


极市导读
本文介绍了一种名为 TSP3D 的高效 3D 视觉定位框架,通过语言引导的空间剪枝和多层稀疏卷积架构,实现了高精度和快速推理,在 ScanRefer 和 ReferIt3D 数据集上达到了 SOTA 性能,同时显著提升了推理速度。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
很开心我们最近的工作拿到了CVPR的满分,这也是继 DSPDet3D 之后三维空间剪枝在3DVG任务中的一次成功的尝试。在这篇文章中,我们提出了TSP3D,一个高效的3D视觉定位(3D Visual Grounding)框架,在性能和推理速度上均达到SOTA。此外,文中还包含了我们将三维稀疏卷积引入3D Visual Grounding任务中遇到的挑战,以及我们的探索和思考。
Text-guided Sparse Voxel Pruning for Efficient 3D Visual Grounding
论文:https://arxiv.org/abs/2502.10392
代码仓库:https://github.com/GWxuan/TSP3D
简介
3D视觉定位(3D Visual Grounding, 3DVG)任务旨在根据自然语言描述在三维场景中定位指定的目标对象。这一多模态任务具有很大挑战性,需要同时理解3D场景和语言描述。在实际应用(如机器人、AR/VR)中对模型的效率有着较高的要求,但现有方法在推理速度上受到了一定限制。早期的方法[1,2]大多采用两阶段框架:首先通过3D目标检测在场景中找到所有候选物体,然后结合文本信息在第二阶段选出与描述匹配的目标。这种方法虽然直观,但由于两个阶段分别提取特征,存在大量冗余计算,难以满足实际应用中的推理速度要求。为提升效率,随后出现了单阶段方法[3,4],直接从点云数据中定位目标物体,将目标检测与语言匹配一步完成。然而,现有单阶段方法大多同样基于点云处理架构(PointNet++[5]等),其特征提取需要耗时的最远点采样(FPS)和近邻搜索等操作。因此当前单阶段方法距离实时推理仍有差距(推理速度不足6 FPS)。
