

英伟达CEO黄仁勋在2025年GTC大会上给所有人画了一个大大的“饼”。

那么,这“饼”好吃吗?
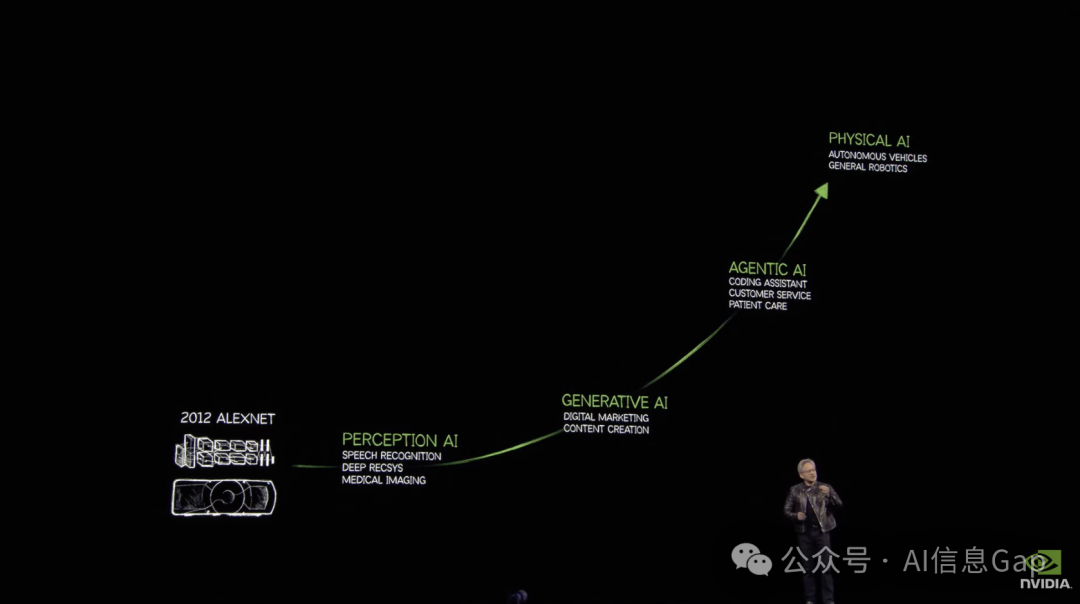
AI计算模式的转变
-
人工智能正从基于检索的计算模型转向生成式模型 -
数据中心正演变为”AI工厂”,专注于生成Token作为AI的基础单元 -
推理过程(AI生成输出)已成为计算密集型的关键工作负载
Blackwell架构技术特点
-
新一代Blackwell GPU架构已进入全面生产阶段 -
引入MVLink 72技术,使单机架能提供exaflop级AI计算性能 -
采用液冷技术提高密度和能效 -
开发新的FP4精度格式以提升能源效率 -
推出Nvidia Dynamo操作系统,用于优化AI工作负载分配和资源管理
产品路线图
-
建立了年度架构和产品更新计划 -
公布了未来几代产品:Blackwell Ultra(2024下半年)、Vera Rubin(2025下半年)、Rubin Ultra(2026下半年)和Fineman -
每代产品将在性能扩展和能效方面提供改进

网络技术发展
-
Infiniband和Spectrum X在AI基础设施扩展中仍发挥重要作用 -
推出首个采用微环谐振器调制器(MRM)技术的共封装光学解决方案,降低高带宽光互连的功耗
企业AI和机器人技术
-
发布面向开发者和企业的新型DGX系统(DGX Spark和DGX Station) -
强调AI在机器人领域的应用,展示模拟、训练和数据生成方面的进展 -
推出并开源Groot N1人形机器人通用基础模型 -
宣布与DeepMind和迪士尼研究合作开发名为Newton的GPU加速物理引擎
以下中文翻译由 Gemini 2.0 Pro 提供支持。
(0:09-1:01) Introduction: The Age of AI Tokens (引言:AI Token时代)
This is how intelligence is made, a new kind of factory: a generator of tokens, the building blocks of AI.
这就是智能的产生方式,一种新型工厂:生成Token,这是AI的基石。
Tokens have opened a new frontier, the first step into an extraordinary world where endless possibilities are born.
