
新智元报道
新智元报道
【新智元导读】万众瞩目的Blackwell Ultra终于登场亮相,专为DeepSeek R1这样的推理模型打造,性能直达Hoper的40倍!而下一代GPU「Rubin」,将于2026年下半年问世。这次,老黄的金句直接升级为「买得越多,赚得越多」。
全世界都错了,Scaling Law并没有撞墙!
刚刚在圣何塞结束的GTC大会上,老黄声称没有脚本、没有提词器,用两个多小时向我们介绍了英伟达过去一年的进展。
老黄表示,如果说从前的GTC说AI的伍德斯托克音乐节,那今年搬进体育场的GTC就是AI的超级碗,而唯一不同的说,每个人都是超级碗的赢家。

全场精彩亮点如下:
-
Blackwell已全面投产,而且进展非常快,客户需求也非常大。这一切皆是因为AI拐点已至,训练推理AI/智能体系统对计算量的需求大大增加。
-
Blackwell NVL72结合Dynamo推理性能提升了40倍,相当于一座Hopper AI工厂的性能。
-
英伟达未来三年路线图已公开,GPU每年一更:Blackwell Ultra预计2025年下半年上市,下一代Rubin 2026年问世。
-
英伟达正在构建3个AI基础设施:云上AI基础设施,企业AI基础设施和机器人AI基础设施。

英伟达预言:在未来,每个拥有工厂的公司将来都会有两个工厂,一个是用来制造产品的实体工厂,另一个是用于数学运算的AI工厂。为此,各类CUDA-X软件库已经准备好,引爆全行业的变革。
而这场革命的背后,就是英伟达的CUDA核心,以及为之配备的惊人算力。
AI芯片每年一更,下一代Rubin明年亮相
首先,是对训练和测试时推理能力进行大幅提升,并将在今年下半年问世的Blackwell Ultra。
根据英伟达官方博客介绍,Blackwell已经让DeepSeek-R1打破了推理性能的世界纪录。

而与Blackwell相比,Blackwell Ultra芯片还有超强进化!
它的显存从192GB提升到了288GB。而GB300 NVL72的AI性能,则比NVIDIA GB200 NVL72高出1.5倍。

接下来,是最为重磅的Vera Rubin,预计在2026年下半年发布。
这个命名致敬的是发现暗物质的天文学家Vera Rubin。

Vera Rubin有两个部分,一个称为Vera的CPU和一个称为Rubin的新GPU。
两部分一同使用时,Rubin可以在推理时实现每秒50千万亿次浮点运算,比Blackwell速度高出一倍多。
显存方面,Rubin将升级为HBM4,容量仍然为288GB。
不过,Rubin的带宽将会有大幅升级,从原来的8TB/s提高到13TB/s,提高了1.6倍。
不仅如此,NVIDIA还会为Rubin扩展NVLink,将其吞吐量提升到260TB/s,直接翻倍!
机架间的全新CX9链路达到了28.8TB/s。

不仅有标准版Rubin,老黄现场还推出了Rubin Ultra版本。
Rubin Ultra NVL576在FP4精度下进行推理任务时,性能达到了15 ExaFLOPS,在FP8精度下进行训练任务时,性能为5 ExaFLOPS。相比GB300 NVL72性能有14倍的提升。
配备HBM4e内存,带宽为4.6 PB/s,支持 NVLink 7,带宽为1.5 PB/s,较上一代提升12倍。
Rubin Ultra NVL576机架支持CX9,带宽为达到了115.2 TB/s,较上一代提升了8倍。
预计在2027年下半年推出。

Blackwell NVLink72和Rubin NVLink 576尺寸最直观的对比,再一次证明了需要在scale up之前,先要完成scale out。
|
|
|


可以看到浮点运算能力,Hopper架构是1倍提升,Blackwell 68倍提升,到了Rubin直接跃升至900倍。
另外总拥有成本(TCO),也在随着架构迭代大幅降低。

那么,英伟达是如何实现scale up?
主要是通过网络InfiniBand和Spectrum X。后者具备了低延迟和拥塞控制特性,并且成功scale up有史以来最大的单GPU集群。

不仅如此,英伟达还希望在Rubin时间框架内,将GPU的数量扩展至数十万个。而这一目标实现的主要挑战在于,大规模连接的问题。
值得一提的是,老黄官宣了英伟达首个共封装硅光子系统,也是世界上第一个每秒1.6T的CPO。
它基于一种「微环谐振器调制器」的技术(micro ring resonator modulator),并使用了台积电工艺技术构建。
|
|
|

