

-
论文标题:BIG-Bench Extra Hard
-
论文地址:https://arxiv.org/pdf/2502.19187
-
数据地址:https://github.com/google-deepmind/bbeh


-
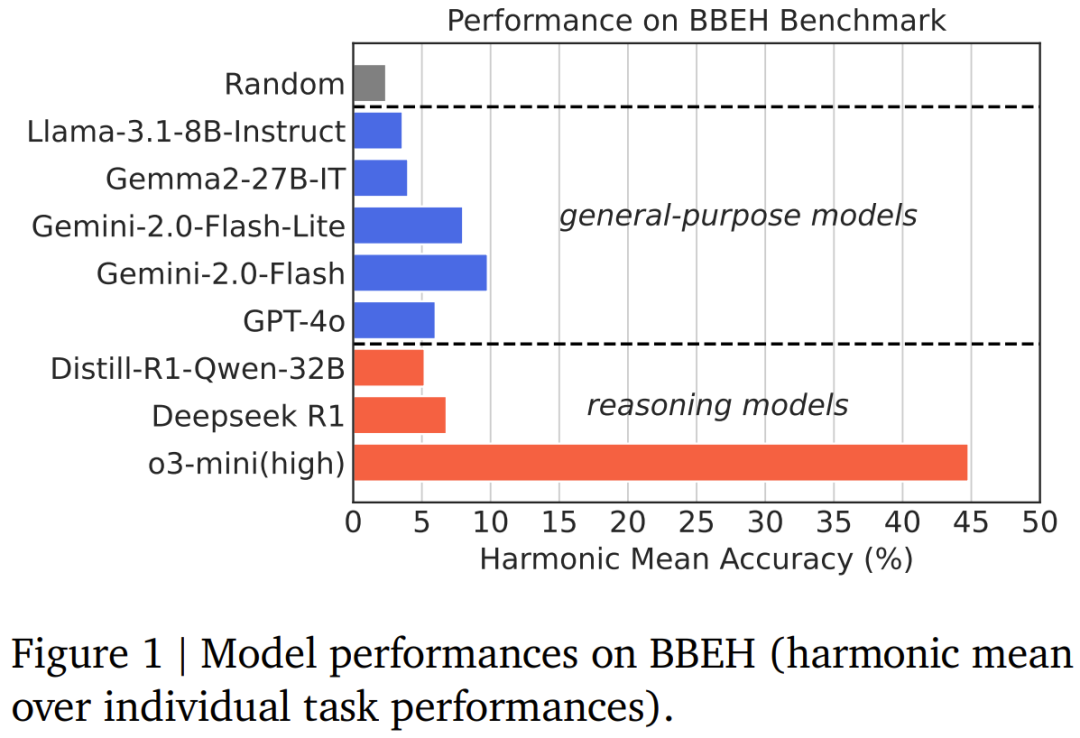
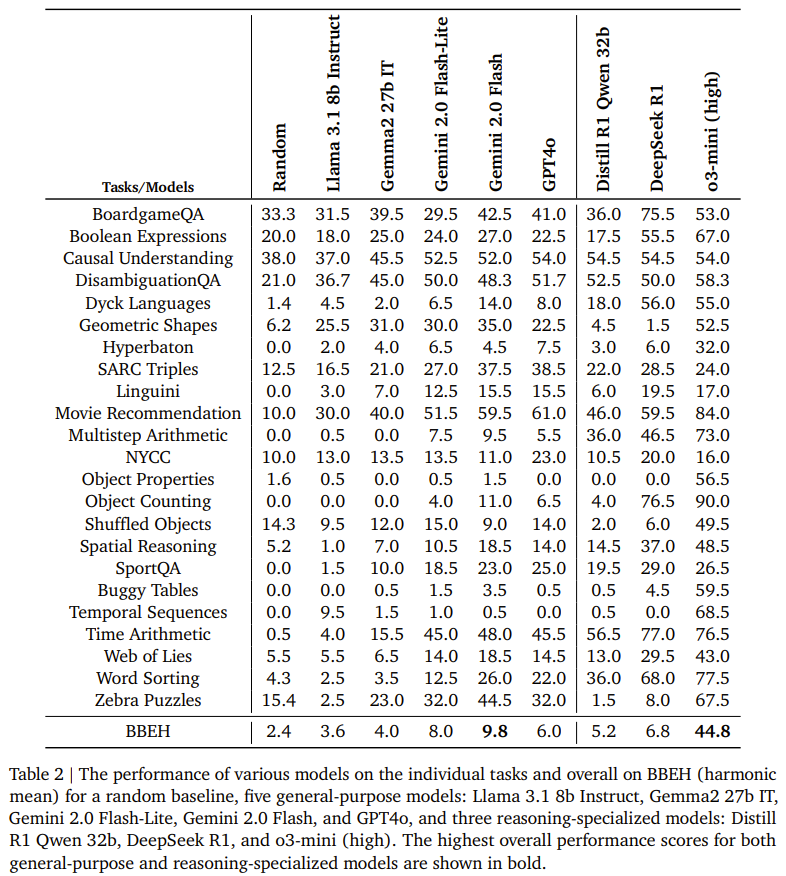
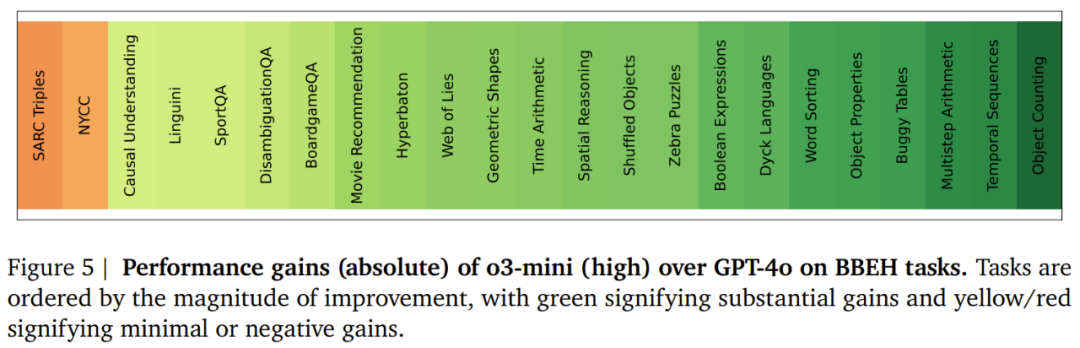
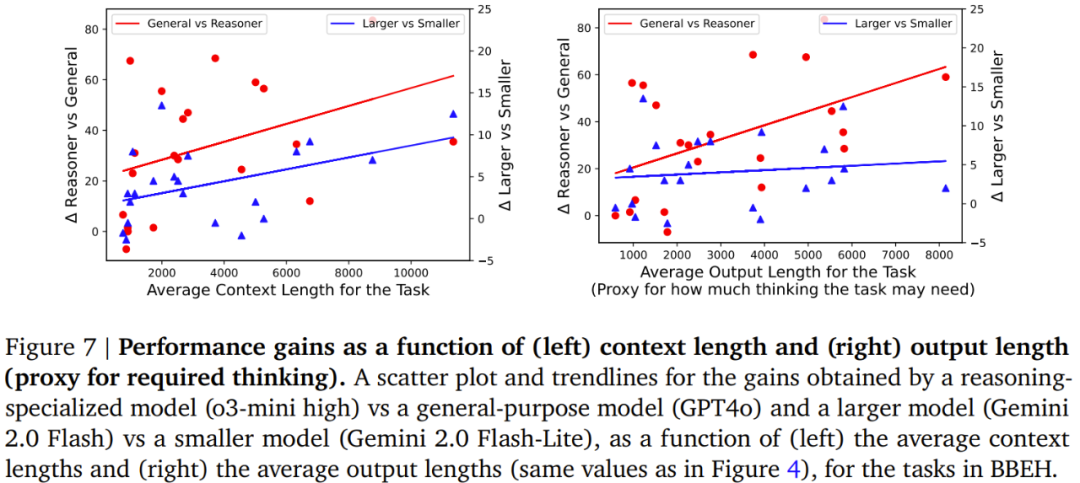
模型在各个任务上都有很大的进步空间,在 BBEH 整体上也是如此。 -
通用模型的最佳性能为 9.8% 的调和平均准确率。推理专用模型在该基准上的表现优于通用模型(符合预期),但这些模型在 BBEH 上的最佳性能仍只有 44.8%。 -
尽管采用了对抗性结构,但参考 Thinking 模型在 BBEH 上的调和平均准确率仍只有 20.2%。 -
一些模型的准确率甚至低于随机性能。经检查,他们发现原因大多是模型无法在有效输出 token 长度内解决问题并在某个点之后开始退化,因此无法从其解答中提取出最终答案。

(文:机器之心)