


-
论文标题:A Survey on LLM Complex Reasoning through the Lens of Self-Evolution -
论文链接:https://www.researchgate.net/publication/389209259_A_Survey_on_Complex_Reasoning_of_Large_Language_Models_through_the_Lens_of_Self-Evolution?channel=doi&linkId=67b8b5b0207c0c20fa9111fb&showFulltext=true -
仓库链接:https://github.com/cs-holder/Reasoning-Self-Evolution-Survey
1. 引言
在人工智能领域,大型语言模型的复杂推理研究正成为学术界和工业界关注的焦点。随着 OpenAI 的 O1 以及后续 DeepSeek R1 等突破性成果的发布,这一领域的研究热度持续升温,引发了广泛的学术讨论和实践探索。这些里程碑式的研究成果不仅推动了相关技术的快速发展,也激励着研究者们不断尝试复现并拓展其应用边界。
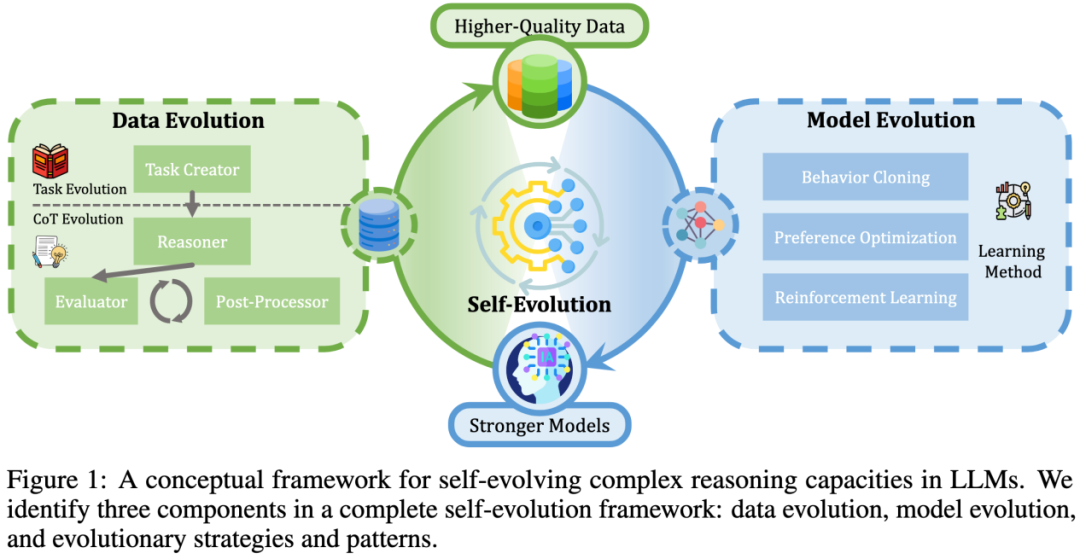
为促进该领域的深入研究,哈工大赛尔实验室知识挖掘组从自我进化的视角对现有技术体系进行了系统性分析从自我进化的视角对现有技术体系进行了系统性分析。我们的研究框架包含三个相互支撑的核心维度:数据进化、模型进化和自我进化。在数据进化维度,我们着重探讨了推理训练数据的优化策略,包括任务设计的改进和推理计算过程的优化,旨在提升思维链推理的质量和效率;在模型进化维度,我们系统梳理了通过训练优化模型模块来增强复杂推理能力的技术路径;在自我进化维度,我们深入分析了进化策略与模式,并基于此对 O1 类代表性工作进行解读。
本研究基于对 200 余篇前沿文献的深入调研,全面总结了提升 LLM 推理能力的技术演进路径。从基于树搜索的短思维链到基于强化学习的长思维链,我们系统梳理了当前最先进的研究方法,并对未来可能的研究方向进行了前瞻性展望。我们期待这篇综述能够为 LLM 复杂推理研究社区提供新的思路,推动该领域向更深层次发展,为提升 LLM 的推理能力开辟新的研究路径。
2. 章节组织
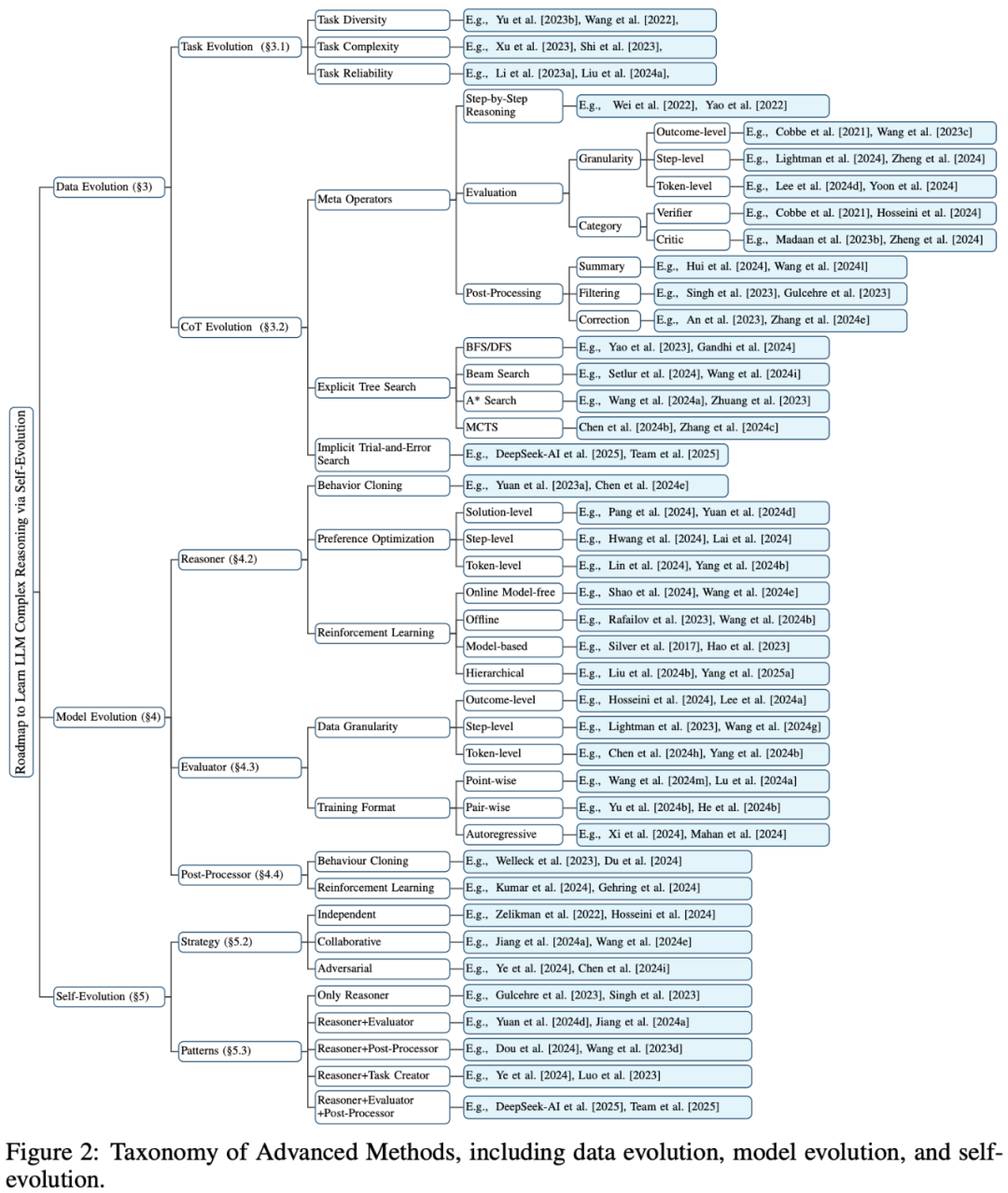
本文将从三个主要部分介绍 LLM 复杂推理的自我进化方法:数据进化、模型进化和自我进化。最后,我们将分析具有代表性的 O1 类工作,并对未来研究方向进行展望。
-
数据进化:探讨如何通过任务进化和思维链进化来生成更高质量的训练数据。 -
模型进化:关注如何通过优化模型模块来提升系统的推理能力。 -