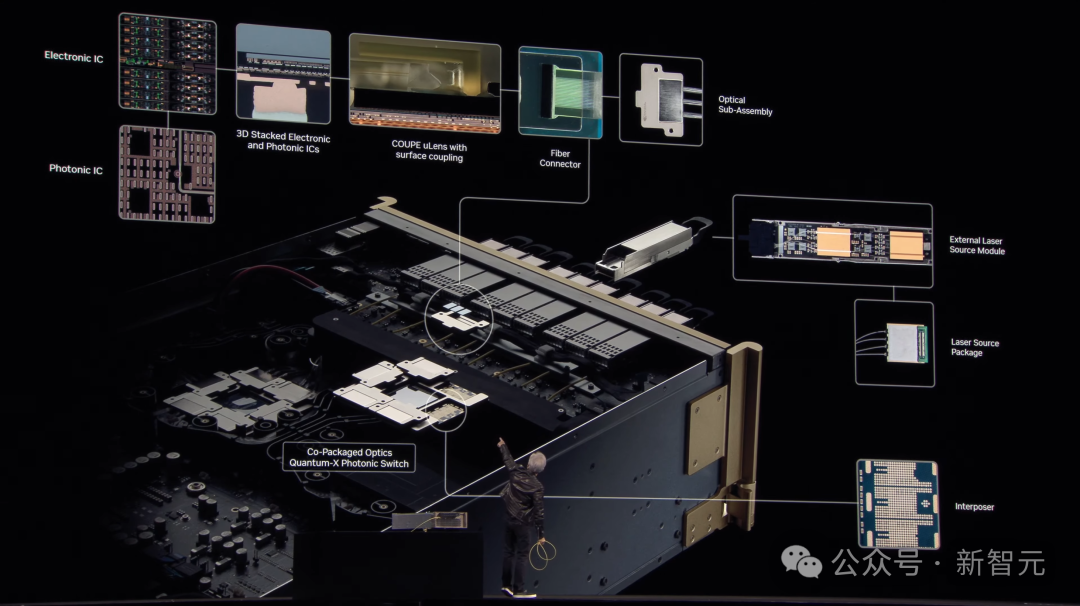
现在,具备了将硅光子学与共封装的结合,无需使用收发器,直接接入光线,并将其集成到512径基数的交换机中。
这样,便能够轻轻动动扩展至数十万,甚至百万GPU规模。

至于再下一代,则是将于2028年上市的Feynman(费曼)。
该命名致敬了美国著名理论物理学家Richard Feynman。

桌面级「黄金超算」,AI算力20000 TFLOPS
具体来说,它包括了数据中心GPU、桌面GPU,以及笔记本GPU。
这些GPU能够提供卓越的性能、效率,解锁生成式AI、智能体AI和物理AI的巨大潜力。
RTX PRO 6000 Blackwell采用了英伟达流式多处理器提供高达1.5倍吞吐量,第五代Tensor Core支持高达每秒4000万亿次AI运算,第四代RT Core性能提升高达前一代的2倍。

不仅如此,老黄还带来了两款由Blackwell驱动的DGX个人桌面AI超级计算机。
一个是DGX Spark(原名Project DIGITS),另一个是DGX Station。

老黄称,「AI已经改变了计算堆栈的每一层,理所当然就会出新一类的计算机——专为AI原生开发者设计,并运行AI原生程序」。
这两款桌面超级计算机,便是这样的存在。
DGX Spark可以称得上,世界上最小的AI超级计算机,配备128GB内存。

核心是GB10 Grace Blackwell超级芯片,能够提供每秒高达1000万亿次操作的AI计算能力,可以用于微调和推理模型。
DGX Station则将数据中心级别的性能,带到每个人桌面用于AI开发。
作为首款采用GB300 Grace Blackwell Ultra桌面超级芯片构建的系统,DGX Station配备了高达784GB的统一内存,以加速大规模训练和推理工作负载。
 |
 |

Scaling Law没撞墙,2028年数据中心将达一万亿!