为了解决上述问题,本文提出了一种全新的单阶段3DVG框架——TSP3D,即“Text-guided Sparse voxel Pruning for 3DVG”。TSP3D放弃被现有方法广泛使用的点云处理架构,引入了多层稀疏卷积架构来同时实现高精度和高速推理。三维稀疏卷积架构提供了更高的分辨率和更精细的场景表示,同时在推理速度上具有显著优势。同时,为了有效融合多模态信息,TSP3D针对特征融合进行了一系列设计。如上面图一所示,TSP3D在精度和推理速度方面都超过了现有方法。
方法
我们将三维稀疏卷积引入3DVG任务时遇到了诸多挑战,我们在文中介绍了这些挑战以及我们的思考和分析,希望能够对研究社区有所帮助。
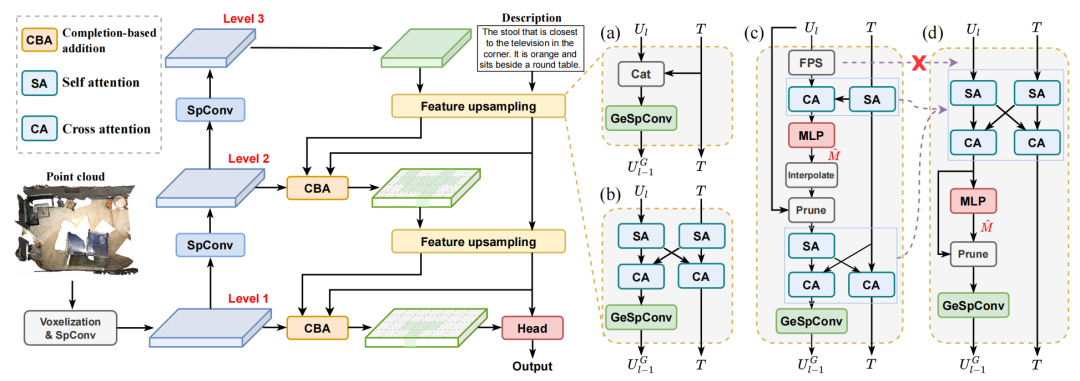
架构分析
-
点云处理架构:特征提取需要耗时的最远点采样(FPS)和近邻搜索等操作,同时受到场景表示的空间分辨率限制。
-
直接引入多层稀疏卷积(TSP3D-B):如上图(a)所示,场景特征和文本特征通过简单的拼接进行融合,推理速度快(14.58 FPS),但融合效果差,精度低。
-
改为attention机制的特征融合:如上图(b)所示,由于生成式稀疏卷积的作用,体素数量(场景表示的分辨率)极高,导致进行attention计算时显存溢出,在消费级显卡上难以训练和推理。
-
引入基于文本引导的体素剪枝(TSP3D):如上图(c)所示,根据语言描述逐步修剪对目标定位没有帮助的voxel,极大程度上减小了计算量,并提高推理速度。
-
简化的TSP3D(主推版):去掉了最远点采样和插值,将多个attention模块重新组合,进一步提高计算效率。
文本引导的体素剪枝(Text-guided Pruning, TGP)
TGP的核心思想是赋予模型两方面的能力:(1)在文本引导下修剪冗余体素来减少特征量;(2)引导网络将注意力逐渐集中到最终目标上。我们的TSP3D包含3 level的稀疏卷积和两次特征上采样,因此相应设置了两阶段的TGP模块:场景级TGP (level 3 to 2) 和目标级TGP (level 2 to 1)。场景级TGP旨在区分物体和背景,用来修剪背景上的体素。目标级TGP侧重于文本中提到的区域,保留目标对象和参考对象,同时修剪其他区域的体素。
TGP的作用分析:引入TGP后,level 1的体素数减少到原来的7%左右,并且精度得到了显著提高。这归功于TGP的多种功能:(1)通过attention机制促进多模态特征之间的交互;(2)通过剪枝减少特征数量;(3)基于文本特征逐渐引导网络集中注意力到最终目标上。
