
Self-rewarding-reasoning-LLM:训练能自我奖励推理的大型语言模型,让模型在推理过程中自主评估输出正确性,无需外部反馈。亮点:
-
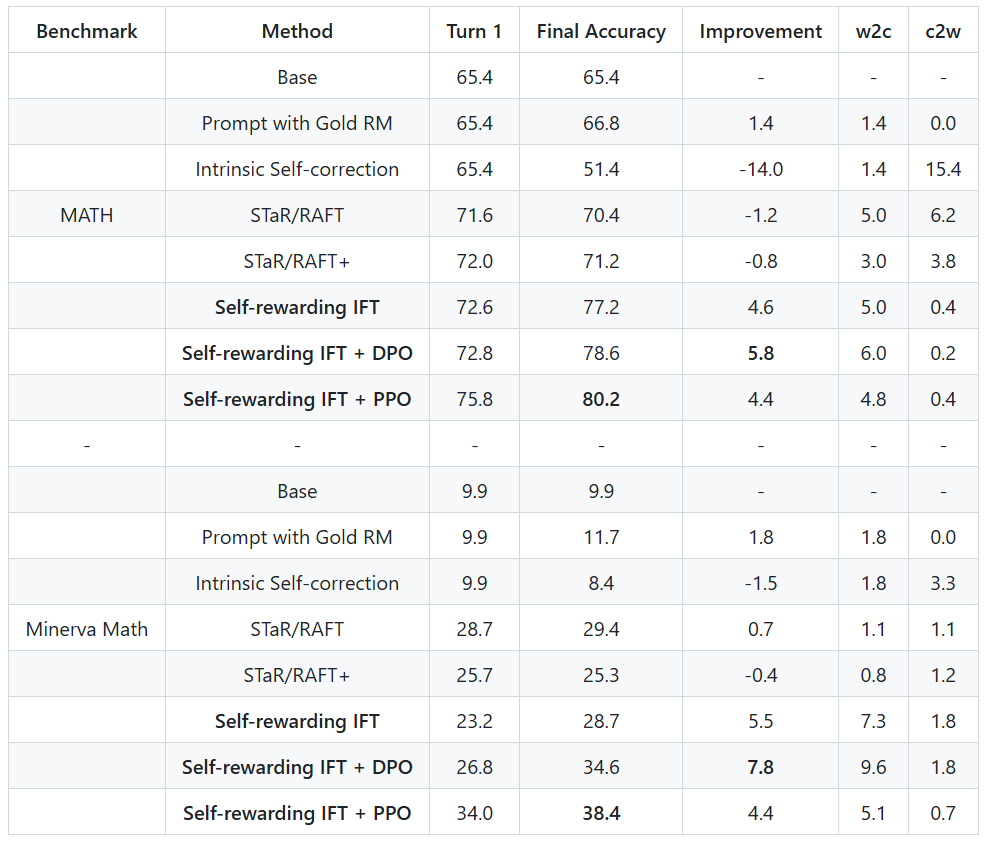
通过自我奖励机制,模型推理能力提升显著,最终准确率提升最高达14.2%; -
自我修正能力强大,能自动检测错误并优化输出; -
结合强化学习,性能超越依赖外部奖励模型的系统。
参考文献:
[1] http://github.com/RLHFlow/Self-rewarding-reasoning-LLM
(文:NLP工程化)
Self-rewarding-reasoning-LLM:训练能自我奖励推理的大型语言模型,让模型在推理过程中自主评估输出正确性,无需外部反馈。亮点:
参考文献:
[1] http://github.com/RLHFlow/Self-rewarding-reasoning-LLM
(文:NLP工程化)