Token开启了新的前沿,这是迈向非凡世界的第一步,在那里,无限的可能性得以诞生。
Tokens transform images into scientific data, charting alien atmospheres and guiding the explorers of tomorrow. They turn raw data into foresight, so next time we’ll be ready.
Token将图像转化为科学数据,描绘外星大气,指引未来的探索者。它们将原始数据转化为远见,让我们为下一次做好准备。
(1:01-1:40) Tokens: Decoding and Unraveling (Token:解码与揭示)
Tokens decode the laws of physics to get us there faster and take us further.
Token解码物理定律,让我们更快到达目的地,走得更远。
Tokens see disease before it takes hold. They help us unravel the language of life and learn what makes us tick.
Token在疾病扎根之前就发现它。它们帮助我们解开生命的语言,了解是什么让我们运转。
(1:40-2:29) Tokens: Connecting and Empowering (Token:连接与赋能)
Tokens connect the dots so we can protect our most noble creatures. They turn potential into plenty and help us harvest our bounty.
Token连接点滴,让我们能够保护最珍贵的生物。它们将潜力转化为富饶,帮助我们收获丰硕的成果。
Tokens don’t just teach robots how to move, but to bring joy, to lend us a hand, and put life within reach.
Token不仅教会机器人如何移动,还教会它们带来欢乐,向我们伸出援手,让生活触手可及。
(2:29-3:30) Nvidia’s Role and Jensen Huang’s Welcome (英伟达的角色与黄仁勋的欢迎)
Together, we take the next great leap, to bravely go where no one has gone before. And here is where it all begins. Welcome to the stage, Nvidia founder and CEO Jensen Huang.
携手共进,我们迈出下一个伟大的飞跃,勇敢地前往无人涉足之地。而这一切,都从这里开始。欢迎英伟达创始人兼首席执行官黄仁勋登台。
Welcome to GTC!
欢迎来到GTC!
(3:38-4:49) GTC and Industry Representation (GTC与行业代表)
What an amazing year! We wanted to do this at Nvidia, so through the magic of artificial intelligence, we’re bringing you to Nvidia’s headquarters.
多么精彩的一年!我们想在英伟达做到这一点,所以通过人工智能的魔力,我们将您带到英伟达总部。
I’m up here without a net, no scripts, no teleprompter. I’ve got a lot to cover. First, I want to thank all the sponsors. Just about every single industry is represented: healthcare, transportation, retail, the computer industry… everybody in the computer industry is here.
我在这里没有依靠,没有稿子,没有提词器。我有很多内容要讲。首先,我要感谢所有的赞助商。几乎每个行业都有代表:医疗保健、交通运输、零售、计算机行业……计算机行业的每个人都在这里。
(4:49-6:30) GeForce and the Evolution of AI (GeForce与AI的演变)
GTC started with GeForce. Today, I have here a GeForce 5090. Unbelievably, 25 years later, GeForce is sold out all over the world. This is the Blackwell generation. Comparing it to the 4090, it’s 30% smaller in volume, 30% better at dissipating energy, and incredible performance.
GTC始于GeForce。今天,我这里有一块GeForce 5090。令人难以置信的是,25年后,GeForce在全球售罄。这是Blackwell一代。与4090相比,它的体积缩小了30%,散热性能提高了30%,性能令人难以置信。

GeForce brought CUDA to the world. CUDA enabled AI, and AI has now come back to revolutionize computer graphics. What you’re looking at is real-time computer graphics, 100% path traced. For every pixel rendered, artificial intelligence predicts the other 15.
GeForce将CUDA带给了世界。CUDA赋能了AI,而AI现在又回来革新了计算机图形学。您现在看到的是实时计算机图形,100%路径追踪。对于渲染的每个像素,人工智能预测其他15个。
(6:30-8:01) Generative AI and the Transformation of Computing (生成式AI与计算的变革)
Artificial intelligence has made extraordinary progress. It started with perception AI (computer vision, speech recognition), then generative AI. We’ve largely focused on generative AI, teaching an AI to translate from one modality to another (text to image, image to text, text to video, amino acids to proteins).
人工智能取得了非凡的进步。它始于感知AI(计算机视觉、语音识别),然后是生成式AI。我们主要关注生成式AI,教AI将一种模态转换为另一种模态(文本到图像、图像到文本、文本到视频、氨基酸到蛋白质)。
Generative AI fundamentally changed how computing is done. From a retrieval computing model, we now have a generative computing model. AI understands the context, generates what it knows, and if needed, retrieves information to augment its understanding.
