


近期,多模态大模型(MLLMs)发展迅速,但开源模型在长上下文场景(如长视频或高分辨率图像)中仍显著落后于闭源模型。部分专注于长上下文场景的开源模型在短上下文场景(如短视频或静态图像)中又表现不佳。
为此,腾讯优图实验室和南京大学等联合推出全开源、可复现的多模态大模型 Long-VITA,原生支持 4096 帧图像或者 100 万 Tokens 输入,在支持长上下文场景的同时,保持短上下文场景的优异表现。在单机推理上,实现推理长度扩展 417% 和推理速度降低 47.3%。

论文链接:
代码链接:

背景介绍
-
上下文限制:模型的上下文窗口较小,无法处理长序列输入,在长视频理解等任务中受限;
-
性能退化:为了扩展上下文,一些模型采用视觉 tokens 压缩、稀疏 self attention 和位置编码外推等技术,影响了模型在精细视觉任务中的表现;
-
多任务平衡:大部分开源长视频模型在图像理解上效果不佳,忽略长视频理解和单图理解间的平衡。
-
原生支持 4096 帧图像、一百万 Tokens 输入:模型采用全参训练,不用任何参数高效微调方法;不压缩视觉 tokens;不采用稀疏 attention;不使用位置编码外推;
-
支持长上下文的同时,保持短上下文效果优异:在 OpenCompass、Video-MME、LongVideoBench、MVBench 等不同场景的 Benchmark 上表现优异;
-
只用开源数据训练,效果超过使用非公开数据训练的主流模型:表明了开源数据的价值以及开源模型的巨大潜力;
-
完全开源可复现:除了开源模型权重,还开源训练数据、训练代码和测试代码,为社区提供一个完全透明、开放的研究基准;
-
训练和推理流程全国产化:采用 MindSpeed 和 MindSpeed-LL 框架在 Ascend NPU 上实现模型训练和推理。同时提供 GPU 平台适配代码。在 8 卡 96G 显卡的机器上,实现推理长度扩展 417% 和推理速度降低 47.3%;

模型架构
Long-VITA 采用经典的 Vision Encoder – Vision Projector – LLM 架构。
Vision Encoder:采用 InternViT-300M,并针对不同长宽比的图像进行动态切分。
Vision Projector:采用两层的 MLP,并使用 pixel shuffle 减少 visual tokens 数量。
LLM:采用 Qwen2.5-14B-Instruct。

