

lmm-r1团队 投稿
量子位 | 公众号 QbitAI
多模态大模型虽然在视觉理解方面表现出色,但在需要深度数学推理的任务上往往力不从心,尤其是对于参数量较小的模型来说更是如此。
如何让小型多模态大模型也能拥有强大的数学推理能力呢?
如图所示,通过LMM-R1框架训练的模型(下侧)能够正确应用勾股定理计算出圆锥的斜高,而基准模型(上侧)错误地识别了斜高位置,导致计算错误。这种显著的推理能力提升来自于一个创新的两阶段训练策略。

这是来自东南大学、香港中文大学、蚂蚁集团等研究人员的,两阶段多模态基于规则强化学习的框架LMM-R1,实现多模态大模型的推理性能飞跃。
针对多模态领域长期存在的”高训练成本、低任务泛化”难题,LMM-R1框架创造性引入规则化奖励函数机制。
通过深度优化DeepSeek-R1核心思想,该框架在无需多模态标注数据的情况下,仅需240元GPU成本即可显著增强模型性能,成功将多模态模型的推理能力提升至工业级应用标准。
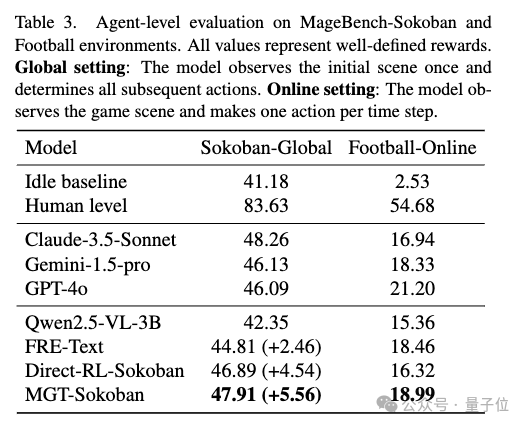
实验数据显示,经LMM-R1框架强化的QwenVL-2.5-3B模型,在推箱子等复杂路径规划任务中,性能显著超越GPT-4o、Claude3.5等100B+参数量产品级大模型。
从文本到多模态的推理能力迁移
DeepSeek-R1和OpenAI的o1等模型已经证明了基于规则奖励的强化学习在纯文本大语言模型中的有效性。然而,将这一成功经验扩展到多模态领域面临两大关键挑战:
-
数据限制:多模态领域中高质量的推理数据十分稀缺,且答案常常模糊不清,难以用于规则奖励
-
基础推理能力薄弱:多模态预训练常常会削弱模型在纯文本任务上的能力,特别是对于参数量有限的小模型
针对这些挑战,研究团队提出了LMM-R1框架,通过创新的两阶段训练策略巧妙解决了以上问题。
LMM-R1:两阶段强化学习策略