生成式AI从根本上改变了计算的方式。从检索式计算模型,我们现在有了生成式计算模型。AI理解上下文,生成它所知道的,并在需要时检索信息以增强其理解。
(8:01-9:10) Agentic AI and Reasoning (Agentic AI与推理)
Every single layer of computing has been transformed. The last two to three years, a major breakthrough happened: agentic AI. Agentic AI means that you have an AI that can perceive, understand the context, reason, plan, and take action. It can use tools.
计算的每一层都发生了转变。过去两三年,一个重大突破发生了:Agentic AI。Agentic AI意味着你拥有一个可以感知、理解上下文、推理、计划和采取行动的AI。它可以使用工具。
At the foundation of agentic AI is reasoning.
Agentic AI的基础是推理。
(9:10-9:56) Physical AI and Robotics (物理AI与机器人)
The next wave is already happening: robotics, enabled by physical AI. Physical AI understands the physical world (friction, inertia, cause and effect, object permanence). This will enable a new era of AI.
下一波浪潮已经到来:机器人,由物理AI赋能。物理AI理解物理世界(摩擦力、惯性、因果关系、物体恒存性)。这将开启AI的新时代。
Each phase opens up new market opportunities.
每个阶段都开启了新的市场机遇。
(9:56-11:13) GTC Growth and the AI Super Bowl (GTC的增长与AI超级碗)
GTC is now jam-packed. The only way to hold more people at GTC is we’re going to have to grow San Jose.
GTC现在人满为患。容纳更多GTC参与者的唯一方法是,我们必须发展圣何塞。
Last year, GTC was described as the Woodstock of AI. This year, it’s described as the Super Bowl of AI. The only difference is everybody wins at this Super Bowl.
去年,GTC被描述为AI的伍德斯托克音乐节。今年,它被描述为AI的超级碗。唯一的区别是,在这个超级碗中,每个人都是赢家。
(11:13-12:36) Three Fundamental Matters of AI (AI的三个基本问题)
At its core, what enables each wave of AI? Three fundamental matters:
AI每一波浪潮的核心是什么?三个基本问题:
-
How do you solve the data problem? AI needs digital experience to learn.如何解决数据问题? AI需要数字经验来学习。 -
How do you solve the training problem without human in the loop? We want AI to learn at superhuman rates.如何在没有人类参与的情况下解决训练问题? 我们希望AI以超人的速度学习。 -
How do you scale? How do you find an algorithm whereby the more resources you provide, the smarter the AI becomes?如何扩展? 如何找到一种算法,使您提供的资源越多,AI就越聪明?
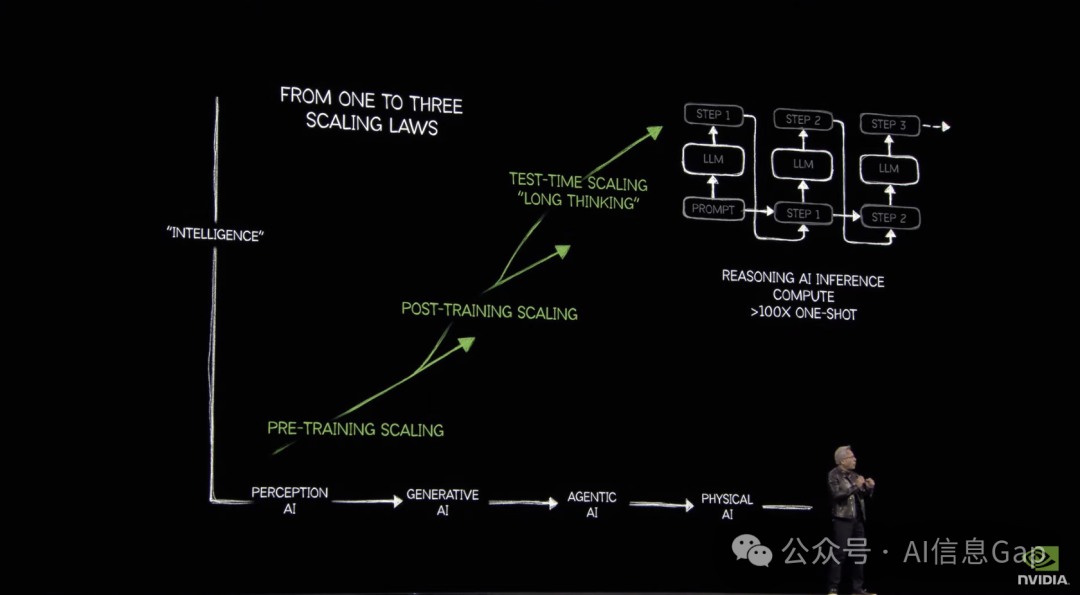
(12:36-13:08) The Misunderstanding of Computational Requirements (对计算需求的误解)
This last year, almost the entire world got it wrong. The computation requirement, the scaling law of AI, is more resilient and hyper-accelerated. The amount of computation we need is easily 100 times more than we thought last year.