训练数据
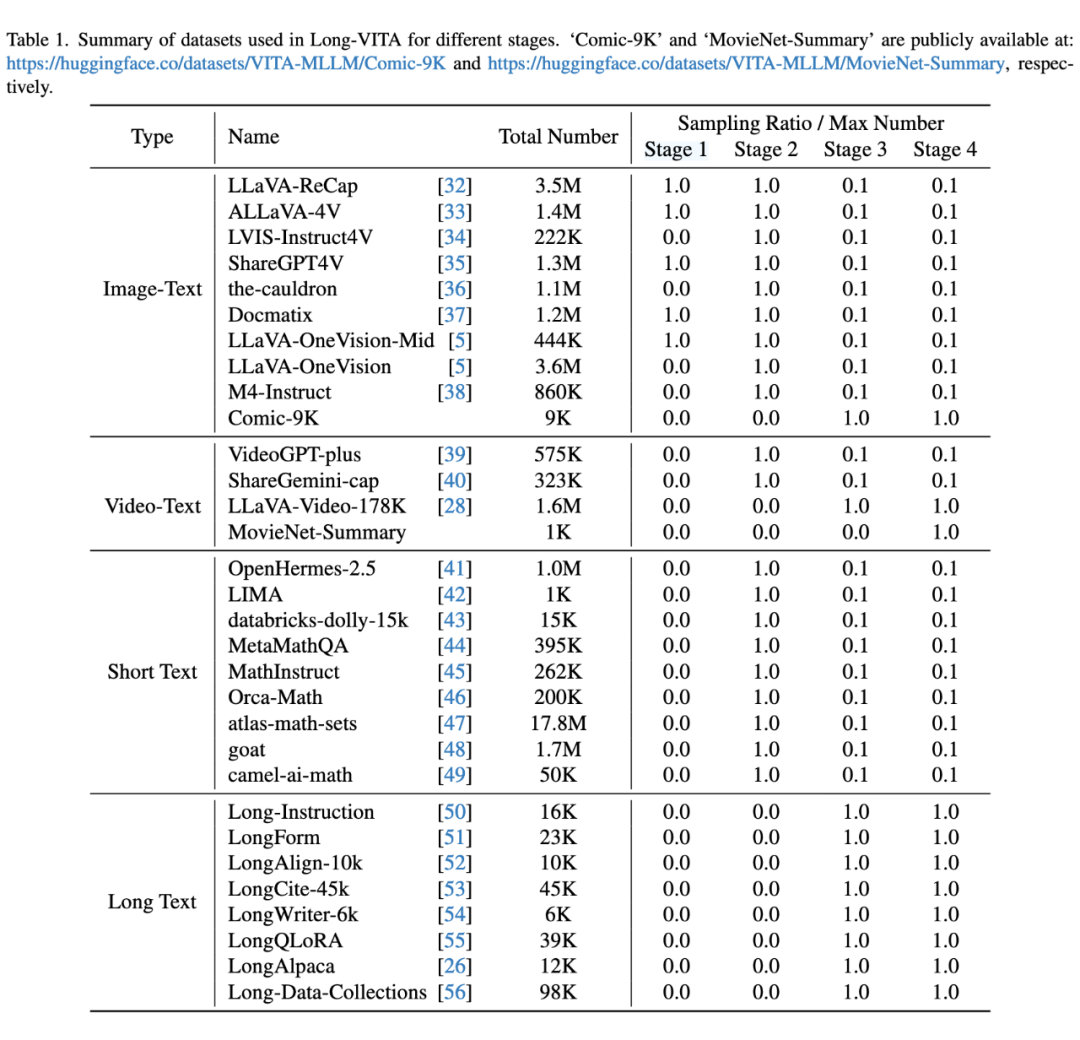
Long-VITA 只采用开源数据进行训练,没有采用数据过滤操作。
不同训练阶段的数据配比不同。其中包括:
Image-Text Data:包括图像描述数据,如 LLaVA-ReCap、ALLaVA-4V 等;视觉问答数据,如 LVIS-Instruct4V、the-cauldron 等;图文交织数据,如 M4Instruct 和 Comic-9k,其中 Comic-9k 为项目收集的漫画及对应的故事梗概,单条数据超过 10 张图像,已在 Huggingface 平台开源。
Video-Text Data:包括 VideoGPT-plus、ShareGemini、LLaVA-Video-178K,以及项目从 MovieNet 中整理的电影级别长度的视频理解数据 MovieNet-Summary,已在 Huggingface 平台开源。
Short Text Data:包括 OpenHermes-2.5、LIMA、databricks-dolly-15k 等较短的纯文本数据集。
Long Text Data:包括 Long-Instruction-with-Paraphrasing、LongForm、LongAlign-10k 等超长的纯文本数据集,旨在将 LLM 的长上下文能力迁移至多模态领域。

