
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
AMD在官网开源了最新小参数模型Instella-3B。比较特别的是,这是一个基AMD Instinct™ MI300X GPU从头训练的模型。
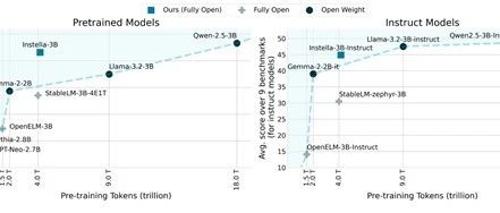
根据测试数据显示,Instella-3B的性能超过了Llama-3.2-3B、Gemma-2-2B,可以媲美阿里开源的Qwen-2.5-3B,这也证明了AMD的GPU也能训练出高性能的大模型。

开源地址:https://huggingface.co/amd/Instella-3B
Instella-3B-SFT是经过监督微调的模型,使用了89.02亿tokens的数据,增强了遵循指令的能力。Instella-3B-Instruct则是经过直接偏好优化的模型,使用了7.6亿tokens的数据,使模型的输出更符合人类偏好,增强了聊天能力。
架构方面,Instella模型是基于文本的自回归Transformer架构,拥有30亿参数,包含36个解码器层,每层有32个注意力头,支持最长4096tokens的序列长度,词汇量约为50,000tokens。
在预训练和微调过程中,AMD使用了FlashAttention-2、Torch Compile和bfloat16混合精度训练,以减少内存使用,提高计算速度和资源利用率。此外,AMD还采用了全分片数据并行(FSDP)与混合分片技术,以平衡集群内节点间的内存效率和节点内通信开销。
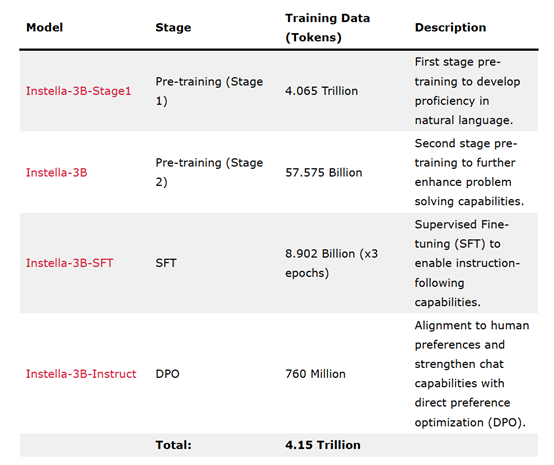
Instella模型的训练分为四个阶段,每个阶段都逐步增强了模型从基础自然语言理解到遵循指令以及与人类偏好对齐的能力。在第一阶段预训练中,AMD使用了4.065万亿tokens的数据,这些数据来自OLMoE-mix-0924,是一个涵盖编码、学术、数学和网络爬取等领域的高质量数据集组合。这一阶段为Instella模型奠定了自然语言理解的基础。
在第二阶段预训练中,AMD在第一阶段的基础上进一步训练了模型,使用了额外的575.75亿tokens的数据,这些数据来自多个高质量和多样化的数据集,包括Dolmino-Mix-1124、SmolLM-Corpus(python-edu)、Deepmind Mathematics以及对话数据集等。

此外,AMD还使用了内部合成数据集,专注于数学问题。这些合成数据是通过使用GSM8k数据集的训练集生成的,通过抽象数值、生成Python程序解决问题,并替换数值以生成新的问题-答案对。这一阶段的训练使Instella-3B模型在多个基准测试中表现出色,与现有的先进开源权重模型相比具有竞争力。
在指令微调阶段,AMD使用Instella-3B作为基础模型,使用89亿tokens的高质量指令-响应对数据进行了三个周期的训练,以增强模型在交互式环境中的表现,使其更适合执行用户指令的任务。训练数据来自多个任务和领域的精选数据集,确保模型能够泛化各种指令类型。
在最后的对齐阶段,AMD使用直接偏好优化(DPO)技术,以Instella-3B-SFT为基础模型,使用7.6亿tokens的数据进行了训练,以确保模型的输出符合人类价值观和期望,从而提高其输出的质量和可靠性。
Instella-3B在多个基准测试中超越了现有的全开源模型,并且与阿里开源的Qwen-2.5-3B能力差不多。例如,在MMLU、BBH和GSM8k等基准测试中,Instella-3B模型的表现优于Llama-3.2-3B和Gemma-2-2B等模型。
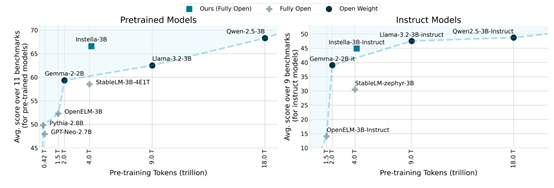
经过指令微调和对齐后的Instella-3B-Instruct模型在指令遵循任务和多轮问答任务中表现出色,同时在训练数据量上更少。
(文:AIGC开放社区)