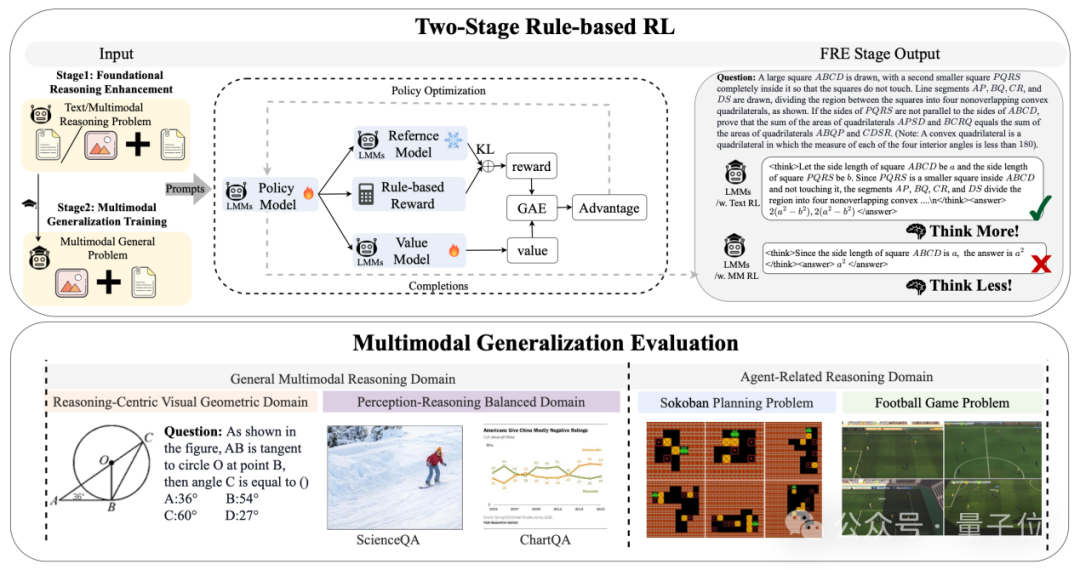
LMM-R1框架包含两个精心设计的阶段:
第一阶段:基础推理增强(FRE)
FRE阶段利用丰富的高质量纯文本推理数据(如数学题、科学问题等)通过基于规则的强化学习来增强模型的基础推理能力。这一阶段避开了多模态数据的限制,专注于构建坚实的推理基础。
在这个阶段,模型学习如何进行严密的逻辑思考、复杂的数学运算和多步骤推理,为后续的多模态泛化奠定基础。
第二阶段:多模态泛化训练(MGT)
MGT阶段将第一阶段培养的推理能力泛化到多模态领域。研究团队在这一阶段探索了几个关键领域:
-
几何推理领域:使用GeoDB等数据集,增强模型在几何图形推理方面的能力
-
感知-推理平衡领域:使用VerMulti数据集,提升模型在多种视觉任务中的推理能力
-
智能体相关领域:使用推箱子(Sokoban)等需要复杂规划的任务
值得注意的是,这种两阶段策略避免了对昂贵的高质量多模态训练数据的依赖,同时有效利用了丰富的文本推理数据资源,为构建高性能多模态模型提供了一种高效路径。
实验结果
研究团队使用Qwen2.5-VL-Instruct-3B作为基准模型进行实验。经过LMM-R1框架训练后,模型在各类基准测试上均取得显著提升:
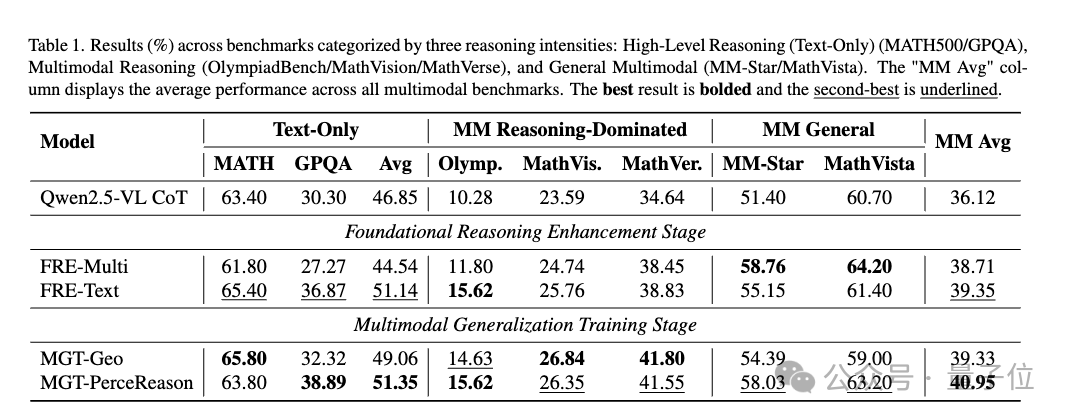
-
在纯文本和多模态基准测试上平均提升约4.5%~4.8%
-
在推理密集型任务(如几何问题)上效果尤为明显
更重要的是,实验证明了一个关键发现:通过先增强基础推理能力再进行多模态泛化的策略,可以有效避免直接在多模态数据上训练时常见的推理能力退化问题。
在典型智能体应用场景验证中,研究团队选取推箱子任务作为评估基准。该任务要求模型同步处理视觉空间解析、目标匹配、动态路径规划等多模态推理能力,对智能体在现实场景中的决策能力具有重要指示意义。经LMM-R1框架强化后的模型,仅通过初始画面即可完成完整动作序列规划。
