
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
数据作为预训练大模型的基石,其合规性至关重要。传统的合规评估方法主要依赖于表面的许可条款,忽略了数据集在再分发、合并和转换过程中的复杂性。会导致许多看似合规的数据集在实际使用中可能面临法律风险。
例如,纽约时报起诉OpenAI案和Getty Images起诉Stability AI案等法律纠纷,都显示了训练数据合规的重要性。
LG AI研究院表示,数据集的法律风险不仅取决于其许可条款,还与其数据来源、处理过程和再分发路径密切相关,所以,仅通过人工审查许可条款来评估合规性是远远不够的。
为了解决这一难题,LG研究人员提出了一种新的数据合规框架NEXUS,能够系统地追踪数据集的再分发、分析合规性,并识别潜在的法律风险。

NEXUS框架的核心是数据合规模块,通过18个加权标准对数据集的法律风险进行全面评估,涵盖了版权法、个人数据保护法以及不正当竞争法等多个方面,不仅考虑了数据集本身的许可条款,还深入分析了数据的来源、处理过程以及再分发路径。
例如,会评估数据集中是否包含个人数据,数据主体是否同意其数据被使用,以及数据是否可以被第三方使用等关键问题。
为了自动化评估数据的合规性NEXUS内置了AutoCompliance Agent,主要包含导航、问答模块和评分三大功能。
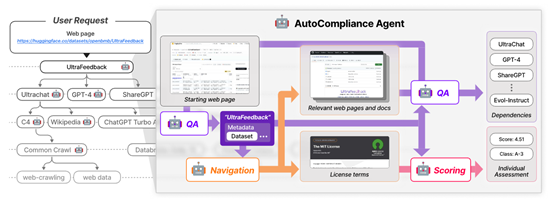
导航模块负责在互联网上查找数据集的许可条款和依赖信息,能够智能地识别和定位与数据集相关的各种资源;问答模块则通过推理任务提取依赖实体的信息,这一模块能够理解并处理复杂的文本信息,从而准确地识别数据集的依赖关系;
评分模块则根据许可条款和其他元数据,包括数据集的名称、类型和模态等,计算数据合规分数,并确定个体类别。
NEXUS的另一个重要模块是对数据集生命周期的追踪,通过构建许可依赖图,将数据集的各个组成部分及其依赖关系以图形化的方式呈现出来。每个数据集都被视为一个节点,而其依赖关系则被表示为节点之间的边。
在实际应用中,NEXUS通过Agent功能对数据集进行自动化评估。用户只需提供目标数据集的起始网页,Agent就会从该网页出发,自动提取数据集的名称和类型,并将其分类为六种实体类型之一,包括数据集、内容服务提供商、平台服务提供商等。
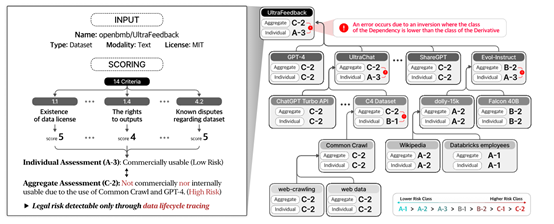
接着会在互联网上查找与该数据集相关的网页和文档,从中提取许可条款和依赖信息。基于这些信息,评分模块会计算数据集的合规性分数。
为了评估NEXUS框架的有效性,研究人员从Hugging Face平台上随机抽取了216个数据集作为测试,这些数据集涵盖了多种类型和来源,能够有效反映现实世界中的数据集复杂性。
结果显示,NEXUS在查找依赖关系的任务中达到了81.04%的准确率,而在查找许可条款的任务中,准确率更是高达95.83%。显著优于人类专家的表现,后者的准确率分别为64.19%和87.73%。
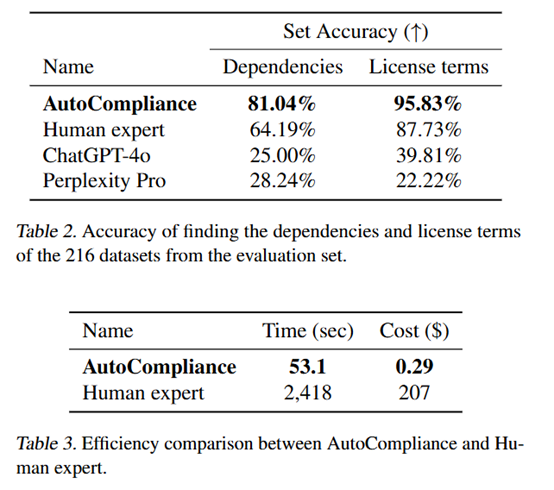
除了准确性之外,还对NEXUS的时间和成本效率进行了评估。结果显示,NEXUS完成任务的平均时间为53.1秒,成本仅为0.29美元。相比之下,人类专家完成相同任务需要2418秒,成本高达207美元。
(文:AIGC开放社区)