自我进化:探讨如何通过迭代的数据和模型进化来实现系统的自我优化。
3. 数据进化
数据进化关注的是如何通过生成更高质量的训练数据来提升系统的推理能力。这一部分主要包含任务进化和思维链进化。我们将详细介绍每个部分的优化策略和技术。

3.1 任务进化
任务进化专注于生成更多样化和更具挑战性的任务,以提升模型的推理和泛化能力。当前研究中,任务进化的三个关键方向包括任务多样性、任务复杂性和任务可靠性。
-
任务多样性:为提高任务多样性,一些研究提示 LLM 修改数据类型和逻辑操作,生成结构相似但逻辑不同的任务。另一些研究使用 LLM 重新表述参考问题,或采用温度采样和以多样性为重点的提示来丰富问题生成。还有研究明确指导 LLM 创建罕见且领域特定的问题。此外,结合人工编写的任务与模型生成的任务,通过特定提示生成新任务也是一种有效方法。
-
任务复杂性:生成更复杂任务的方法包括添加约束、深化、具体化、增加推理步骤和增加输入复杂性。例如,通过引入额外的约束或要求来增加任务难度,或通过扩展查询深度和广度来提升模型的推理能力。具体化方法将问题中的通用概念替换为更具体的概念,使指令更清晰。增加推理步骤则通过要求额外的推理步骤来加强模型的逻辑思维能力。增加输入复杂性则通过修改问题条件,引入结构化数据或特定输入格式,提升模型的鲁棒性和泛化能力。
-
任务可靠性:自动生成任务可能会产生未解决的任务或错误答案。为解决这一问题,一些研究使用微调的 LLM 对任务进行评分并选择高质量任务。另一些研究从原始问题生成任务,并通过验证答案过滤不一致性。还有一些研究通过 Python 解释器和预定义规则验证编程任务的正确性以确保质量。此外,生成对抗网络(GAN)可用于合成任务,并通过评估与真实数据相似性的批评器提高可靠性。从数学解决方案中推导问题,或从高质量开源代码中创建编程任务,也是提高任务可靠性的有效方法。
3.2 思维链进化
思维链进化通过定义三个关键的元操作来构建更强大的推理链,这些元操作通过搜索算法扩展,生成更高质量的推理链。
3.2.1 元操作
思维链进化通过定义三个关键的元操作来构建更强大的推理链:逐步推理、评估和后处理。逐步推理将问题分解为逐步依赖的步骤,评估则在推理过程中进行自我评估和反思,后处理则对推理结果进行修正和总结。这些元操作通过搜索算法扩展,生成更高质量的推理链。
-
逐步推理:将复杂问题分解为一系列逐步依赖的步骤,使模型能够逐步解决每个子问题。这种方法通过递归分解,使模型能够处理更复杂的任务。例如,CoT 通过逐步提示解决每个子问题,Plan-and-Solve 通过生成计划并基于计划进行推理,Least-to-Most Prompting 通过显式分解问题并逐步解决每个子问题,ReACT 通过结合迭代推理和行动来增强推理过程。
