
-
模型仓库:https://huggingface.co/qihoo360/Light-R1-32B
-
项目地址:https://github.com/Qihoo360/Light-R1
-
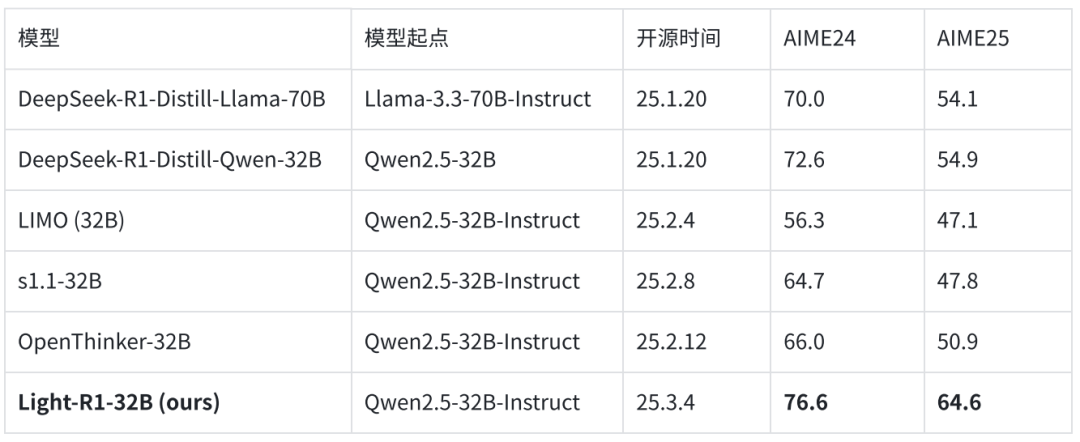
Light-R1-32B 模型:沿用 Qwen2.5-32B Apache 2.0 License;
-
课程学习 SFT+DPO 数据集:两阶段课程学习 SFT 和 DPO 的全部数据;
-
360-LLaMA-Factory 训练框架:在长思维链数据 Post-Training(尤其是 DPO)上解锁序列并行;
-
完整评测代码和结果:基于 DeepScaleR 的评测工具,Light-R1-32B 的原始采样结果也在 Huggingface 模型目录下。
-
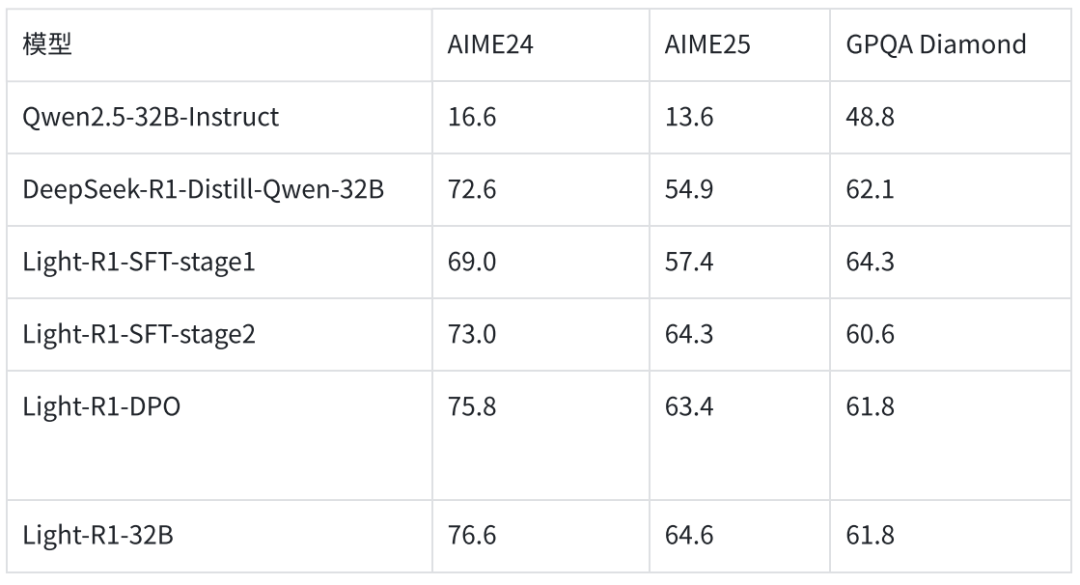
SFT 阶段 1:根据验证结果和难度分级初筛,得到 7 万条数据进行 SFT;
-
SFT 阶段 2:在 SFT 阶段 1 之后,筛选出难度最大的 3 千条数据,进行 SFT;
-
DPO 阶段:在 SFT 阶段 2 之后,在 3 千条数据上多次采样 Light-R1-SFT 阶段 2 的回答,根据验证结果和 DeepSeek-R1 的回答构建 DPO pair 对,进行 DPO,使用 DPO 原始 loss 或 NCA loss。

(文:机器之心)