GeForce将CUDA带给了全世界,而CUDA开启了AI,而AI又反过来改变了计算机图形学。
如今大火的则是智能体AI,它可以感知、理解、推理,还能计划行动,使用工具,自己访问网站去学习。
而接下来,就是物理AI,它将理解物理世界,理解摩擦、惯性、因果关系。它使机器人技术成为可能。
而这次大会上,Agentic AI和Physical AI将是全程的核心。
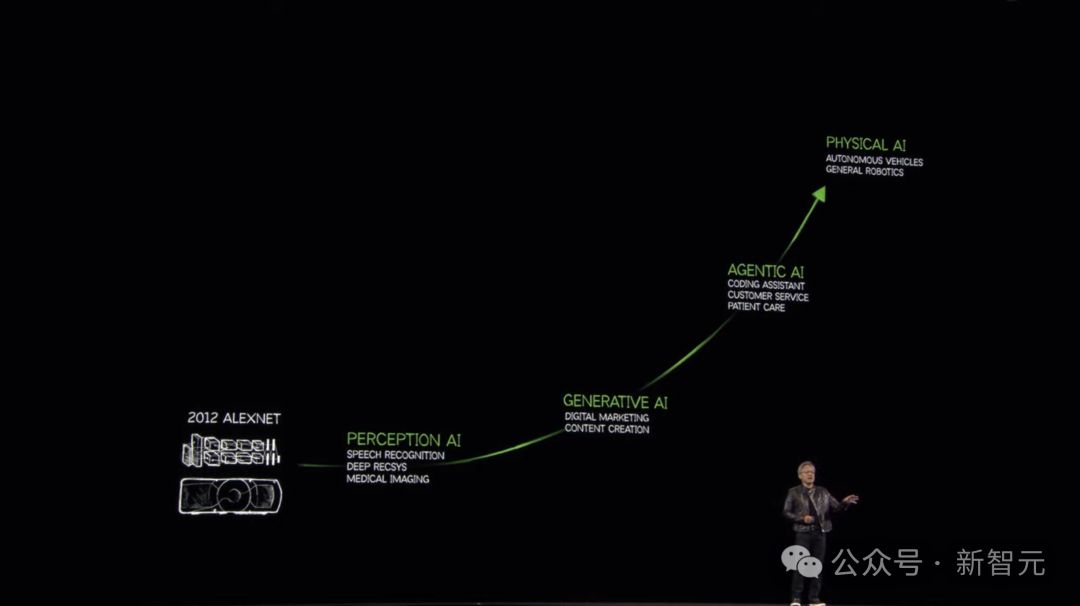
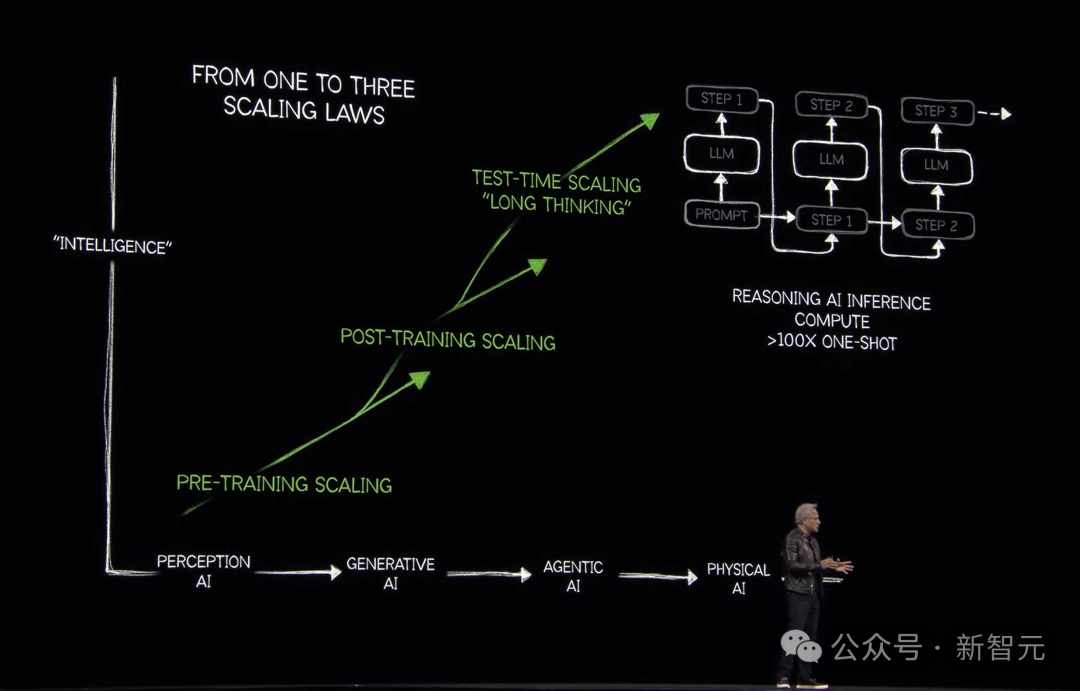
接下来,老黄重提了Scaling Law。
这涉及了三大问题:如何解决数据?如何训练模型?如何扩展?
预训练要解决数据问题,后训练解决的是human-in-the-loop问题,而测试时Scaling,则提升了AI的推理。
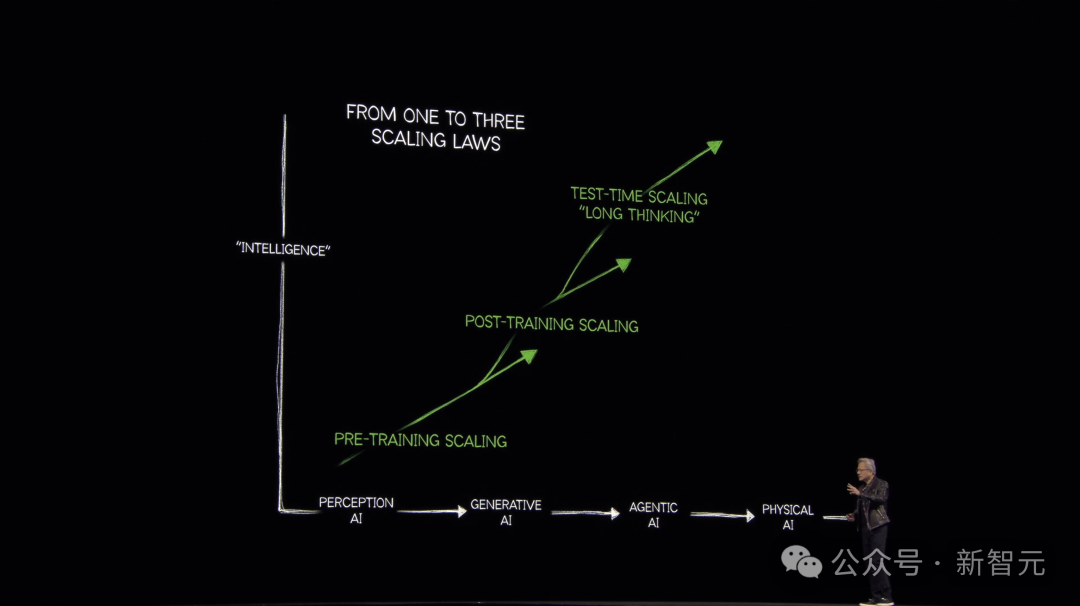
老黄表示,去年整个世界都搞错了,Scaling并没有撞墙!
从GPT开始,到如今的推理AI,它不再是仅仅预测下一个token,而是生成100多倍的token。
这样,推理计算量就更高了,计算速度必须提高10倍,如今需要的计算量比去年这个时候我们认为需要的多出100倍。