-
评估:在推理过程中进行自我评估和反思,使模型能够识别和纠正错误。评估可以分为结果级、步骤级和 token 级。结果级评估在推理完成后对整个解决方案进行评估,步骤级评估在推理过程中对每个步骤进行评估,token 级评估对每个生成的 token 进行评估。这些评估方法通过不同的粒度,提供更细致的反馈,帮助模型改进推理过程。
-
后处理:后处理对推理结果进行修正和总结,使模型能够从错误中学习并改进未来的推理。后处理方法包括过滤、总结和修正。过滤直接移除低质量的推理结果,总结从推理过程中提取关键信息,修正则通过纠正错误来优化推理结果。这些方法通过不同的方式,提高推理结果的质量和可靠性。

3.2.2 显式树搜索(Short CoT)
显式树搜索方法通过树状搜索算法(如 BFS/DFS、Beam Search、A * 和 MCTS)来探索多个推理路径,生成正确且简洁的推理链。这些方法在搜索过程中使用评估函数指导探索方向,并进行剪枝以提高效率。例如,BFS/DFS 通过经典搜索算法探索多样化推理路径,Beam Search 通过维护候选序列平衡搜索准确性和计算效率,A * 通过评估函数优化搜索效率,MCTS 则通过平衡探索和利用来找到高质量的推理路径。
3.2.3 隐式试错搜素(Long CoT)
隐式试错搜素方法通过线性化整个搜索过程,允许模型在推理过程中进行自我评估和自我修正,生成包含错误检测、回溯和修正的长推理链。这种方法不依赖外部评估器或修正器,而是通过模型的自我评估机制来调整推理路径。例如,O1 Journey 通过蒸馏方法训练模型生成长推理链,而 DeepSeek-R1、Kimi-k1.5 和 T1 则通过强化学习训练模型生成长推理链。
3.2.4 显式树搜索与隐式试错搜索的比较和关联
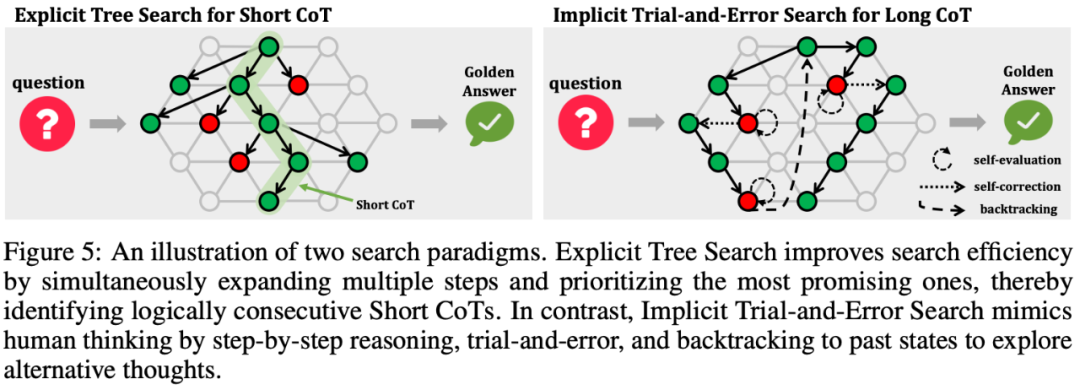
比较:
显式树搜索方法通过树状搜索算法(如 BFS/DFS、Beam Search、A * 和 MCTS)来探索多个推理路径,生成正确且简洁的推理链。这些方法在搜索过程中使用评估函数指导探索方向,并进行剪枝以提高效率。而隐式试错搜索方法通过线性化整个搜索过程,允许模型在推理过程中进行自我评估和自我修正,生成包含错误检测、回溯和修正的长推理链。这种方法不依赖外部评估器或修正器,而是通过模型的自我评估机制来调整推理路径。
关联:
-
搜索空间角度:树搜索专注于探索单个推理步骤定义的动作空间,确保每一步的逻辑性。试错搜索引入元操作(如评估、修正、回溯)扩展动作空间,生成更详细的长推理链。因此,如果将 Tree Search 的动作空间扩展为包含 评估、修正、回溯 等元操作,那么理论上可以通过 Tree Search 搜索到 Long CoT。