去年,几乎整个世界都错了。计算需求,AI的扩展定律,更具弹性,并且加速了。我们需要的计算量很容易比去年想象的多100倍。
(13:08-15:32) Reasoning and Token Generation (推理与Token生成)
Agentic AI is at its foundation: reasoning. We now have AIs that can reason step by step. They can approach a problem in a few different ways, select the best answer, and do consistency checking.
Agentic AI的基础是:推理。我们现在拥有的AI可以逐步推理。它们可以通过几种不同的方式处理问题,选择最佳答案,并进行一致性检查。
The fundamental technology of AI is still the same: generate the next token. But the next token now makes up step one, then step two, step three… Instead of generating one word, it generates a sequence of words that represents a step of reasoning. The amount of tokens generated is substantially higher, easily 100 times more.
AI的基础技术仍然相同:生成下一个Token。但下一个Token现在构成了第一步,然后是第二步,第三步……它不是生成一个单词,而是生成一系列单词,代表推理的一个步骤。生成的Token数量大大增加,很容易达到100倍以上。
(15:32-16:14) The Impact of 100x More Tokens (100倍Token的影响)
100 times more tokens means it could generate 100 times more tokens, or the model is more complex, it generates 10 times more tokens, and we have to compute 10 times faster to keep it interactive. So, 10 times tokens, 10 times faster… the amount of computation is 100 times more, easily.
100倍的Token意味着它可以生成100倍的Token,或者模型更复杂,它生成10倍的Token,我们必须以10倍的速度计算才能保持交互性。因此,10倍的Token,10倍的速度……计算量很容易达到100倍。
(16:14-18:44) Reinforcement Learning and Synthetic Data Generation (强化学习与合成数据生成)
How do we teach an AI to reason? Reinforcement learning with verifiable results. We can generate millions of examples and give the AI hundreds of chances to solve it step by step. We’re talking about trillions and trillions of tokens to train that model. Synthetic data generation, using a robotic approach to teach AI.
我们如何教AI推理?具有可验证结果的强化学习。我们可以生成数百万个示例,并给AI数百次机会逐步解决它。我们谈论的是数万亿个Token来训练该模型。合成数据生成,使用机器人方法来教AI。
(18:44-20:10) The Growth of AI Infrastructure (AI基础设施的增长)
The combination of these things has put an enormous challenge of computing in front of the industry. You can see the industry is responding. This is Hopper shipments of the top four CSPs (Amazon, Azure, GCP, OCI). Comparing the peak year of Hopper and the first year of Blackwell, you can see the incredible growth in AI infrastructure.
这些因素的结合给行业带来了巨大的计算挑战。你可以看到行业正在做出回应。这是四大CSP(亚马逊、Azure、GCP、OCI)的Hopper出货量。比较Hopper的峰值年份和Blackwell的第一年,您可以看到AI基础设施的惊人增长。
(20:10-22:54) The Transition to AI Factories (向AI工厂的过渡)
We’re now seeing the forecast of data center buildout to reach a trillion dollars. Two dynamics are happening:
我们现在看到数据中心建设的预测将达到一万亿美元。两个动态正在发生:
-
The vast majority of that growth is likely to be accelerated computing. 绝大多数增长可能是加速计算。 -
An increase in recognition that the future of software requires capital investment. The computer has become a generator of tokens, not a retrieval of files. 越来越多的人认识到,软件的未来需要资本投资。计算机已成为Token的生成器,而不是文件的检索器。
I call them AI factories. They have one job: generating tokens.