那么,数据应该从哪里来?答案就是强化学习。
通过强化学习,我们可以生成大量token,这就涉及到了合成数据,给整个行业带来巨大的计算挑战。
比较一下Hopper的峰值年份和Blackwell的第一年,会发现:AI正处于转折点。
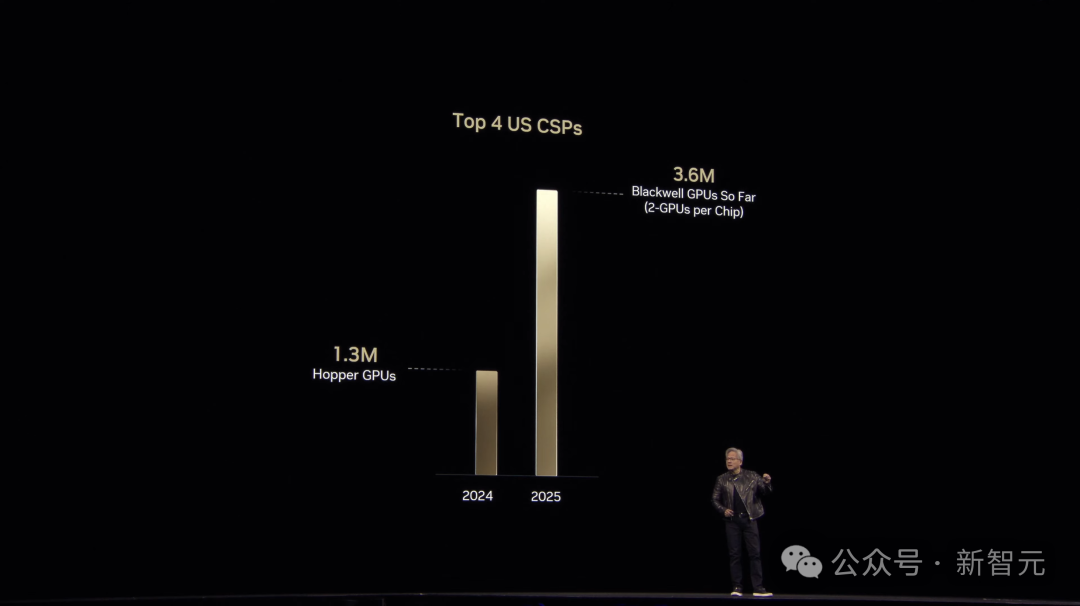
Blackwell发货才一年,我们就见证了全球AI基础设施的惊人增长。仅在2024年,全球TOP 4的云服务商买进的Hopper架构芯片就达到130万块。
老黄表示,未来数据中心建设将达到一万亿美元的规模,并且他确信,这个时间很快了!
根据预测,到2028年就能达到这个规模。
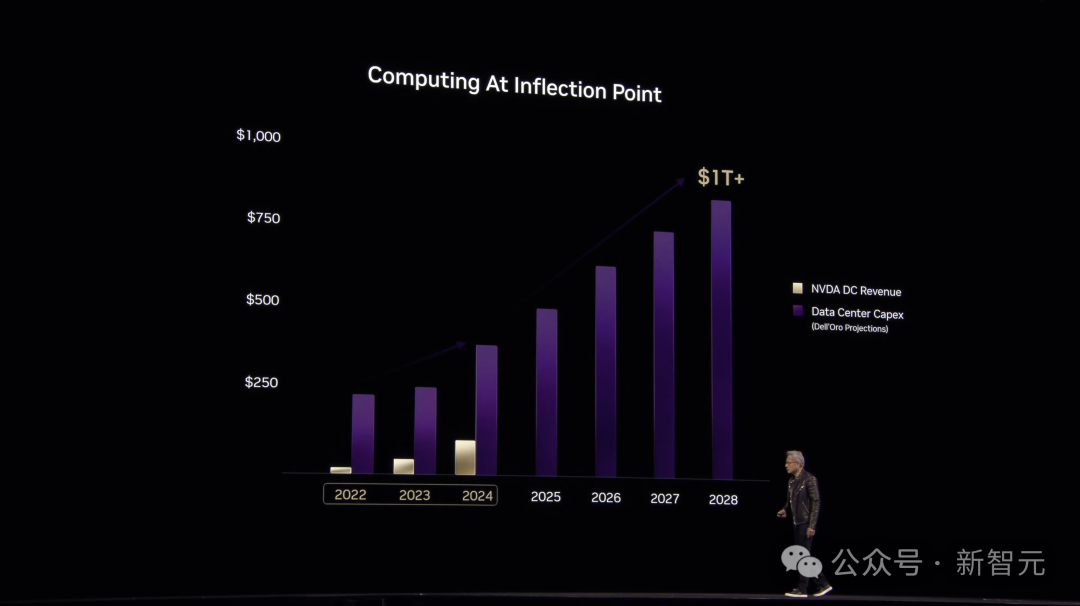
如今,通用计算已经走到了尽头,我们已经到达加速计算临界点,需要一种新的计算方法。
世界正在经历一个平台转移,从在通用计算机上运行的手写软件,转向在加速器和GPU上运行的机器学习软件。
过去,我们编写软件并在计算机上运行。未来,计算机将为软件生成token。
计算机已经成为生成token的工具,而不仅仅是文件的检索工具,老黄称之为「AI工厂」。