-
推理能力进化角度:Long CoT 是解决新问题的有效策略,通过试错和自我修正探索解决方案。Short CoT 通过持续训练从 Long CoT 中提取知识,学习高效推理路径,减少试错,缩短推理链。Long CoT 作为初始解决方案,其知识可用于学习 Short CoT,后者作为先验知识,减少处理更复杂任务时的试错迭代。
4. 模型进化
模型进化关注的是如何通过优化模型的各个模块来提升系统的推理能力。这一部分主要包含 Reasoner、Evaluator 和 Post-Processor 的优化方法。我们将详细介绍每个模块的优化策略和技术。
4.1 Background RL Knowledge
强化学习为 LLM 的模型进化提供了核心优化框架,其技术演进从传统 RLHF 逐步发展为更高效的范式。RLHF 通过人工标注的偏好数据训练结果奖励模型实现LLM对齐。PPO 算法通过约束策略优化步长进行策略偏移控制,具备稳定性地优势,但存在训练复杂度高、资源消耗大等问题。为此后续研究提出多种改进:REINFORCE 简化架构,利用最高概率动作作为基线(ReMax)或多轨迹采样估计基线(RLOO),降低对价值模型的依赖;GRPO 通过蒙特卡洛组内归一化替代价值模型,提升训练稳定性;DPO 省去显式奖励建模,直接通过偏好数据对齐策略模型,但面临细粒度优化不足的局限;PRIME 结合结果奖励模型(ORM)的训练实现 token 级隐式奖励信号分发。
4.2 Reasoner 优化
Reasoner 是模型的核心组件,负责生成推理过程和最终答案。优化 Reasoner 的方法主要包括行为克隆、偏好优化和强化学习。
4.2.1 行为克隆
行为克隆通过监督学习直接模仿高质量推理轨迹来优化模型,是模型进化的基础方法。其核心流程包括:从正确解中筛选训练数据,通过微调使模型学习标准推理模式。
然而,传统方法仅使用正确数据,导致大量错误解被浪费。为此,改进方法通过逆向策略利用错误数据:例如,将错误问题重新生成正确解法以扩充正样本,或修改错误解的指令标签(如将 “生成正确答案” 改为 “生成错误答案”),使其转化为负样本供模型学习。此外,部分方法训练专用修正器模型,定位并修复推理错误。
尽管行为克隆实现简单,但其依赖静态数据集的特性限制了持续进化能力,且难以充分探索错误样本中的潜在价值,成为后续强化学习方法的重要补充。
4.2.2 偏好优化
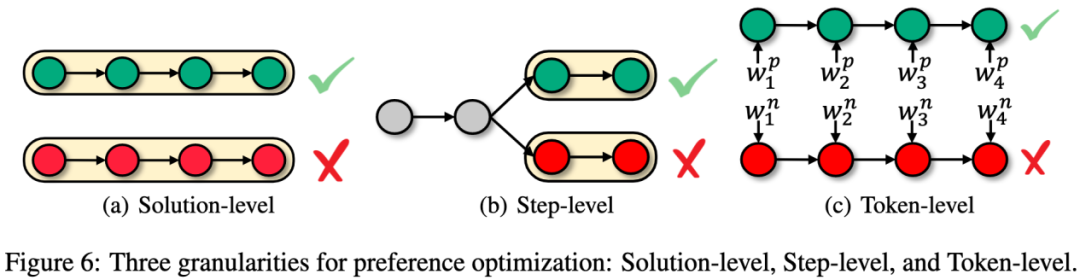
偏好优化通过推动高质量推理路径的概率上升,低质量路径的概率下降来提升模型的推理能力。偏好优化可以根据偏好数据的粒度分为解决方案级、步骤级和 token 级优化。
-
