
推理模型有了原子思维,性能暴增!
来自香港科技大学广州校区的研究人员刚刚放出了一个重磅炸弹!
他们提出的「原子思维」(Atom of Thoughts,AOT)让GPT-4o-mini在HotpotQA上的F1分数达到了80.6%,直接超越了o3-mini和DeepSeek-R1!
这不是简单的性能提升,而是一种全新的思维范式,让AI推理变得更加高效、准确。
为什么需要原子思维?
目前所有推理方法都有一个致命缺陷:它们在推理过程中保存了完整的历史记录。
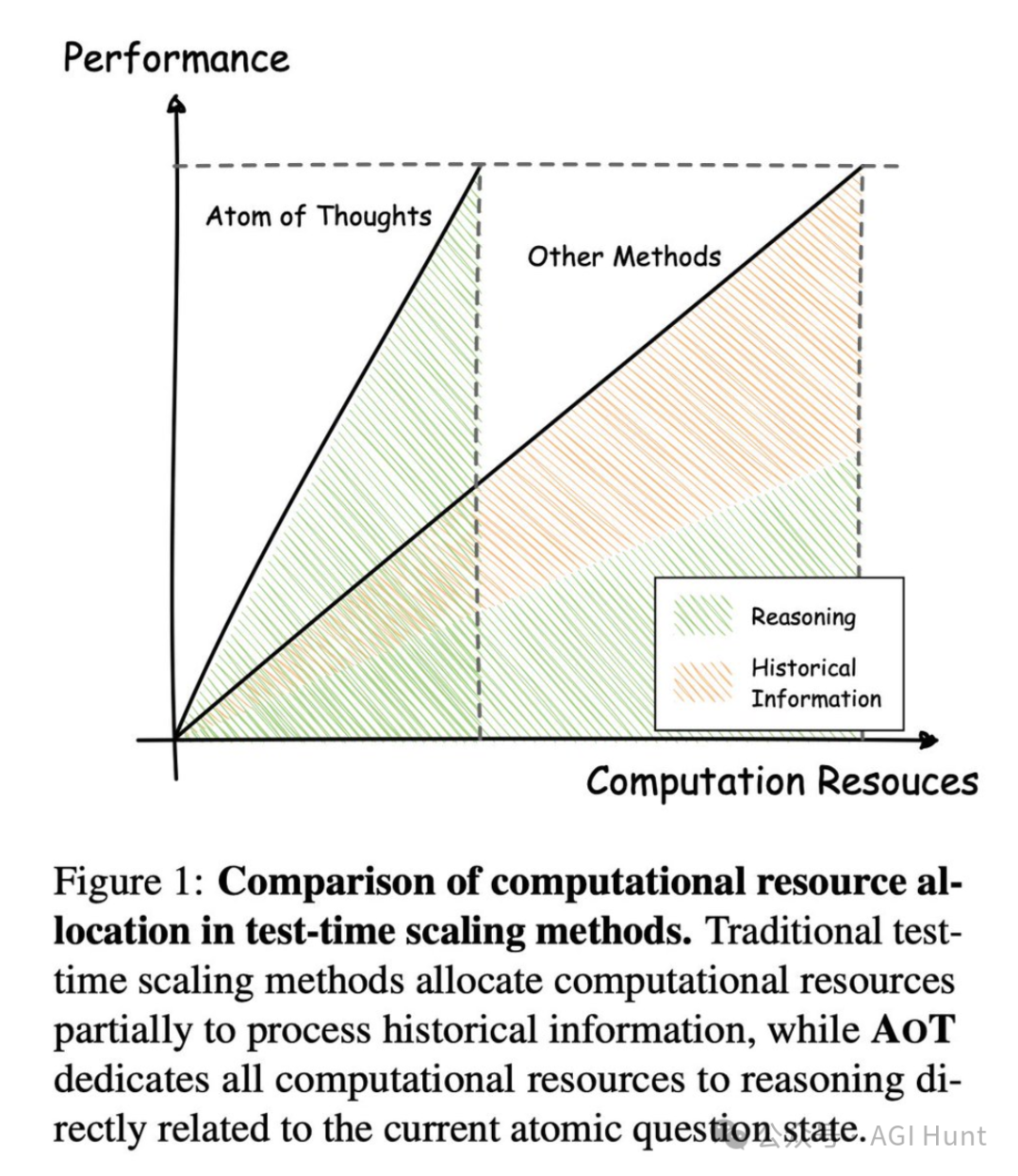
不管是模型(o3、R1等)还是框架(CoT、ToT、GoT等),都像拖着沉重行李箱的旅行者,每走一步都要背着所有历史包袱。
这导致了两个严重问题:
-
计算成本高昂 💰
-
容易产生干扰 🚫
而人类思考可不是这样的!我们用独立的思维单元,不需要时刻回顾完整历史。
原子思维如何工作?