训练流程
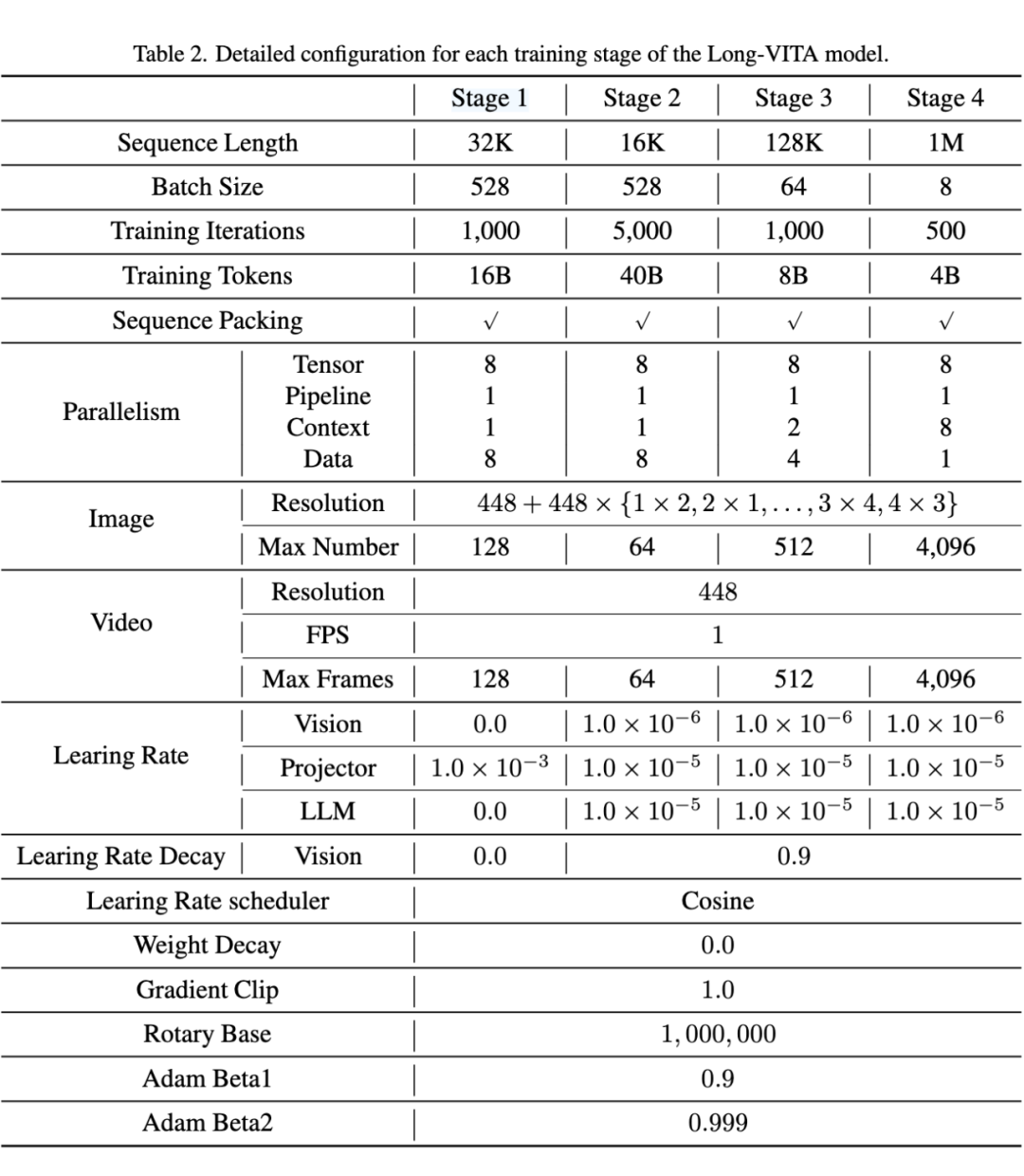
阶段一:视觉-文本对齐
该阶段旨在实现图像表征与 LLM 输入文本空间的初步对齐。只训练 Vision Projector。训练数据主要为图像描述数据和文档类型数据。
阶段二:通用知识学习
该阶段旨在促进模型对通用视觉-文本知识的学习。训练全部模块。训练数据包括图像-文本,视频-文本,纯文本数据,数据长度较短。采用 Packing 技术将多条数据拼接至固定长度,同时修改位置编码和 Attention Mask 确保数据彼此独立,以最大程度利用计算资源。
阶段三:长序列微调
该阶段将模型的上下文长度扩展至 128K。训练全部模块。训练数据中降低长度较短数据的比例,引入长度较长的漫画、视频、文本数据。采用 Packing 技术,但不修改位置编码和 Attention Mask。
阶段四:超长序列微调

推理扩展
Long-VITA 设计了两种提高模型在推理阶段能处理的 tokens 数量的实现:
Context-Parallelism Distributed Inference:结合张量并行(Tensor Parallelism)和上下文并行(Context Parallelism)实现分布式推理,支持处理无限长输入序列。
Logits-Masked Language Modeling Head:对 LLM 最后一层的输出特征进行屏蔽,只将需要预测下一 token 的输出特征送入 LM_head,显著降低了内存消耗。