解决方案级偏好优化:通过比较不同解决方案的质量来优化模型。具体来说,给定一组解决方案,根据答案的正确性将其分为正确和错误两组,然后构建偏好对进行优化。这种方法简单直观,但对中间推理步骤的优化能力较弱。
-
步骤级偏好优化:通过评估每个推理步骤的质量来优化模型。具体来说,通过主动构造或树搜索方法生成带有相同前缀的正确和错误推理轨迹,然后构建偏好对进行优化。这种方法能够更细致地优化模型的推理过程,但对数据的要求较高。
-
Token 级偏好优化:通过评估每个生成的 token 来优化模型。具体来说,通过隐式奖励或显式标注方法为每个 token 分配奖励值,然后基于这些奖励值进行优化。这种方法能够提供最细粒度的反馈,但计算复杂度较高。
4.2.3 强化学习
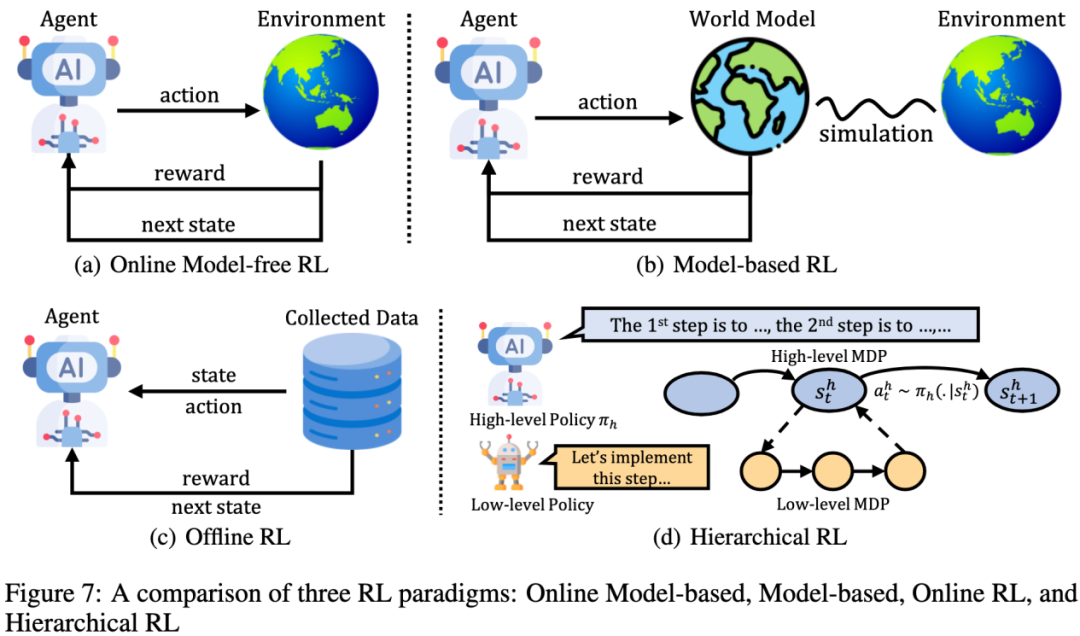
强化学习通过与环境的交互来优化 LLM 的推理能力。具体来说,强化学习方法包括 model-free 在线强化学习、离线强化学习、基于模型的强化学习和层次强化学习。
-
model-free 在线强化学习:通过直接与环境交互来训练策略模型。具体来说,模型在环境中生成推理轨迹,然后根据奖励信号进行优化。常用的方法包括 REINFORCE、PPO 和 GRPO。这些方法通过在线交互,能够动态调整模型的行为,但对环境的依赖性较强。
-
离线强化学习:使用静态数据集进行训练,而不是通过与环境交互来收集数据。具体来说,离线强化学习方法如 DPO 通过收集偏好数据,然后基于这些数据进行优化。这种方法能够高效利用已有数据,但对数据质量的要求较高。
-
基于模型的强化学习:通过模拟环境来减少训练和推理中的交互成本。具体来说,模型首先学习一个环境模型,然后在模拟环境中进行训练。这种方法能够显著减少与真实环境的交互次数,但对环境模型的准确性要求较高。
-
层次强化学习:通过分解任务为高层次和低层次的马尔可夫决策过程来提升推理能力。具体来说,高层次模型负责规划推理步骤,低层次模型负责生成具体的推理内容。这种方法能够更好地模拟人类的推理过程,但实现复杂度较高。
4.3 Evaluator 优化
Evaluator 负责评估 Reasoner 生成的推理过程和答案的质量。优化 Evaluator 的方法主要包括训练数据的构造和训练格式的选择。
4.3.1 训练数据构造
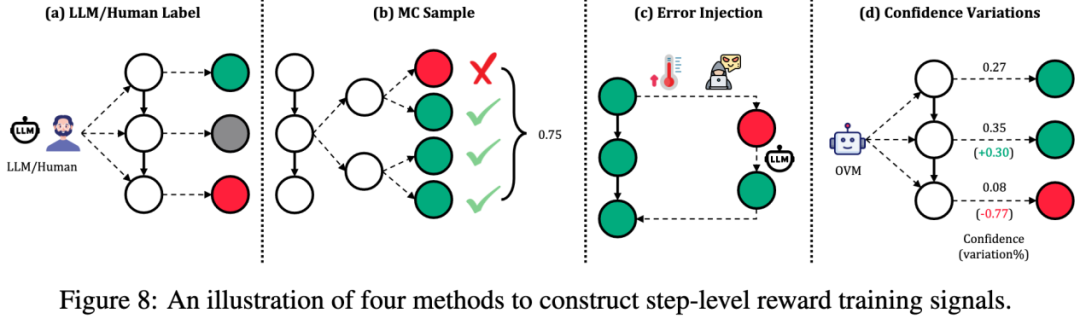
Evaluator 的优化需要构造高质量的训练数据,包括结果级、步骤级和 token 级数据。
-
结果级数据构造:通过正确答案标签或 LLM 评估来生成。具体来说,使用正确答案标签将解决方案分类为正确和错误,然后基于这些分类进行训练。这种方法简单直观,但对中间推理步骤的评估能力较弱。
-