基于补全的场景特征融合(Completion-based Addition, CBA)
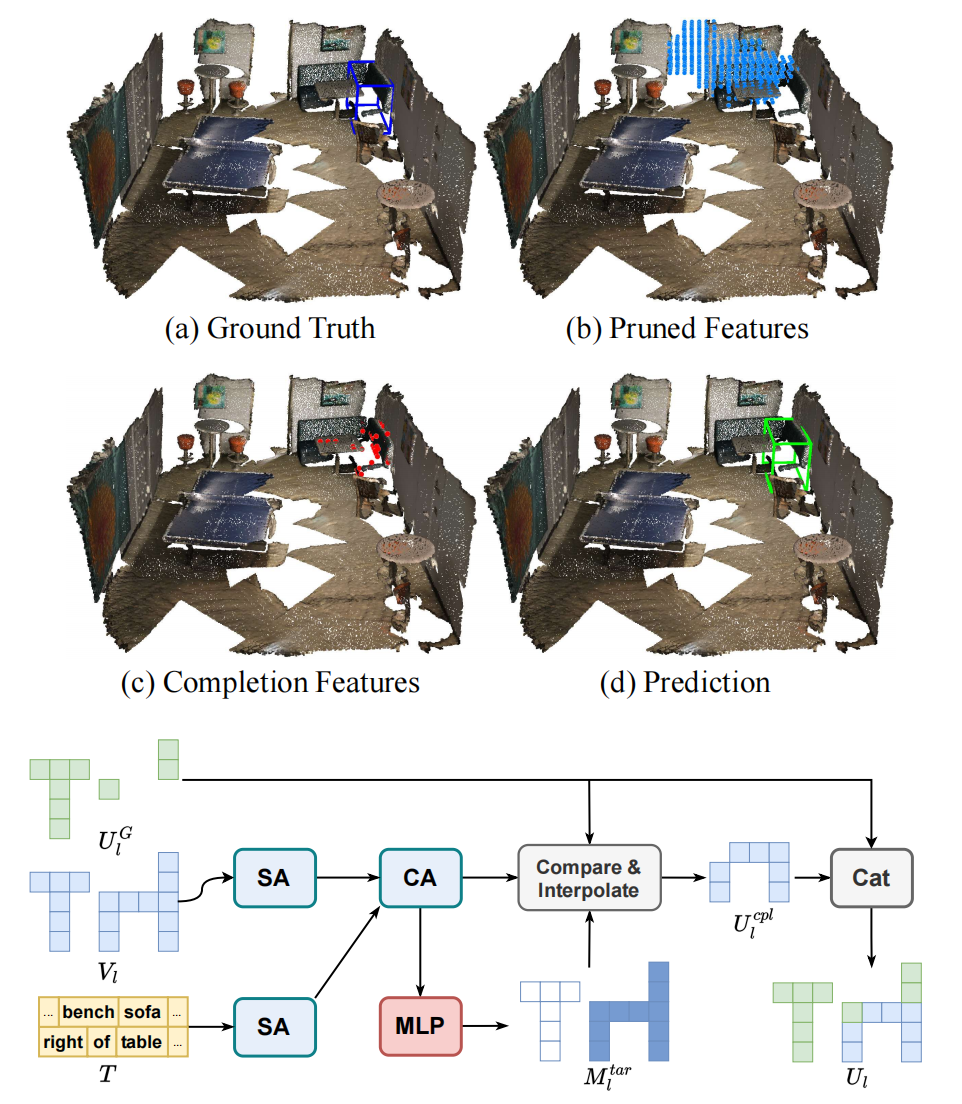
在剪枝过程中,一些目标体素可能会被错误地去除,尤其是对于较小或较窄的目标。因此,我们引入了基于补全的场景特征融合模块(CBA),它提供了一种更有针对性且更有效的方法来融合multi-level特征。CBA用于backbone特征和上采样的剪枝特征融合,基于完整性较好的backbone特征对剪枝特征进行补充。同时,CBA引入的额外计算开销可以忽略不计。方法细节请参见文章。
实验结果
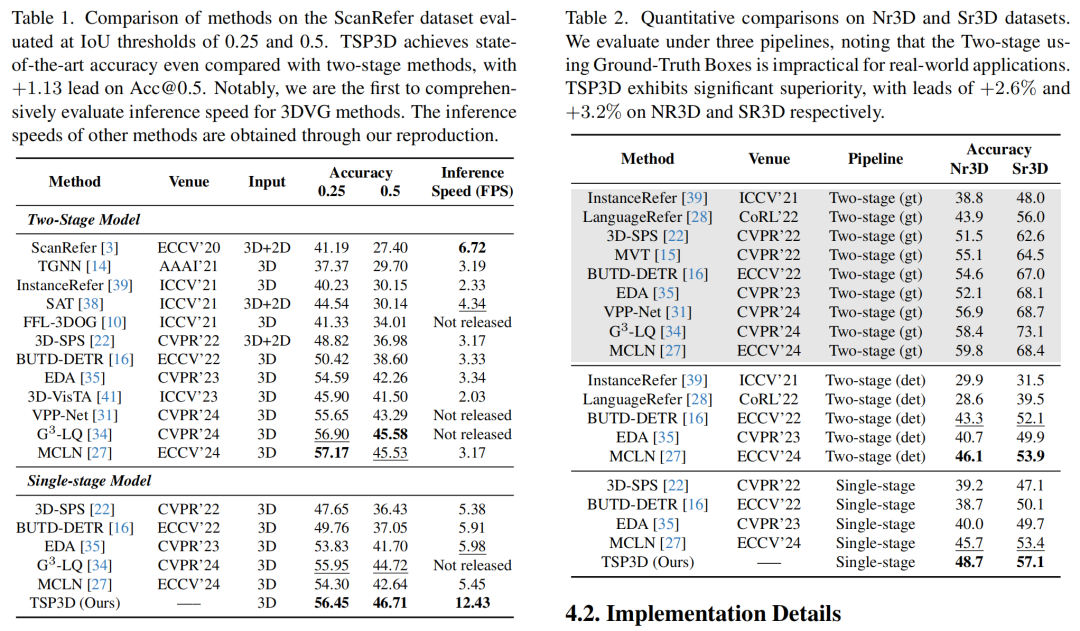
我们在主流的3DVG数据集ScanRefer[1]和ReferIt3D[6]上进行了实验。我们是第一个全面评估3DVG方法的推理速度的工作,所有方法的推理速度在一个消费级的RTX 3090上测得。下面是两个主表的结果,左侧为ScanRefer数据集,右侧为ReferIt3D数据集。
我们进行了一些列消融实验,证明我们提出方法的有效性:

我们对文本引导的体素剪枝(TGP)进行了可视化。在每个示例中从上到下为:场景级TGP、目标级TGP和最后一个上采样层之后的体素特征。蓝框表示目标的ground truth,红框表示参考对象的bounding box。可以看出,TSP3D通过两个阶段的剪枝减少体素特征的数量,并逐步引导网络关注最终目标。
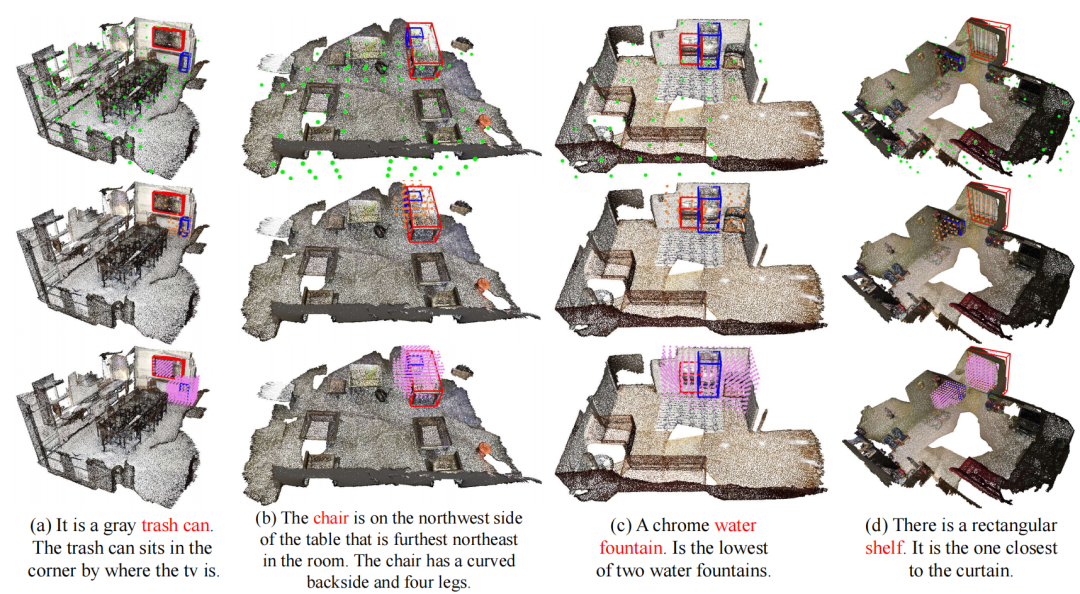
此外,我们对基于补全的场景特征融合(CBA)进行了可视化,展示了CBA自适应补全过度剪枝造成的目标体素缺失。图中蓝色点表示目标级TGP输出的体素特征,红色点表示CBA预测的补全特征,蓝色框表示ground truth。

下图展示了与其他方法的定性比较,TSP3D在定位相关目标、窄小目标、识别类别以及区分外观和属性方面表现出色。

更多实验、可视化可以参考我们的论文以及补充材料。如有问题欢迎大家在github上开issue讨论~
参考文献
[1] Dave Zhenyu Chen, Angel X Chang, and Matthias Nießner. Scanrefer: 3d object localization in rgb-d scans using natural language. In ECCV, pages 202–221. Springer, 2020.
[2] Pin-Hao Huang, Han-Hung Lee, Hwann-Tzong Chen, and Tyng-Luh Liu. Text-guided graph neural networks for referring 3d instance segmentation. In AAAI, pages 1610–1618, 2021.
[3] Junyu Luo, Jiahui Fu, Xianghao Kong, Chen Gao, Haibing Ren, HaoShen, HuaxiaXia, and SiLiu. 3d-sps: Single-stage 3d visual grounding via referred point progressive selection. In CVPR, pages 16454–16463, 2022.
[4] Yanmin Wu, Xinhua Cheng, Renrui Zhang, Zesen Cheng, and Jian Zhang. Eda: Explicit text-decoupling and dense alignment for 3d visual grounding. In CVPR, pages 19231-19242, 2023.
[5] Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In NeurIPS, 30, 2017.
[6] Panos Achlioptas, Ahmed Abdelreheem, Fei Xia, Mohamed Elhoseiny, and Leonidas Guibas. Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes. In ECCV, pages 422–440. Springer, 2020.

(文:极市干货)