上面这张幻灯片,可以说是GTC最核心内容的结晶。
英伟达通过由Grace Hopper和Grace Blackwell架构支持的各种CUDA-X库,为每一个科学领域提供了加速框架。
比如,解决涉及稀疏矩阵的大型工程仿真问题的cuDSS,模拟极其复杂的量子系统的cuQuantum等等。
而这些,仅仅是使加速计算成为可能的库的样本。
如今,通过英伟达的900多个CUDA-X库和AI模型,所有人都可以加速科学研究,重塑行业,赋予机器视觉、学习和推理能力。
老黄表示,从业三十年中,最令自己感动的一件事,就是一位科学家对自己说:「Jensen,因为你的工作,我可以在有生之年完成我的毕生事业」。
如今,每年有1000亿美元的资本投入无线网络和用于通信的数据中。
加速计算的趋势已经无法阻挡,AI将进入每个行业,比如改变无线电信号。
既要大量token思考,又要快速生成
当时的想法是,使用大量商用计算机,将它们连接成一个大型网络,然而,这种方式会消耗太多电力和能力,根本无法实现深度学习。
而HGX系统架构,彻底解决了纵向扩展的问题。
 |
 |
然后,他们又做出了世界上性能最高的交换机——NVLink交换机,使得每个GPU能够同时以全带宽与其他所有GPU通信。
同时,利用液冷将计算节点也压缩到1u的托盘中,从而为行业带来了巨变。
 |
 |
于是,一个机架里,就有了一个Exaflops级别的超算。
 |
 |