步骤级数据构造:通过蒙特卡洛采样、LLM 评估或一致性评估来生成。具体来说,通过采样或评估方法为每个推理步骤分配奖励值,然后基于这些奖励值进行训练。这种方法能够提供更细致的反馈,但计算复杂度较高。
-
Token 级数据构造:通过生成模型重写原始解决方案或利用隐式奖励来生成。具体来说,通过重写或奖励分配方法为每个 token 分配奖励值,然后基于这些奖励值进行训练。这种方法能够提供最细粒度的反馈,但实现难度较大。
4.3.2 训练格式
Evaluator 的训练格式可以是点式、成对式或语言式。
-
点式训练:使用标量值优化评估模型。具体来说,通过预测每个解决方案或步骤的奖励值来训练模型。这种方法简单直观,但对偏好数据的利用不够充分。
-
成对式训练:使用偏好数据优化评估模型。具体来说,通过比较不同解决方案或步骤的偏好关系来训练模型。这种方法能够更好地利用偏好数据,但对数据的要求较高。
-
语言式训练:通过生成自然语言反馈来提升评估的可靠性和可解释性。具体来说,通过生成对解决方案或步骤的自然语言评价来训练模型。这种方法能够提供更丰富的反馈,但实现复杂度较高。
4.4 Post-Processor 优化
Post-Processor 负责对 Reasoner 生成的推理结果进行修正和总结。优化 Post-Processor 的方法主要包括行为克隆和强化学习。
-
行为克隆:通过利用错误数据生成修正数据来提升模型的自我修正能力。具体来说,通过生成错误数据并利用正确数据进行微调,训练模型学习如何修正错误。这种方法能够显著提高模型的自我修正能力,但对数据的要求较高。
-
强化学习:通过整合外部执行反馈来提升模型的自我改进能力。具体来说,通过将修正过程建模为马尔可夫决策过程,并使用强化学习算法进行优化,训练模型学习如何在推理过程中进行自我修正。这种方法能够提供更动态的反馈,但实现复杂度较高。
5. 自我进化
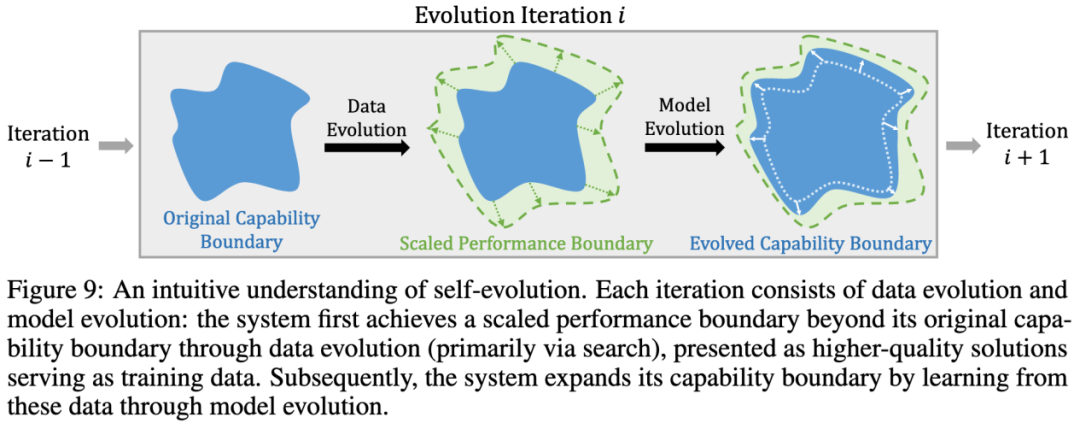
自我进化要求系统利用自身生成的数据来持续提升性能。这一部分将探讨自我进化的理论基础、策略、模式以及面临的挑战和未来方向。
5.1 自我进化背后的理论
通过期望最大化(EM)算法,自我进化被形式化为一个交替优化过程。E 步(数据进化)生成高质量推理轨迹并评估其质量,M 步(模型进化)基于生成数据优化模型参数,形成一个闭环迭代机制。这一过程在理论上能够保证系统性能的逐步提升并最终收敛。
5.2 自我进化策略
自我进化策略包括独立进化、合作进化和对抗进化。独立进化通过单独优化一个模块来提升性能,合作进化通过模块间的合作来提升整体性能,而对抗进化则通过模块间的对抗来避免局部最优问题。
-
