
大模型已经进入生产落地时代,一些工程性问题逐渐暴露,从计算资源需求激增、内存瓶颈到分布式协调困难,传统的推理服务架构已难以应对。
近日,NVIDIA 在其开发者大会推出一个开源高性能推理框架——Dynamo,专为解决大规模分布式环境中的生成式AI模型服务难题而设计。它以Rust语言为主(55.5%)构建,同时融合Go(28.5%)和Python(9.3%),确保了高性能与易扩展性的完美结合。
官方测试显示,Dynamo在NVIDIA GB200 NVL72上服务DeepSeek-R 67B模型时,吞吐量提升了30倍;在NVIDIA Hopper架构上服务Llama 70B模型时,吞吐量提升超过2倍。
核心组件
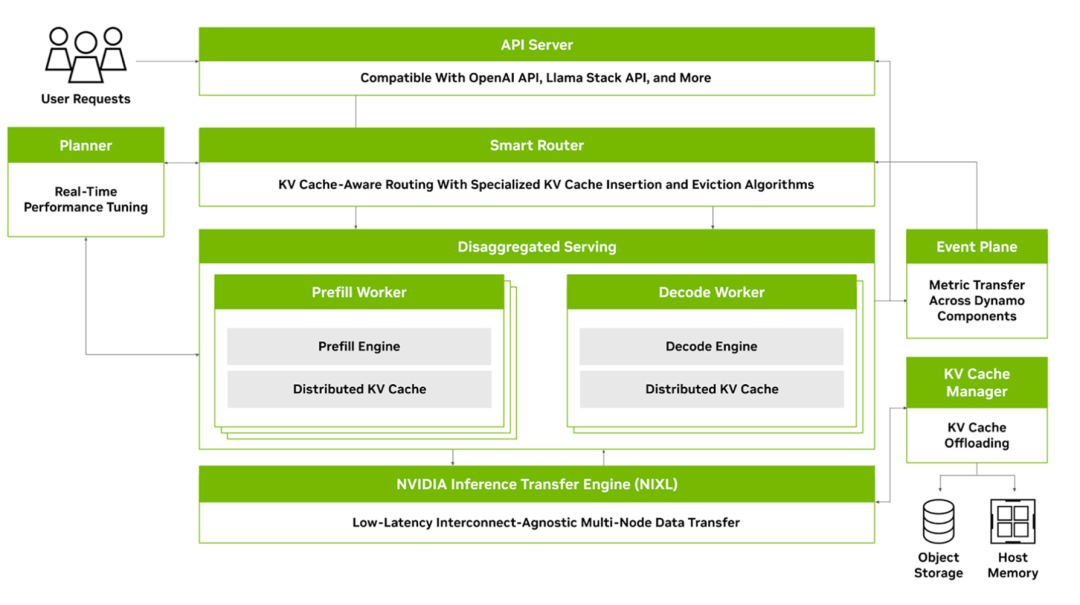
Dynamo由四个关键组件构成,共同解决分布式和解耦推理服务的挑战:
-
GPU资源规划器:监控多节点部署中的容量和预填充活动,调整GPU资源分配 -
智能路由器:KV缓存感知路由引擎,高效引导流量,最小化昂贵的重复计算 -
低延迟通信库:加速GPU间KV缓存传输,支持异构内存和存储类型 -
KV缓存管理器:成本感知的KV缓存卸载引擎,释放宝贵的GPU内存
核心优势
Dynamo提供了几项关键优势:
-
推理引擎无关性:支持TRT-LLM、vLLM、SGLang等多种推理引擎,一次开发多处部署,解决了技术栈割裂问题。 -
分离式预填充与解码:智能拆分推理阶段,最大化GPU利用率,灵活平衡吞吐量与延迟,解决了计算资源瓶颈。 -
动态GPU调度:根据负载波动实时优化资源分配,避免资源浪费和性能瓶颈,应对了不均衡负载问题。 -
NIXL加速数据传输:专为AI负载优化的通信协议,显著降低推理响应时间,解决了分布式环境中的通信开销。 -
多级KV缓存管理:巧妙利用GPU内存、系统内存甚至SSD,大幅提升服务容量,突破了内存限制。
KV缓存路由:突破性创新
在LLM推理中,KV缓存管理是性能优化的关键。传统Transformer架构在生成每个token时都会计算并存储key-value对,这些缓存占用大量GPU内存,但对加速后续生成至关重要。
在分布式环境中,如果没有全局的KV缓存管理,会导致两个严重问题:一是缓存复用机会丢失,增加不必要的计算;二是系统负载不均衡,降低整体吞吐量。这正是当前行业面临的技术瓶颈。
Dynamo通过创新的KV缓存路由机制突破了这一瓶颈:
-
KVPublisher:嵌入各工作节点,实时发布缓存块创建和移除事件 -
KVIndexer:维护全局前缀树,精确追踪所有节点上的缓存状态 -
KvMetricsAggregator:收集各节点负载指标,提供整体视图
当新请求到达时,路由器会查询匹配的缓存块并分析节点负载,使用智能成本函数找到最佳平衡点。例如,即使某节点有75%的缓存匹配,但负载达80%,系统可能会选择匹配率50%但负载较低的节点,确保整体性能最优。
+---------+ +------------------+ +---------+
| Tokens |--------->| KV Aware Router |---------> | Worker 2|
+---------+ +------------------+ +---------+
|
+------------------+------------------+
| | |
| KV匹配: 5% | KV匹配: 50% | KV匹配: 75%
v v v
+----------------+ +----------------+ +----------------+
| Worker | | Worker 2 | | Worker 3 |
| (负载: 30%) | | (负载: 50%) | | (负载: 80%) |
+----------------+ +----------------+ +----------------+
模块化架构设计
面对复杂多变的生产环境需求,Dynamo采用了高度模块化的三层架构:
1. 命名空间(Namespace):逻辑隔离的资源空间,支持多租户部署
2. 组件(Component):独立可部署的功能单元,通常对应Docker容器
3. 端点(Endpoint):组件上的功能接口,支持发现和调用
这种设计使Dynamo能够构建灵活的推理服务图,支持单一输入与多输出流式传输,为现代AI应用提供理想平台,解决了传统架构的扩展性限制。
简单易用的部署体验
尽管技术先进,但Dynamo保持了简单直观的用户体验。对于简单场景,只需一行命令即可启动服务:
dynamo run out=vllm deepseek-ai/DeepSeek-R-Distill-Llama-8B
对于生产环境,典型的部署包括两个步骤:
# 启动运行时服务
docker compose -f deploy/docker-compose.yml up -d
# 启动LLM服务组件
cd examples/llm
dynamo serve graphs.agg:Frontend -f configs/agg.yaml
系统提供完全兼容OpenAI的API接口,客户端可以使用标准HTTP请求访问,降低了开发者的迁移和学习成本:
curl localhost:8000/v/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-R-Distill-Llama-8B",
"messages": [{"role": "user", "content": "Hello"}],
"stream":false,
"max_tokens": 300
}'
结语
在AI模型规模不断增长、推理性能要求日益提高的当下,NVIDIA Dynamo为解决分布式LLM服务的关键挑战提供了创新解决方案。它不仅克服了KV缓存管理、负载均衡和资源利用率等行业痛点,还通过灵活架构为未来AI系统设计提供了新思路。随着企业AI应用从实验走向规模化部署,Dynamo这样的分布式推理框架将在AI落地进程中发挥越来越重要的作用。
项目地址:https://github.com/ai-dynamo/dynamo
(文:AI工程化)