
当前主流OCR系统通常都需要1B+参数的大模型计算,近期刚好在抱抱脸上发现一款仅256M参数的轻量级全能型文档OCR模型工具。
一个名为 SmolDocling 的 OCR 模型,轻量级、高速且支持完整文档OCR的多模态视觉语言模型,能在 每页 0.35 秒 内完成文档解析。
它支持布局识别、代码识别、公式解析、表格解析、图表提取 等多种任务,并能导出为 Markdown、HTML、JSON 等格式。

核心能力
1、全文档 OCR 解析
-
• 智能识别标题、正文、列表、表格、图表、代码、公式等内容。 -
• 适用于学术论文、商业文档、专利、报告、手写文档等多种文档类型。
2、轻量 & 高速
-
• 256M 小型参数,可在 CPU/低配 GPU 上运行,无需高端计算资源。 -
• OCR 速度快,每页仅需 0.35 秒,适用于批量处理。
3、多样化元素识别
布局识别、代码识别、公式识别、图表与表格、图形分类等。
4、灵活的输出格式
支持导出为 Markdown、HTML、JSON 等多种格式。
5、批量处理支持
可一次性处理多个文档,适合大规模数据转换。
快速使用
要想使用这个最新的 SmolDocling,有两种方法:在线Demo、代码调用。
在线Demo
官方也在 HuggingFace 上部署了SmolDocling-256M-preview的Demo,可直接体验其强大的功能。
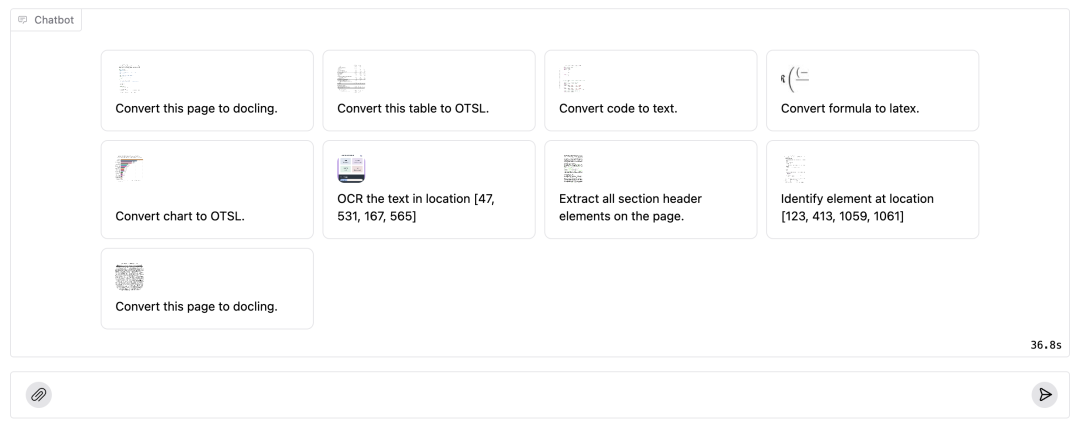
Demo地址:https://huggingface.co/spaces/ds4sd/SmolDocling-256M-Demo
代码调用
使用Transformers进行单页图像推理
# Prerequisites:
# pip install torch
# pip install docling_core
# pip install transformers
import torch
from docling_core.types.doc import DoclingDocument
from docling_core.types.doc.document import DocTagsDocument
from transformers import AutoProcessor, AutoModelForVision2Seq
from transformers.image_utils import load_image
DEVICE = "cuda"if torch.cuda.is_available() else"cpu"
# Load images
image = load_image("https://upload.wikimedia.org/wikipedia/commons/7/76/GazettedeFrance.jpg")
# Initialize processor and model
processor = AutoProcessor.from_pretrained("ds4sd/SmolDocling-256M-preview")
model = AutoModelForVision2Seq.from_pretrained(
"ds4sd/SmolDocling-256M-preview",
torch_dtype=torch.bfloat16,
_attn_implementation="flash_attention_2"if DEVICE == "cuda"else"eager",
).to(DEVICE)
# Create input messages
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "Convert this page to docling."}
]
},
]
# Prepare inputs
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[image], return_tensors="pt")
inputs = inputs.to(DEVICE)
# Generate outputs
generated_ids = model.generate(**inputs, max_new_tokens=8192)
prompt_length = inputs.input_ids.shape[1]
trimmed_generated_ids = generated_ids[:, prompt_length:]
doctags = processor.batch_decode(
trimmed_generated_ids,
skip_special_tokens=False,
)[0].lstrip()
# Populate document
doctags_doc = DocTagsDocument.from_doctags_and_image_pairs([doctags], [image])
print(doctags)
# create a docling document
doc = DoclingDocument(name="Document")
doc.load_from_doctags(doctags_doc)
# export as any format
# HTML
# doc.save_as_html(output_file)
# MD
print(doc.export_to_markdown())使用VLLM进行快速批量推理