我称它们为AI工厂。它们有一项工作:生成Token。
(22:54-30:54) CUDA-X Libraries and Accelerated Computing (CUDA-X库与加速计算)
Everything in the data center will be accelerated. This slide is my favorite. This is what GTC is all about: CUDA-X libraries. Acceleration frameworks for each one of these fields of science.
数据中心中的一切都将被加速。这张幻灯片是我的最爱。这就是GTC的全部内容:CUDA-X库。每个科学领域的加速框架。

Examples include: 包括:
-
cuNumeric (for NumPy) cuNumeric (用于NumPy) -
cuLitho (computational lithography) cuLitho (计算光刻) -
Ariel (for 5G) Ariel (用于5G) -
cuOpt (mathematical optimization) cuOpt (数学优化) -
Pair (gene sequencing) Pair (基因测序) -
Moni (medical imaging) Moni (医学成像) -
Earth-2 (multi-physics for weather prediction) Earth-2 (用于天气预报的多物理场) -
cuQuantum and Cuda-Q (quantum computing) cuQuantum和Cuda-Q (量子计算) -
cuDSS (sparse solvers for CAE) cuDSS(用于CAE的稀疏求解器) -
CDF (data frame for structure data, acceleration for Spark and Pandas) CDF(用于结构化数据的数据框,加速Spark和Pandas) -
Warp (Python library for physics) Warp (用于物理的Python库)
Cuda has made it possible, and all of you, the ecosystem, made this possible.
Cuda使之成为可能,而你们所有人,这个生态系统,使之成为可能。
(30:54-32:26) A Thank You to the CUDA Community (感谢CUDA社区)
A short video thanking the creators, pioneers, and builders of the future. 6 million developers in over 200 countries have used CUDA.
一段简短的视频,感谢未来的创造者、先驱者和建设者。超过200个国家/地区的600万开发人员使用了CUDA。
(32:26-35:04) AI’s Reach and the Value of Full Stack (AI的触角与全栈的价值)
I love what we do, I love even more what you do with it. One scientist said, “Because of your work, I can do my life’s work in my lifetime.”
我热爱我们的工作,我更热爱你们用它所做的事情。一位科学家说:“因为你们的工作,我可以在我的有生之年完成我毕生的工作。”
AI will go everywhere. The cloud service providers like our leading-edge technology, the fact that we have a full stack, and the rich developer ecosystem.
AI将无处不在。云服务提供商喜欢我们的尖端技术,我们拥有全栈的事实,以及丰富的开发者生态系统。
(35:04-38:10) AI Going to the Edge and the T-Mobile Partnership (AI走向边缘与T-Mobile的合作)
As AI translates to Enterprise, manufacturing, robotics, self-driving cars, or GPU clouds, there are different system configurations and operating environment differences.
随着AI向企业、制造业、机器人、自动驾驶汽车或GPU云的转化,存在不同的系统配置和操作环境差异。
Today, we announced that Cisco, Nvidia, T-Mobile, the largest telecommunications company in the world, are going to build a full stack for radio networks here in the United States. AI will do a far better job adapting the radio signals.
今天,我们宣布,思科、英伟达、T-Mobile(世界上最大的电信公司)将在这里为美国的无线电网络构建一个全栈。AI将更好地适应无线电信号。
(38:10-40:31) Autonomous Vehicles and the GM Partnership (自动驾驶汽车与通用汽车的合作)
AI is going to go into every industry. One of the earliest industries was autonomous vehicles. We’ve been working on self-driving cars for over a decade.
AI将进入每个行业。最早的行业之一是自动驾驶汽车。我们从事自动驾驶汽车研究已有十多年了。
Today, I’m excited to announce that GM has selected Nvidia to partner with them to build their future self-driving car fleet. AI infrastructure for GM.
今天,我很高兴地宣布,通用汽车已选择英伟达作为合作伙伴,共同打造其未来的自动驾驶汽车车队。为通用汽车提供AI基础设施。
(40:31-42:13) Automotive Safety and Halos (汽车安全与Halos)
One area I’m deeply proud of is safety, Automotive Safety. It’s called Halos. Safety requires technology from silicon to systems to system software, the algorithms, the methodologies.
我深感自豪的一个领域是安全,汽车安全。它被称为Halos。安全需要从芯片到系统再到系统软件、算法、方法论的技术。
(42:13-45:30) Nvidia Omniverse and Cosmos for AV Development (用于自动驾驶开发的Nvidia Omniverse和Cosmos)
A video showcasing Nvidia’s technology for solving the problems of data, training, and diversity in autonomous vehicles.