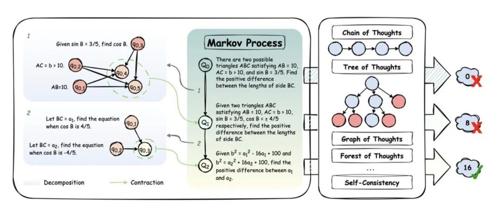
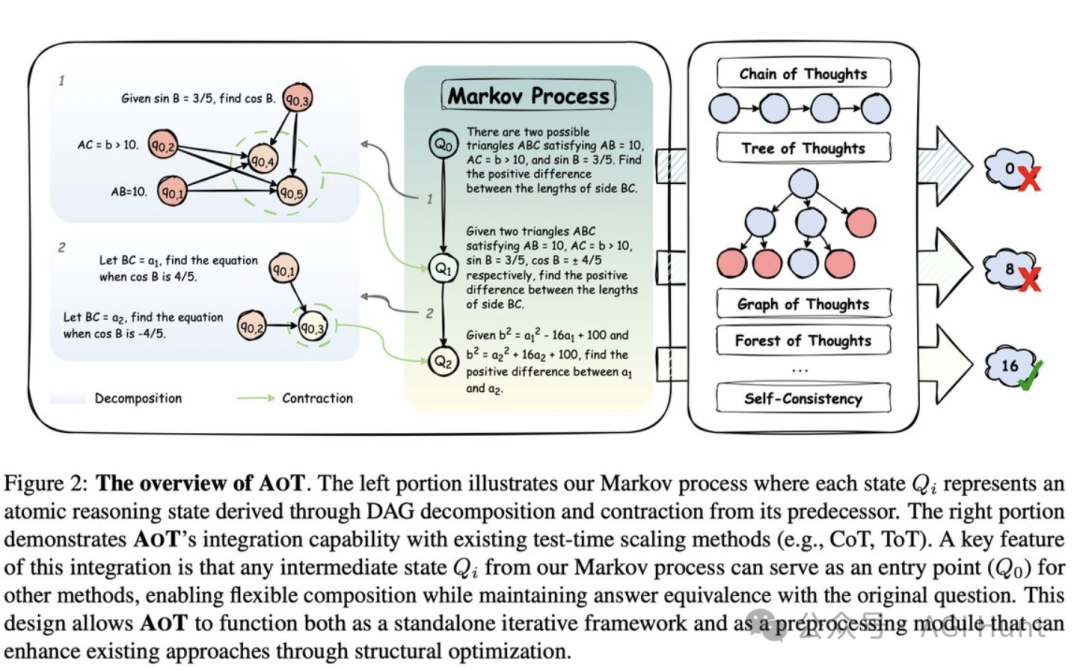
AOT的核心理念是将复杂问题分解为「原子级」的子问题,实现马尔可夫过程式的推理——每个新状态只依赖于前一个状态,而不是整个历史。

具体来说,AOT在每个推理步骤中:
-
将问题分解为有向无环图(DAG)
-
将子问题缩合为一个全新的更简单问题
-
不断迭代,直到达到可直接解答的原子问题
就像物理学中的原子一样,这种方法将复杂思维分解为最基本、不可再分的单元,实现了更高效的推理。
技术实现原理
从论文中我们可以了解到,AOT将复杂推理过程表示为原子问题的组合。
这种方法将推理转变为具有原子状态的马尔可夫过程,状态转换使用两阶段机制:
-
首先将当前问题分解为基于依赖关系的临时有向无环图
-
然后将其子问题缩合以形成新的原子问题状态
这种迭代分解-缩合过程持续进行,直到达到直接可解的原子问题,自然实现了问题状态之间的马尔可夫转换。
这种设计使得AOT能够专注于真正需要解决的问题,而不是像传统方法那样在每一步都处理累积的历史信息。
而正好有网友提问:「我甚至不尝试理解这个,但基本上它可以用更少的计算获得相同的结果?」
——是的,这正是AOT的核心优势之一。
通用插件,适配任何框架
AOT最强大之处在于它是一个通用插件,可以与任何现有方法无缝集成:
-
适用于各种模型:o3、R1等
-
适用于各种框架:CoT、ToT、GoT、Self-Consistency等
-
甚至可以用于代理工作流
它通过简化输入同时保持解决方案质量,让任何推理方法都能得到提升。
这种设计让AOT不仅是一种独立的推理方法,更是现有方法的强力增强器。
实验性能爆表
实验结果令人震惊!在HotpotQA上:
-
AOT让GPT-4o-mini达到80.6%的F1分数
-
超越o3-mini 3.4%
-
超越DeepSeek-R1高达10.6%
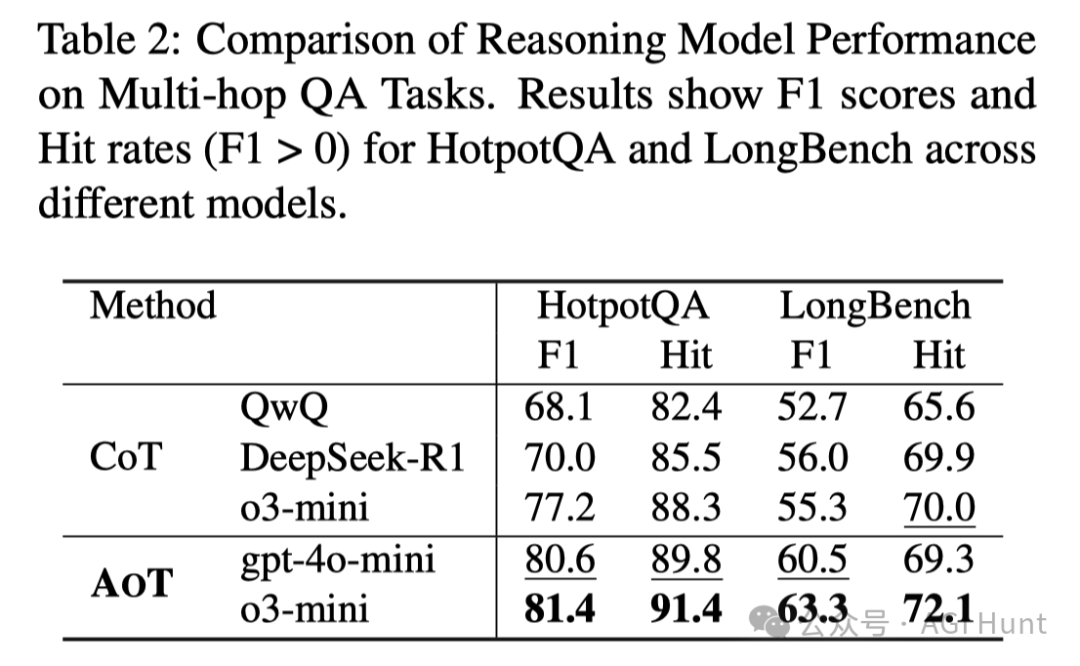
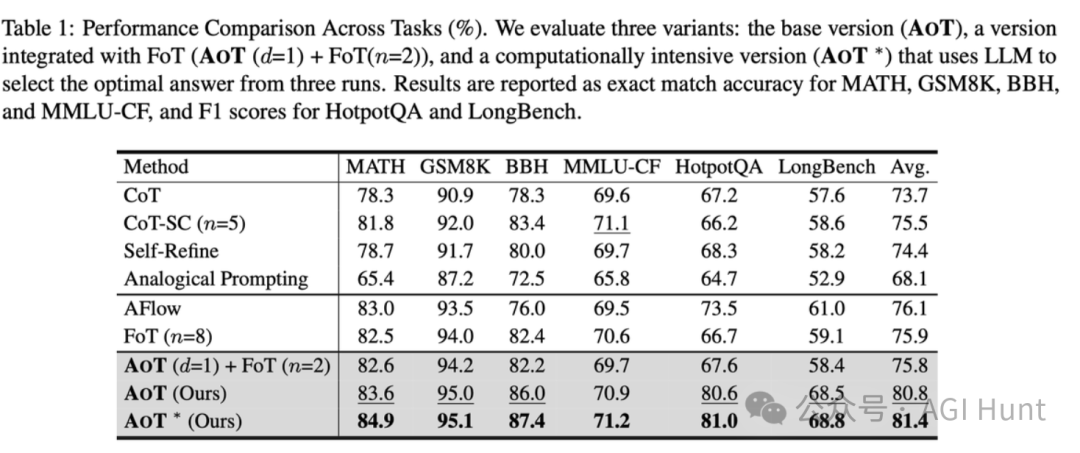
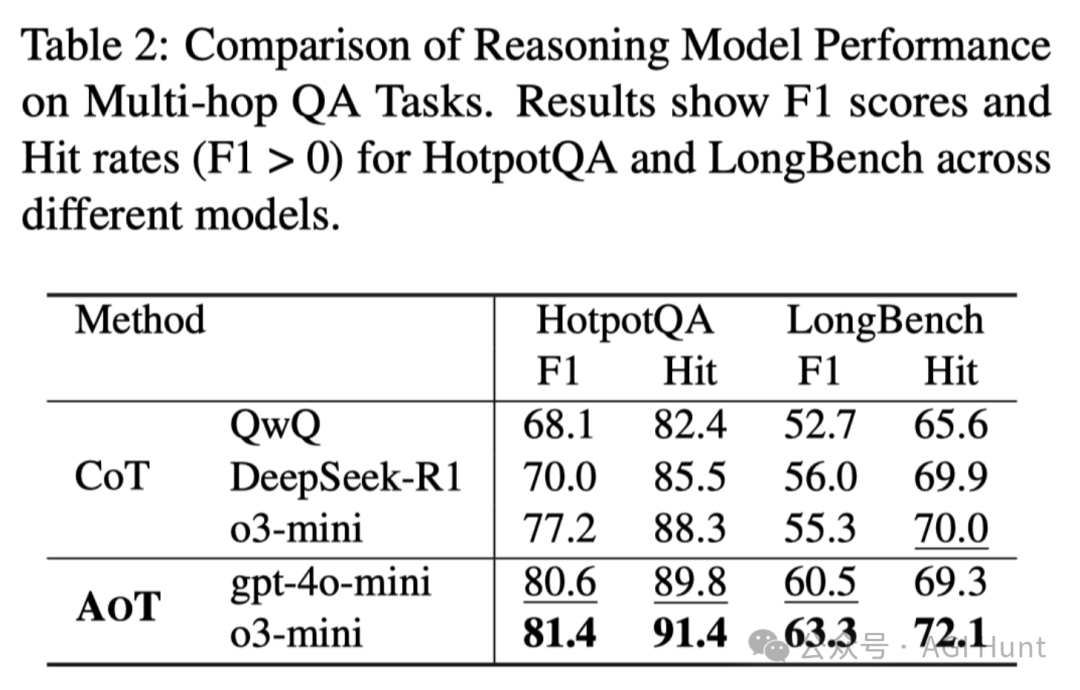
不仅如此,实验还表明AOT在多种基准测试上都表现优异,无论是作为独立框架还是插件增强都能带来显著提升。
已开源
想亲手试试这个强大的推理工具吗?