最终的结果,就是英伟达实现了Scaling,可以说,这是全世界实现过最极端的Scaling。
这个过程中的计算量,可能已经达到了内存带宽每秒570TB。而这台机器,已经达到了每秒百万万亿次浮点运算。

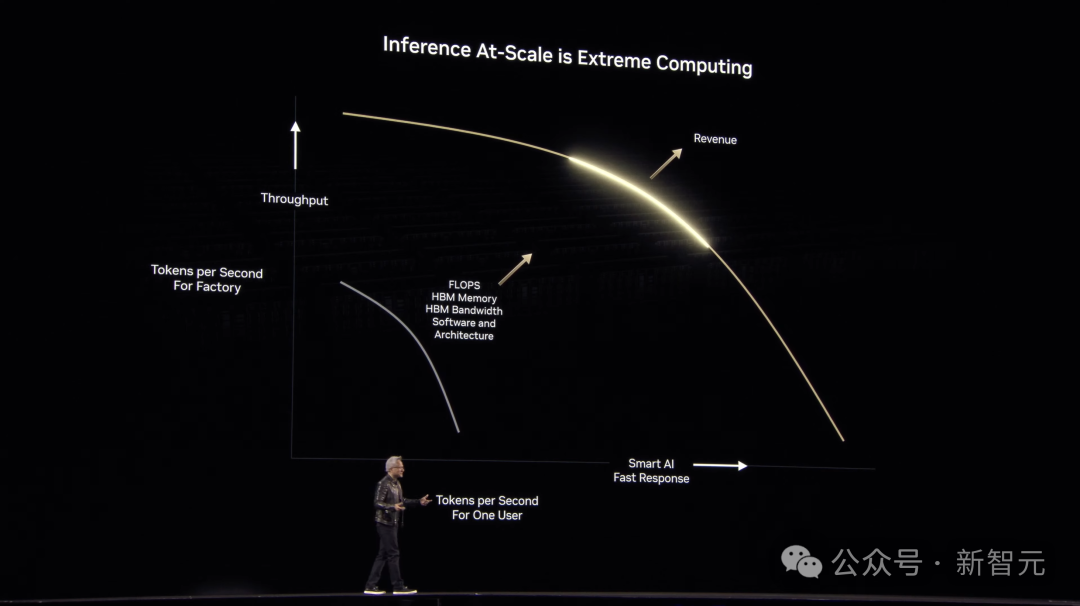
实际上,推理Scaling是一个「终极计算」问题。
推理是工厂生成token的过程,只有具备极高性能,才会提升服务质量,以及收入和盈利的能力。
生成的token越多,AI就越智能。但问题是,吞吐时间太长且速率慢,客户也不愿意买账。
因此,在计算工厂中,响应时间和吞吐量中间,存在着基本的矛盾关系。
老黄展示这张图中,x轴代表了生成的token,y轴代表着每秒token吞吐效率,理想情况下,图中黄色曲线应该是一个方形,即在工厂能力极限之内,非常快速生成token。
然而, 现实没有哪个工厂可以做到这点。
曲线才是最符合现实的一种,工厂的目标是最大化曲线下方的面积,越是向外推,代表着建造的工厂越优秀。
另一个维度,则需要巨大的带宽、最大的浮点运算能力。
现场,老黄展示了一个传统大模型和推理模型,基于同一段提示通过思考token解决问题的关键区别。
一边是Llama 3.3 70B,另一边是DeepSeek R1。
这段提示词的大意是要求在遵循传统、拍照角度和家族争端等约束条件下,在婚礼宴会上安排宾客入座。
I need to seat 7 people around a table at my wedding reception, but my parents andin-laws should not sit next to each other. Also, my wife insists we look better in pictures when she’s on my left, but l need to sit next to my best man. How do l seat us on a roundtable? But then, what happens if we invite our pastor to sit with us?
推理模型需要消耗超过20倍的token量完成问题,计算量也随之增加了150倍。