实验评估
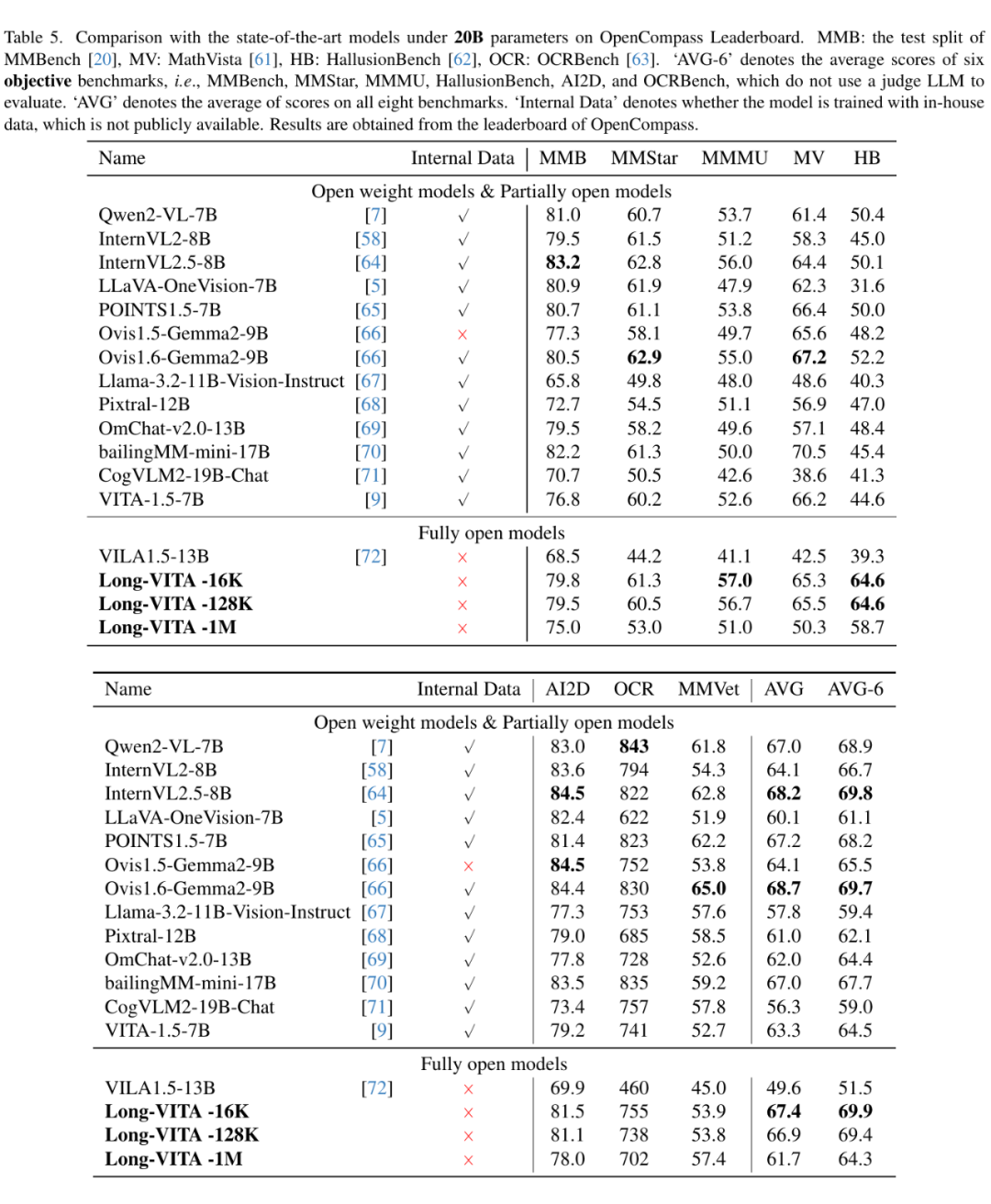
Long-VITA-16K 在 OpenCompass 的 8 个 Benchmark 上表现优异,超越了许多开源模型,尤其在处理多图像任务时展现出强大的能力。
但 Long-VITA-1M 的表现略逊于 Long-VITA-16K 和 Long-VITA-128K,这可能是由于在 1M 训练中未修改 Attention Mask 来隔离样本导致了不同数据样本的混淆。Long-VITA 展示了使用开源数据训练也能实现与私有数据训练相媲美的强大性能。