一段视频展示了英伟达用于解决自动驾驶汽车中数据、训练和多样性问题的技术。

Nvidia is accelerating AI development for AVS with Omniverse and Cosmos. Model distillation, closed-loop training, and synthetic data generation.
英伟达正在通过Omniverse和Cosmos加速自动驾驶汽车的AI开发。模型蒸馏、闭环训练和合成数据生成。
(45:30-46:06) Gaussian Splats and Transition to Data Centers (高斯泼溅与向数据中心的过渡)
Nvidia is the perfect company to do that. Use AI to recreate AI. That’s our destiny.
英伟达是做这件事的完美公司。用AI重现AI。这是我们的命运。
Let’s talk about data centers.
让我们谈谈数据中心。
(46:06-52:09) Blackwell and the Fundamental Transition in Computer Architecture (Blackwell与计算机架构的根本转变)
Blackwell is in full production. This is what it looks like. It’s an incredible sight of beauty.
Blackwell已全面投产。这就是它的样子。这是一个令人难以置信的美丽景象。
We made a fundamental transition in computer architecture. I showed you a version of this 3 years ago, called Grace Hopper. The system was called Ranger. We were trying to solve scale-up.
我们在计算机架构方面做出了根本性的转变。三年前,我向您展示了它的一个版本,名为Grace Hopper。该系统被称为Ranger。我们试图解决向上扩展的问题。
This is the old way (HGX). This is the new way (Blackwell). We disaggregated the MVLink system. This is the MVLink switch, the highest performance switch the world’s ever made.
这是旧的方式(HGX)。这是新的方式(Blackwell)。我们分解了MVLink系统。这是MVLink交换机,这是世界上有史以来性能最高的交换机。
This is completely liquid-cooled. We have a one exaflops computer in one rack.
这是完全液冷的。我们在一个机架中拥有一台exaflops计算机。
(52:09-54:07) The Ultimate Scale-Up (终极扩展)
This is the compute node. 3,000 lbs, 5,000 cables, 2 miles worth. 600,000 parts.
这是计算节点。3,000磅,5,000根电缆,2英里长。600,000个零件。
Our goal is to do scale-up. This is what it now looks like. We essentially wanted to build this chip. It’s just that no reticle limits can do this. The way to solve this problem is to disaggregate it.
我们的目标是向上扩展。这就是它现在的样子。我们基本上想制造这个芯片。只是没有光罩限制可以做到这一点。解决这个问题的方法是分解它。
This is the most extreme scale-up the world has ever done. 576 terabytes per second. Everything is in the trillions. You have an exaflops.
这是世界上有史以来最极端的向上扩展。每秒576 TB。一切都以万亿为单位。你有一个exaflops。
(54:07-55:02) The Extreme Problem of Inference (推理的极端问题)
The extreme problem is called inference. Inference is token generation by a factory. This factory has to be built with extreme efficiency.
极端的问题称为推理。推理是工厂的Token生成。这个工厂必须以极高的效率建造。
(55:02-58:28) Latency vs. Throughput in Token Generation (Token生成中的延迟与吞吐量)
Let me show you how to read this chart. On the x-axis is tokens per second (for one user). On the y-axis is tokens per second (for the whole factory). You want smart AIs that are super fast. You’re trying to get your data center to produce tokens for as many people as possible.
让我告诉你如何阅读这张图表。x轴是每秒Token数(对于一个用户)。y轴是每秒Token数(对于整个工厂)。您需要超级快速的智能AI。您正在努力让您的数据中心为尽可能多的人生成Token。
The perfect answer is to the upper right. The shape of that curve is ideally a square. Your goal is to maximize the area under the curve.
完美的答案是右上角。该曲线的形状理想情况下是一个正方形。您的目标是最大化曲线下的面积。
(58:28-1:00:09) The Need for Flops and Bandwidth (对Flops和带宽的需求)
It turns out that one requires enormous amounts of computation (flops), and the other dimension requires enormous amounts of bandwidth. You should have lots of flops and lots of bandwidth. That’s the best answer.