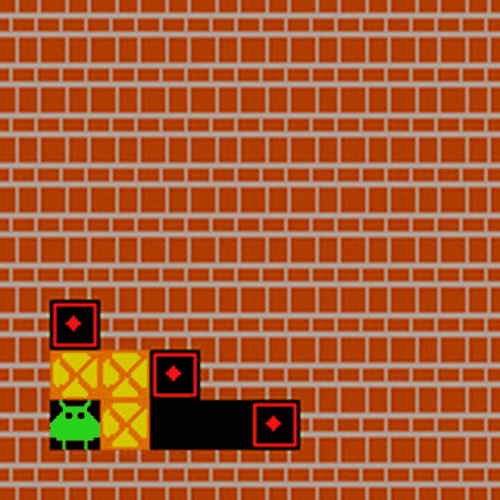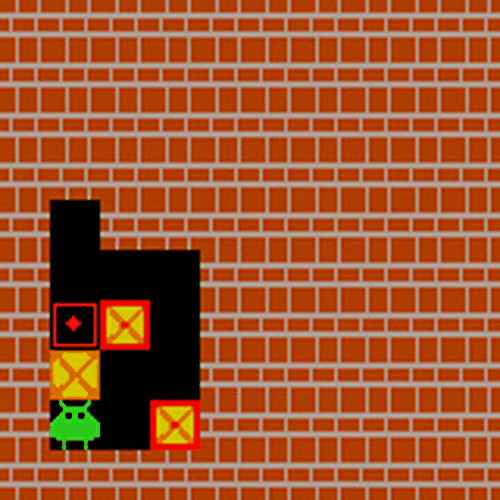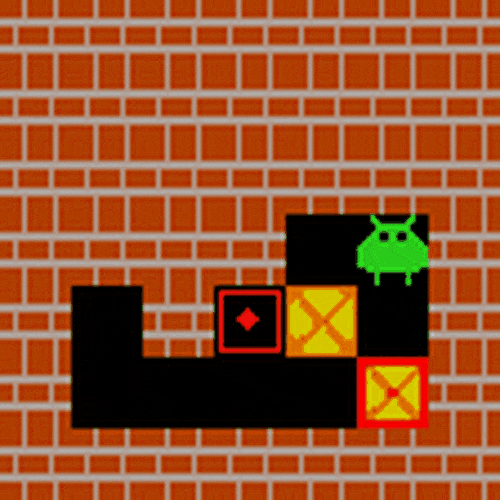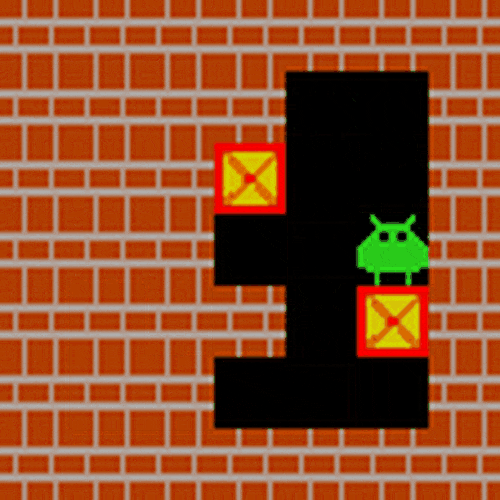
实验证明哪怕是3B规模的小模型,使用LMM-R1的两阶段RL训练,也可以极大增强推理能力,暗示了多模态R1的强大应用潜力。
值得关注的是,该框架以上游项目OpenRLHF为基础,实现了完全自主研发的多模态训练方案:通过重构数据流实现多模态支持,基于张量并行优化和内存管理技术创新,构建起高效稳定的训练体系。其开创性的PackingSample + Ring FlashAttention技术实现了模型最大上下文长度基于GPU数量的线性增长率,配合动态梯度裁剪策略,在保证训练稳定性的同时大幅降低资源消耗。
项目自2025年2月开源以来迅速获得学术界关注,相关技术方案已被多个知名开源项目采纳为基准架构。目前,LMM-R1框架已在GitHub平台建立独立技术生态,累计获得超过500+星标关注。
团队表示将持续深耕多模态模型领域,推动多模态强化学习技术在智能体、视觉问答等场景的落地应用。与开源社区共建多模态强化学习框架。
论文地址:https://arxiv.org/abs/2503.07536
项目主页:https://forjadeforest.github.io/LMM-R1-ProjectPage/
项目地址:https://github.com/TideDra/lmm-r1
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
—
(文:量子位)