# Prerequisites:
# pip install vllm
# pip install docling_core
# place page images you want to convert into "img/" dir
import time
import os
from vllm import LLM, SamplingParams
from PIL import Image
from docling_core.types.doc import DoclingDocument
from docling_core.types.doc.document import DocTagsDocument
# Configuration
MODEL_PATH = "ds4sd/SmolDocling-256M-preview"
IMAGE_DIR = "img/"# Place your page images here
OUTPUT_DIR = "out/"
PROMPT_TEXT = "Convert page to Docling."
# Ensure output directory exists
os.makedirs(OUTPUT_DIR, exist_ok=True)
# Initialize LLM
llm = LLM(model=MODEL_PATH, limit_mm_per_prompt={"image": 1})
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192)
chat_template = f"<|im_start|>User:<image>{PROMPT_TEXT}<end_of_utterance>
Assistant:"
image_files = sorted([f for f in os.listdir(IMAGE_DIR) if f.lower().endswith((".png", ".jpg", ".jpeg"))])
start_time = time.time()
total_tokens = 0
for idx, img_file inenumerate(image_files, 1):
img_path = os.path.join(IMAGE_DIR, img_file)
image = Image.open(img_path).convert("RGB")
llm_input = {"prompt": chat_template, "multi_modal_data": {"image": image}}
output = llm.generate([llm_input], sampling_params=sampling_params)[0]
doctags = output.outputs[0].text
img_fn = os.path.splitext(img_file)[0]
output_filename = img_fn + ".dt"
output_path = os.path.join(OUTPUT_DIR, output_filename)
withopen(output_path, "w", encoding="utf-8") as f:
f.write(doctags)
# To convert to Docling Document, MD, HTML, etc.:
doctags_doc = DocTagsDocument.from_doctags_and_image_pairs([doctags], [image])
doc = DoclingDocument(name="Document")
doc.load_from_doctags(doctags_doc)
# export as any format
# HTML
# doc.save_as_html(output_file)
# MD
output_filename_md = img_fn + ".md"
output_path_md = os.path.join(OUTPUT_DIR, output_filename_md)
doc.save_as_markdown(output_path_md)
print(f"Total time: {time.time() - start_time:.2f} sec")写在最后
SmolDocling 是一款轻量级、超快、可全文档解析的多模态 OCR 模型,比传统 OCR 更精准、更高效,适用于 论文解析、合同分析、数据提取、知识库构建等任务。
不仅支持完整文档 OCR,包括表格、代码、公式、图表,处理速度也超快,每页仅需 0.35 秒,还可导出多种格式,适合许多不同需求的人群。
如果你正在寻找 一款快速、高效的 OCR 工具,SmolDocling 绝对值得一试!
模型地址:https://huggingface.co/ds4sd/SmolDocling-256M-preview

● 一款改变你视频下载体验的神器:MediaGo
● 新一代开源语音库CoQui TTS冲到了GitHub 20.5k Star
● 最新最全 VSCODE 插件推荐(2023版)
● Star 50.3k!超棒的国产远程桌面开源应用火了!
● 超牛的AI物理引擎项目,刚开源不到一天,就飙升到超9K Star!突破物理仿真极限!

(文:开源星探)