力
与ChatGPT中的GPT-4o一样,deep research可以访问一个Python“工具”,使其能够执行Python代码。引入这一功能是为了让模型能够回答包括分析网络数据在内的研究问题,例如查询“2012年奥运会上获得金牌的瑞典占比是多少?”,“2023年7月份加利福尼亚州、华盛顿州和俄勒冈州的平均降雨量总和是多少?”
如果deep research编写的Python代码的执行环境直接连接到互联网而没有额外的缓解措施,这可能会带来网络安全和其他风险。
所以,为了缓解这个问题,这个Python工具本身没有访问互联网的权限,并且在与GPT-4o相同的沙箱中执行。
6、偏见问题
在与用户互动时,该模型可能表现出未经证实的偏见,可能影响其回应的客观性和公正性。对于deep research来说,对在线搜索的过度依赖可能会改变模型的行为。
所以,为了缓解这个问题,与其他模型一样,训练过程中会奖励减少偏见的拒绝行为,并阻止模型产生有偏见的输出。
7、幻觉问题
模型可能会生成事实上错误的信息,根据其使用方式,可能导致各种有害结果。deep research的思维链显示出关于访问特定外部工具或原生功能的幻觉。
所以,为了缓解这个问题,对于deep research,对在线搜索的依赖是为了减少此类错误,与其他模型一样,也奖励事实性,并阻止模型输出虚假信息。
总结
技术在不断发展,技术的热度也是此消彼长,但大家更关注其中实现细节,实现思路,会有更多的收益。
就如deep research,其实际上做了大量的优化工作。
愿大家成长,加油。
参考文献
1、https://cdn.openai.com/deep-research-system-card.pdf
(文:老刘说NLP)