好消息是,研究团队已经开源了代码:
-
GitHub代码库:github.com/qixucen/atom
-
论文链接:arxiv.org/abs/2502.12018
该项目将很快在MetaGPT框架下也提供实现,方便熟悉这个出色开源框架(包括但不限于AFlow和SPO)的用户们使用。
快速上手AOT
开始使用前,你需要先配置API:
-
在项目根目录创建 apikey.py文件:
url = "https://api.openai.com/v1" # 替换为你的API端点api_key = ["your-api-key-here", # 替换为你的实际API密钥# 可以添加多个API密钥以提高并发性能]
AOT有两种使用模式:
1. 原子模式:将AOT作为推理方法
python main.py --dataset math --start 0 --end 10 --model gpt-4o-mini2. 插件模式:生成缩合数据集
python main.py --dataset math --mode plugin --start 0 --end 10 --model gpt-4o-mini命令参数说明:
-
--dataset:选择数据集,包括math、gsm8k、bbh、mmlu、hotpotqa或longbench -
--start和--end:指定评估样例的范围(如0-10表示前10个样例) -
--model:使用的LLM模型名称 -
--mode:选择atom(主要实验)或plugin(生成缩合数据集)
「插件模式」使AOT能够作为预处理步骤,生成缩合问题,这些问题可以输入到其他推理框架中。
这种方法结合了AOT的原子状态表示和其他测试时缩放方法的优势,使缩合问题在消除不必要的历史信息的同时保持与原始问题的答案等价性。
技术亮点与挑战
AOT框架的关键特性包括:
-
通用推理能力:在不同推理场景中均表现出色,包括数学问题、多选题和多跳问题,仅通过特定任务的提示词区分
-
资源高效利用:将计算资源集中在有效推理上,而非处理历史信息
-
卓越性能:在多个基准测试中超越现有方法
不过,AOT也面临一些技术挑战。
从研究者的讨论中可以看出,当初始的DAG分解未能正确建模子问题之间的并行关系或捕获了不必要的依赖关系时,会对后续的缩合和推理过程产生负面影响,而这种情况在实践中经常发生。
社区反馈中也有提到:「对于一些问题,如果这样做,会不会丢失问题的细微差别?」
这确实是需要考虑的挑战点。
未来方向
研究团队在GitHub中明确表示了下一步计划:
-
增强可复现性:持续改进代码库的可复现性,计划实现不同场景的自动提示优化,使框架更稳健、更易于适应各种用例
-
推进原子推理研究:原子推理仍是一个尚未充分探索但至关重要的领域
主要作者冯炜腾🍁在回复中称:
「让LLM掌握原子推理,像o1和R1掌握长链推理一样,仍然是一个巨大的挑战。我希望我能在这个领域继续取得进展。」
研究人员在论文中表示,大型语言模型通过训练时缩放实现卓越性能,而测试时缩放进一步通过在推理过程中有效推理增强了它们的能力。但随着推理规模的增加,现有的测试时缩放方法会受到累积历史信息的影响,这不仅浪费计算资源,还会干扰有效推理。
AOT的出现为解决这一问题提供了新思路,如果你有兴趣,不妨亲自一试,将其集成到你的推理框架中,或许能为你的项目带来意想不到的性能提升。
(文:AGI Hunt)