独立进化:每个模块独立进行优化,不依赖于其他模块的反馈。例如,Reasoner 可以通过行为克隆或偏好优化单独进行训练,Evaluator 可以通过结果级或步骤级数据单独进行训练,Post-Processor 可以通过行为克隆单独进行训练。这种方法简单直观,但可能无法充分利用模块间的协同作用。
-
合作进化:模块间通过合作来提升整体性能。例如,Reasoner 生成的推理结果可以用于训练 Evaluator,Evaluator 的反馈可以用于优化 Reasoner,Post-Processor 的修正结果可以用于进一步训练 Reasoner。这种方法能够充分利用模块间的协同作用,提升整体性能,但实现复杂度较高。
-
对抗进化:模块间通过对抗来避免局部最优问题。例如,Task Creator 生成更具挑战性的任务来测试 Reasoner,Reasoner 通过解决这些任务来提升自身能力。这种方法能够有效避免模型陷入局部最优,但需要精心设计对抗机制。
5.3 自我进化模式
自我进化模式包括仅优化 Reasoner、Reasoner + Evaluator、Reasoner + Post-Processor、Reasoner + Task Creator 和 Reasoner + Evaluator + Post-Processor。每种模式都有其独特的优化方法和优势,通过结合多种模式可以实现更显著的性能提升。
-
仅优化 Reasoner:仅对 Reasoner 进行优化,不涉及其他模块。优化方法包括行为克隆、偏好优化和强化学习。这种方法简单直观,但可能无法充分利用其他模块的反馈。
-
Reasoner + Evaluator:Reasoner 生成的推理结果用于训练 Evaluator,Evaluator 的反馈用于优化 Reasoner。这种方法能够充分利用模块间的协同作用,提升推理能力和评估能力。
-
Reasoner + Post-Processor:Reasoner 生成的推理结果用于训练 Post-Processor,Post-Processor 的修正结果用于进一步训练 Reasoner。这种方法能够提升推理结果的质量和可靠性。
-
Reasoner + Task Creator:Task Creator 生成更具挑战性的任务来测试 Reasoner,Reasoner 通过解决这些任务来提升自身能力。这种方法能够提升模型的泛化能力和任务多样性。
-
Reasoner + Evaluator + Post-Processor:Reasoner 生成的推理结果用于训练 Evaluator 和 Post-Processor,Evaluator 的反馈和 Post-Processor 的修正结果用于进一步训练 Reasoner。这种方法能够充分利用模块间的协同作用,实现更全面的性能提升。
