
机器之心发布
机器之心编辑部
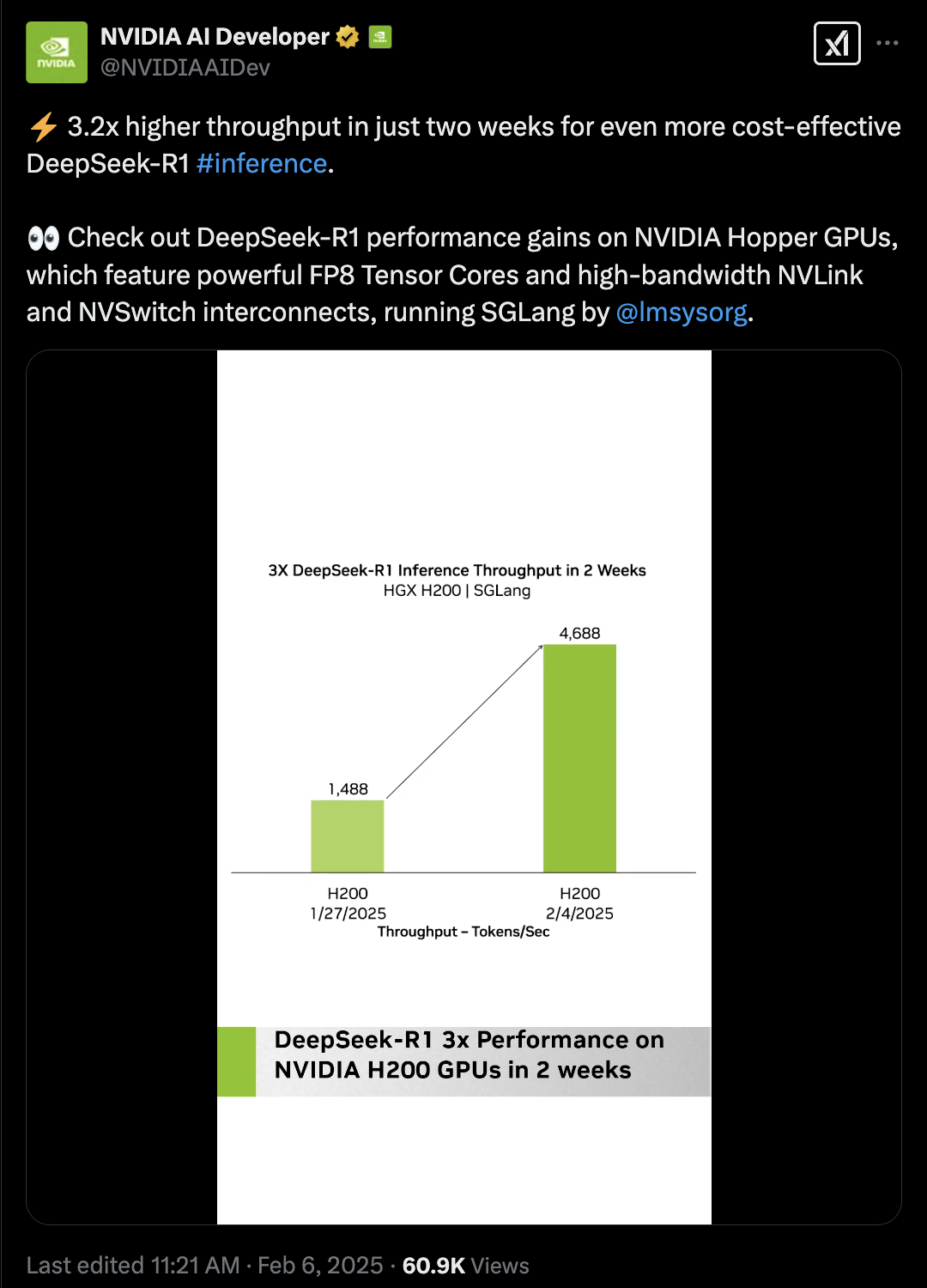
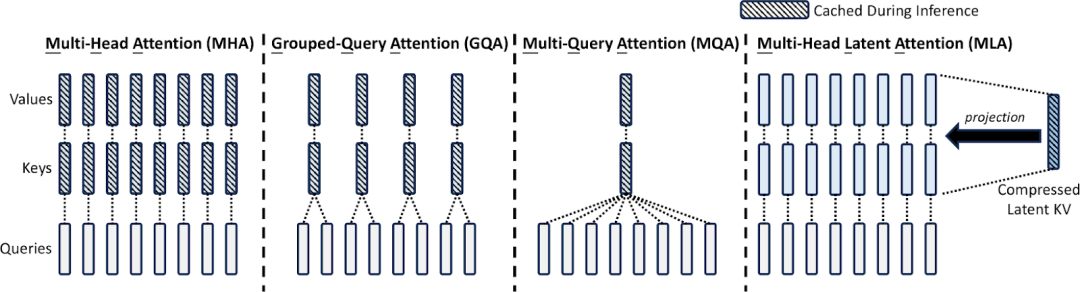
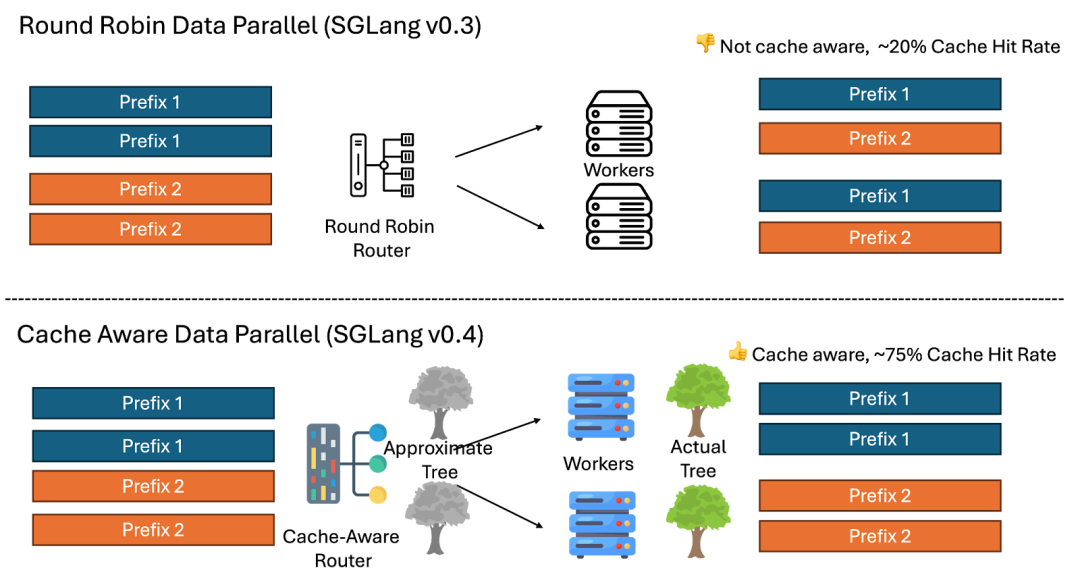
-
GitHub 仓库: https://github.com/sgl-project/sglang
-
Slack 社区:slack.sglang.ai
-
DeepSeek 优化指南: https://docs.sglang.ai/references/deepseek.html
(文:机器之心)
机器之心发布
机器之心编辑部
GitHub 仓库: https://github.com/sgl-project/sglang
Slack 社区:slack.sglang.ai
DeepSeek 优化指南: https://docs.sglang.ai/references/deepseek.html
(文:机器之心)