而下一代模型,参数可能会达到万亿级别。
解决方案,就是将这些万亿级的参数分布在多个GPU上,通过管线并行、张量并行和专家并行的组合来解决。
8000多个token,就意味着数万亿字节的信息被输入到GPU中,逐个生成token。
这,就是我们需要NVlink到根本原因——它让我们能把这些GPU组成一个巨大的GPU,实现规模的终极Scaling。
终极摩尔定律:买越多,赚越多
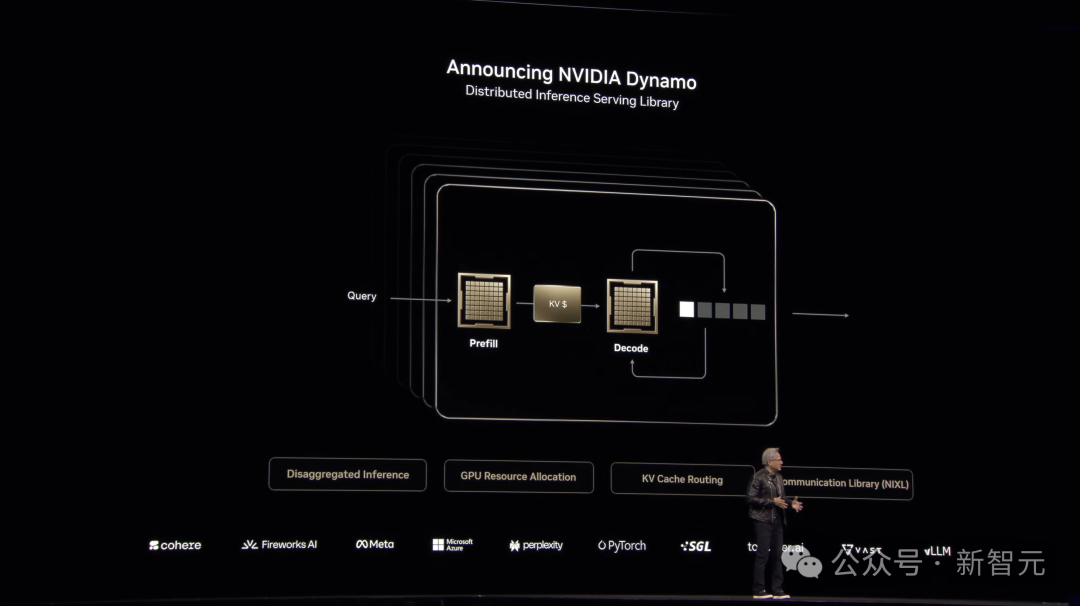
「正如发电机(Dynamo)推动了工业革命,NVIDIA Dynamo将会革新AI工厂」。
随着AI推理变得越来越主流,AI模型在每次提示下都会生成成千上万的token来进行「思考」。
如何在提高推理性能的同时,还能不断降低推理成本?
这便是NVIDIA Dynamo推出的意义。
NVIDIA Dynamo是NVIDIA Triton Inference Server的下一代产品,它能协调并加速数千个GPU之间的推理通信,并使用分布式服务把LLM的处理和生成阶段分配到不同的GPU上。
这样每个阶段都能根据自己的需求单独优化,确保GPU资源被充分利用。
在同样的GPU数量下,Dynamo能让运行Llama模型的AI工厂在Hopper架构上性能和收入双双翻倍。
在GB200 NVL72集群上运行DeepSeek-R1模型时,NVIDIA Dynamo的智能推理优化还能让每个GPU生成的token数量提升超过30倍!
为了实现这些推理性能的提升,NVIDIA Dynamo能根据请求量和类型的变化,动态添加、移除或重新分配GPU,还能在大型集群中精准找到特定GPU来减少响应计算和路由查询。
它还能把推理数据卸载到更便宜的内存和存储设备上,需要时再快速取回,尽量降低推理成本。
老黄在现场宣布NVIDIA Dynamo完全开源,支持PyTorch、SGLang、NVIDIA TensorRT-LLM和vLLM。
下图中,横轴代表为用户每秒处理的token数量,纵轴是工厂每秒处理的token吞吐量。
比如,Hopper平台用8个GPU连上InfiniBand,可以为每个用户提供100 token/秒的处理速度。
老黄开始算了起来,「有了这个坐标,我们就可以用token/秒和能耗来衡量收益了。」
比如,250万token/秒按每百万token 10美元算,就能带来每秒2500美元的收入;而如果降到10万token/秒,那也就是250美元。
而一年有3000多万秒,这直接关系到1兆瓦数据中心的年收入。
所以,目标是找到token处理速度和AI智能之间的平衡点:速度快能做聪明AI,客户愿意多付钱,但越聪明,批量生产就越难。
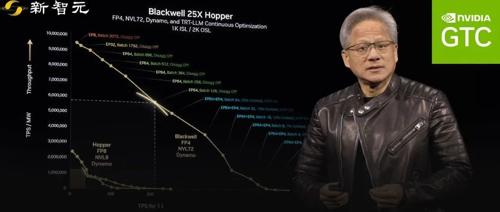
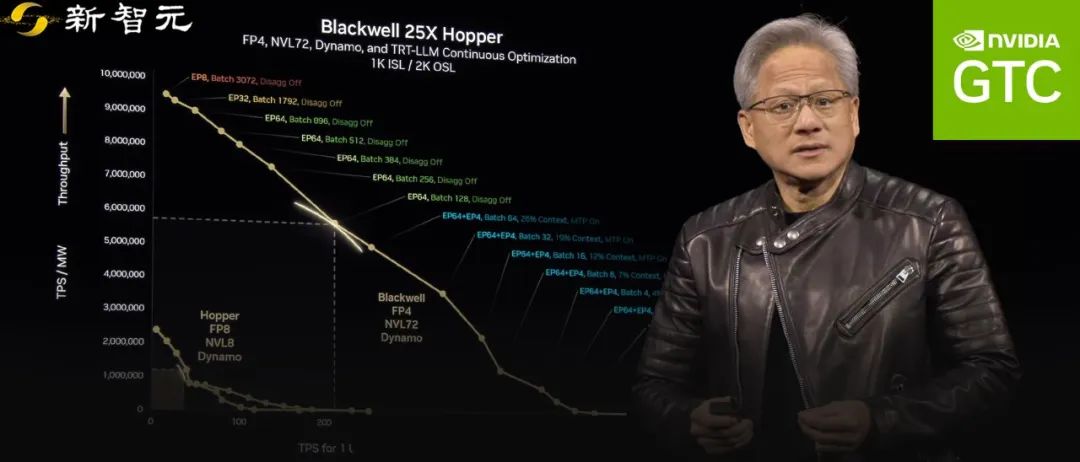
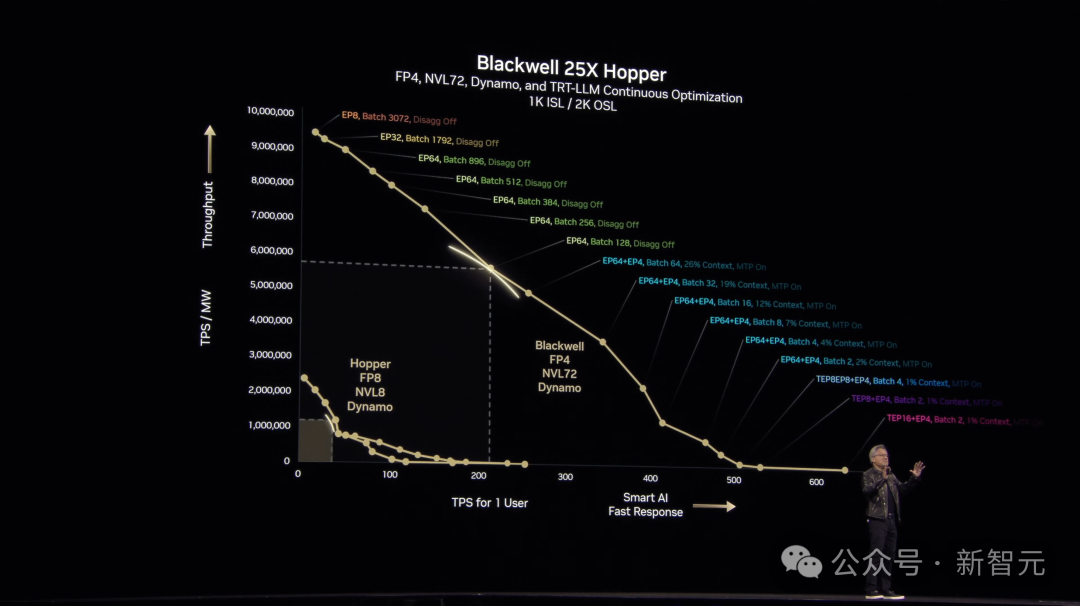
相比之下,新的Blackwell架构比Hopper强多了,尤其在能耗固定的情况下,性能提升了25倍,甚至在推理模型上直接比Hopper高40倍。
更厉害的是,Blackwell用MVLink 8技术加速,还引入了4位浮点数优化,减少能耗提升效率。
老黄表示,未来数据中心都会受限于电力,收入也跟电力挂钩,所以能效高的架构最重要。
接下来,Blackwell将扩展到MVLink 72,再加上Dynamo软件,效果将更上一层楼。
老黄表示下图里的彩虹线非常惊艳,展示了各种配置下的最佳表现。
从顶部3000批大小到底部的2批大小,配置灵活应变。
这些优化让数据中心能适应不同工作负载,证明了架构的重要性。
说到这,老黄举了个例子,在推理模型上,Blackwell的性能直接比Hopper高了40倍,真的很了不起!
「一旦Blackwell开始大规模出货,Hopper可能连送人都没人要了。」老黄在现场打趣道。
黄仁勋说,销售团队听到他这话估计要急了,担心影响会Hopper的销量。
但老黄认为,技术进步太快,工作负载又重,像AI工厂这样的大型项目,最好投资在最新版本的技术上,比如Blackwell,这样才能跟上潮流,避免落后。
接着,他拿出一个具体的例子来对比:一个100兆瓦的AI工厂用Hopper技术需要45000个芯片、1400个机架,每秒能产出3亿个token。
而同样的工厂如果用Blackwell,虽然芯片数量减少,但效率更高,整体性能更强。
老黄再次调侃道,销售团队可能觉得这是在「少卖货」,但实际上还是之前那个观点,「 the more you buy, the more you save」(买得越多,省得越多)。
甚至,现在还要更进一步:「the more you buy, the more you make」(买得越多,赚得越多)。
|
|
|