6. 对代表性 O1 类研究的重新解读
通过对代表性 O1 类研究的分析,我们发现这些研究都可以用自我进化框架来解释。例如,Marco-O1 通过 MCTS 生成数据并进行监督式微调,O1 Journey 通过长推理链的生成和 DPO 优化提升推理能力,Slow Thinking with LLMs 通过迭代训练和 DPO 优化实现 Reasoner 和 Evaluator 的共同进化,rStar-Math 通过多轮迭代训练实现 Reasoner 和 Evaluator 的共同进化,OpenR/O1-Coder 通过 RL 优化 Reasoner 和 Evaluator,DeepSeek R1/Kimi-k1.5/T1 则通过在线 RL 实现 Reasoner、Evaluator 和 Post-Processor 的共同进化。
7. 挑战和未来方向
自我进化框架的挑战与方向:
更有前景的自我进化模式:通过探索不同的模块组合和策略,如合作和对抗学习,可以实现更有效的自我进化框架。理想情况下,所有模块的同时提升将带来持续且显著的改进。
系统泛化:自我进化通过迭代训练提升系统性能。持续进化的关键在于防止过拟合并确保泛化。首先,任务泛化至关重要;合成更多样化和复杂的任务可以确保更广泛的覆盖范围,这是解决泛化问题的基础。其次,推理器、评估器和后处理器的泛化能力至关重要。B-StAR 显示,增强推理器的探索能力可以减少过拟合。后处理器在多样化解决方案中也起着关键作用。此外,奖励黑客行为表明当前的评估器可能会过拟合到推理器并利用奖励捷径。总之,推理系统的泛化对于自我进化框架中的持续增强至关重要。
自我进化视角下提升 R1 等工作的不足:
-
任务多样性:当前任务生成方法在复杂性和多样性上有提升空间,需进一步增强任务多样性,生成更具挑战性和领域相关性的任务。
-
自我评估和修正能力:模型的自我评估和修正能力在准确性和效率上存在不足,需进一步提升以更准确地识别和修正错误,从而通过更准确更高效的试错搜索实现数据进化。
-
奖励建模方法:解决LLM在隐式试错搜索过程中过思考和欠思考等问题可能需要更细粒度的奖励信号,现有奖励建模方法在泛化能力和准确性不足等问题,需开发更有效的奖励建模方法以更准确地评估模型性能,指导基于RL的模型进化。
将自我进化应用于具身智能场景:
在具身智能场景中,为实现自我进化,需提升模型对多模态数据的理解能力,重新定义多模态推理的思维链格式,降低与环境交互的成本,并增加训练数据资源。
8. 总结
本文系统地综述了 LLM 复杂推理的自我进化方法,从数据进化、模型进化和自我进化三个角度进行了深入分析。通过对现有技术和方法的总结,我们希望为 LLM 复杂推理社区提供新的研究方向和灵感,推动 LLM 推理能力的进一步提升。
©
(文:机器之心)