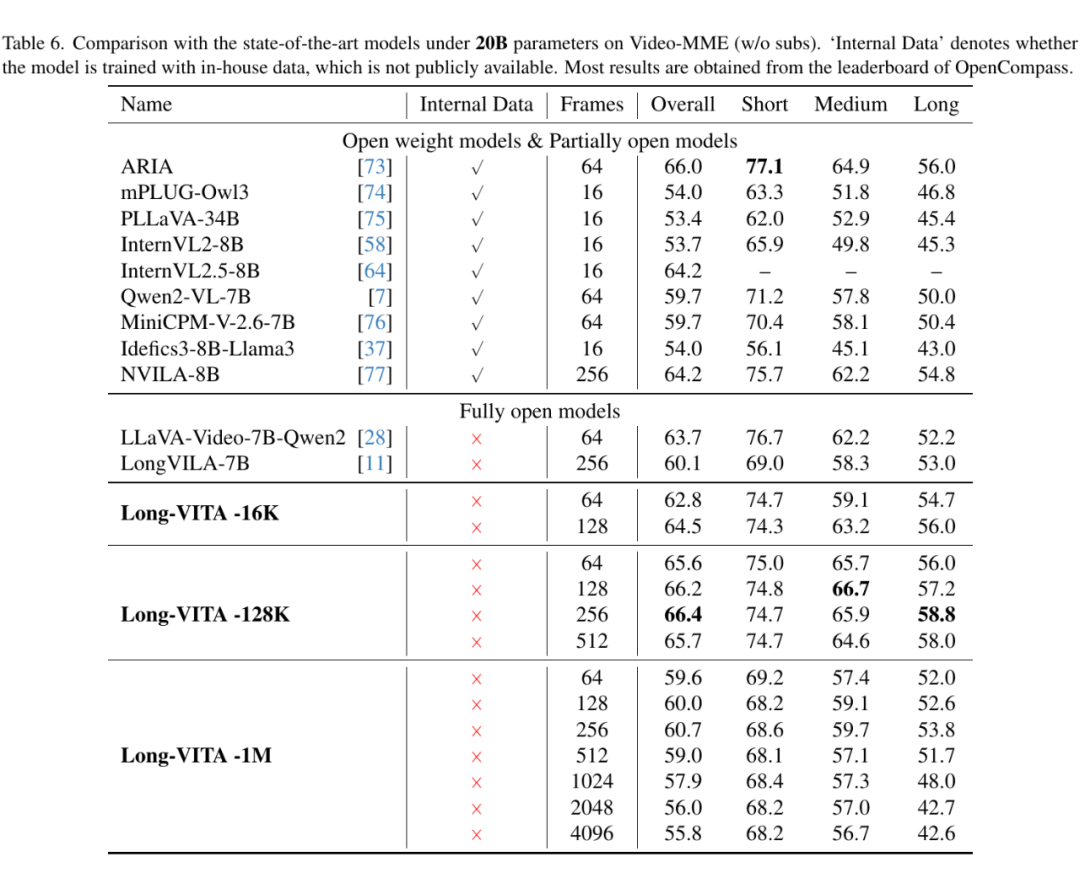
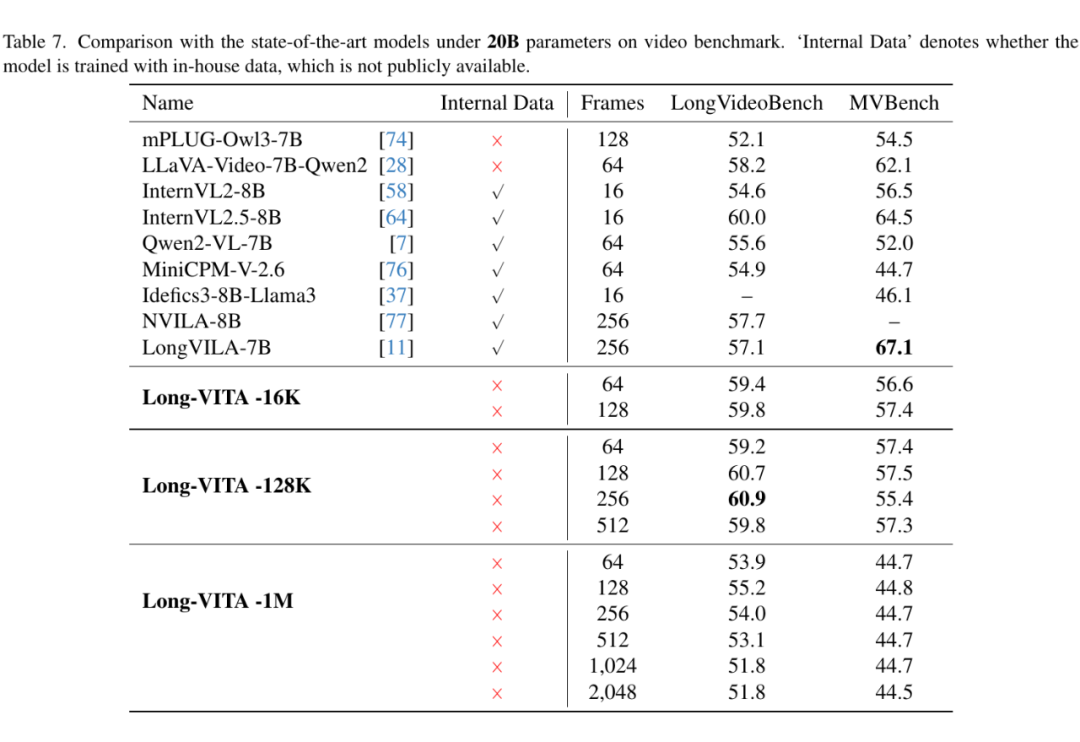
视频理解评估

未来工作
Long-VITA 完全基于开源数据,在长视觉上下文和短视觉上下文中均展现出优异的性能,在各种视频和图像理解任务中处于领先地位。未来 Long-VITA 将采取多模态长上下文数据扩充过滤、训练流程优化等手段进一步改善模型性能。
(文:PaperWeekly)