首个通用机器人模型开源,规模仅2B
具身智能也遵循着三大Scaling Law。

数据短缺成为Scaling一大难题,英伟达Omniverse和Cosmos能够同时为具身智能的训练,生成大量多样化、高质量的数据。
然后开发者利用Isaac Lab通过增强数据集后训练机器人策略,并通过模仿学习让机器人通过克隆行为来学习新技能,或者通过试错和强化学习AI反馈进行学习。

这一次,英伟达正式官宣了世界首个开源、完全可定制的通用人形机器人模型——GROOT N1。
这款模型的设计从人类认知过程汲取灵感,采用了「双系统架构」,分别可以进行快思考和慢思考。

技术报告:https://d1qx31qr3h6wln.cloudfront.net/publications/GR00T%20N1%20Whitepaper.pdf
在视觉语言模型驱动下,慢思考系统(System 2)能够对环境和指令进行推理,然后规划出正确的行动。
快思考系统(System 1),可以将上述计划转化为机器人精确、连续的动作,包括操纵物体、执行多步骤序列的能力。
值得一提的是,System 1是基于人类演示数据和Omniverse生成大量的合成数据进行训练的。
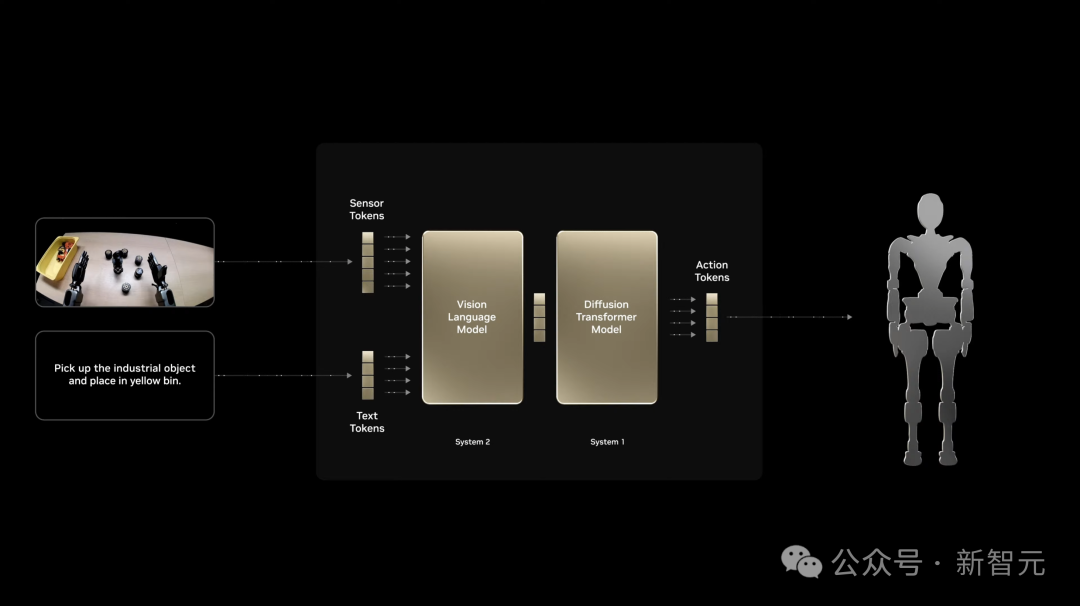
GROOT N1可以轻松在上见任务中进行泛化,或执行需要长上下文和多种通用技能组合的多步骤任务。
比如,抓取、用一只手臂/两只手臂移动物体,以及在两个手臂之间传递物品。

此外,英伟达还与DeepMind、迪士尼研究一起开发下一代开源的Newton物理引擎,能够让机器人学习如何更精确处理复杂任务。
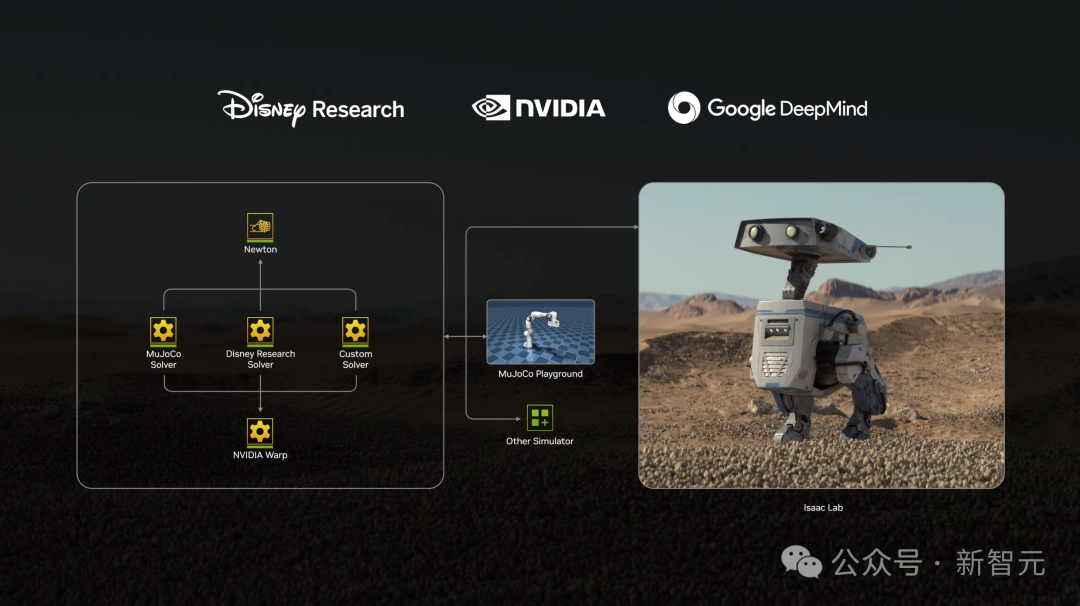
随后,以星球大战BDX机器人为灵感,装上Newton引擎的Blue上台和老黄来了一波有趣的互动。

最后,老黄预言:在未来,机器人领域将成为最大的产业。
毫无疑问,英伟达又一次成为了赢家。
|
|
|


(文:新智元)