事实证明,一个需要大量的计算(flops),而另一个维度需要大量的带宽。你应该有很多flops和很多带宽。这是最好的答案。
(1:00:09-1:01:30) Demo: Traditional LLM vs. Reasoning Model (演示:传统LLM与推理模型)
A demo showing a reasoning model (R1) versus a traditional LLM. The traditional LLM makes mistakes, while the reasoning model thinks with over 8,000 tokens to come up with the correct answer.
一个演示展示了一个推理模型(R1)与一个传统的LLM的对比。传统的LLM会犯错误,而推理模型会思考超过8,000个Token来得出正确的答案。
(1:01:30-1:08:06) The Complexity of Model Distribution and Dynamic Operation (模型分布和动态操作的复杂性)
We have to take this model and distribute the workload across the whole system of GPUs. You can use tensor parallel, pipeline parallel, expert parallel. The number of combinations is insane.
我们必须采用这个模型并将工作负载分配给整个GPU系统。您可以使用张量并行、流水线并行、专家并行。组合的数量是惊人的。
One observation is that these reasoning models are doing a couple of phases of computing: prefill (thinking, digesting information) and decode (generating tokens). Depending on the workload, we might decide to put more GPUs in decode or prefill.
一个观察结果是,这些推理模型正在进行几个阶段的计算:预填充(思考、消化信息)和解码(生成Token)。根据工作负载,我们可能会决定在解码或预填充中放置更多GPU。
This dynamic operation is really complicated. The operating system for these AI factories is insanely complicated.
这种动态操作非常复杂。这些AI工厂的操作系统极其复杂。
(1:08:06-1:09:38) Introducing Nvidia Dynamo (介绍Nvidia Dynamo)
Today, we’re announcing the Nvidia Dynamo. It is essentially the operating system of an AI factory. It’s open-source.
今天,我们宣布推出Nvidia Dynamo。它本质上是AI工厂的操作系统。它是开源的。
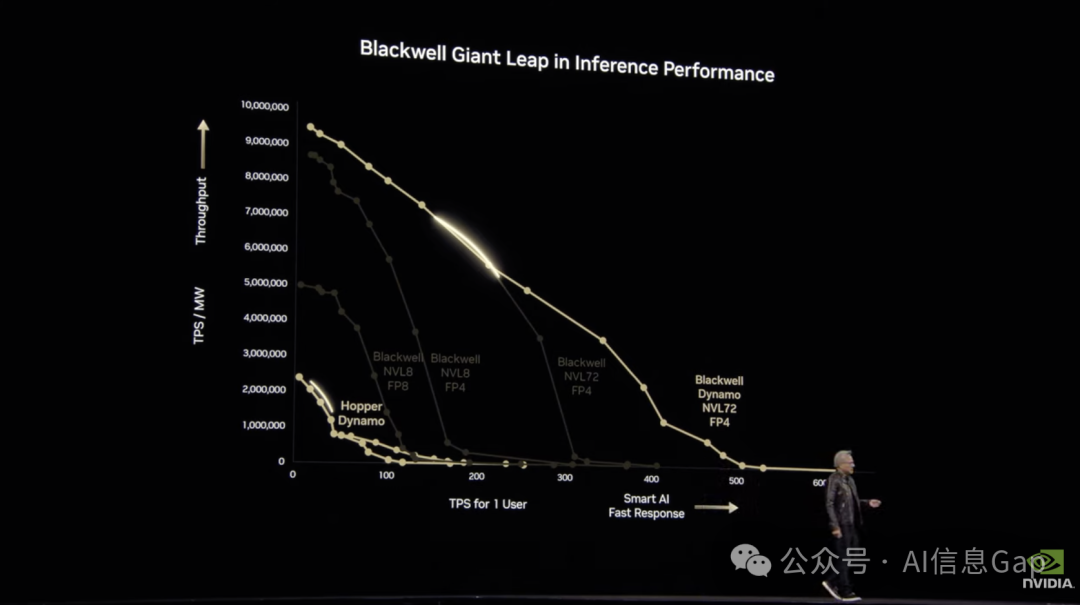
(1:09:38-1:16:23) Blackwell Performance vs. Hopper (Blackwell性能与Hopper的对比)
Now, we’re going to have to wait until we scale up all this infrastructure. But in the meantime, we’ve done a whole bunch of simulation.
现在,我们将不得不等到我们扩展所有这些基础设施。但与此同时,我们已经做了大量的模拟。
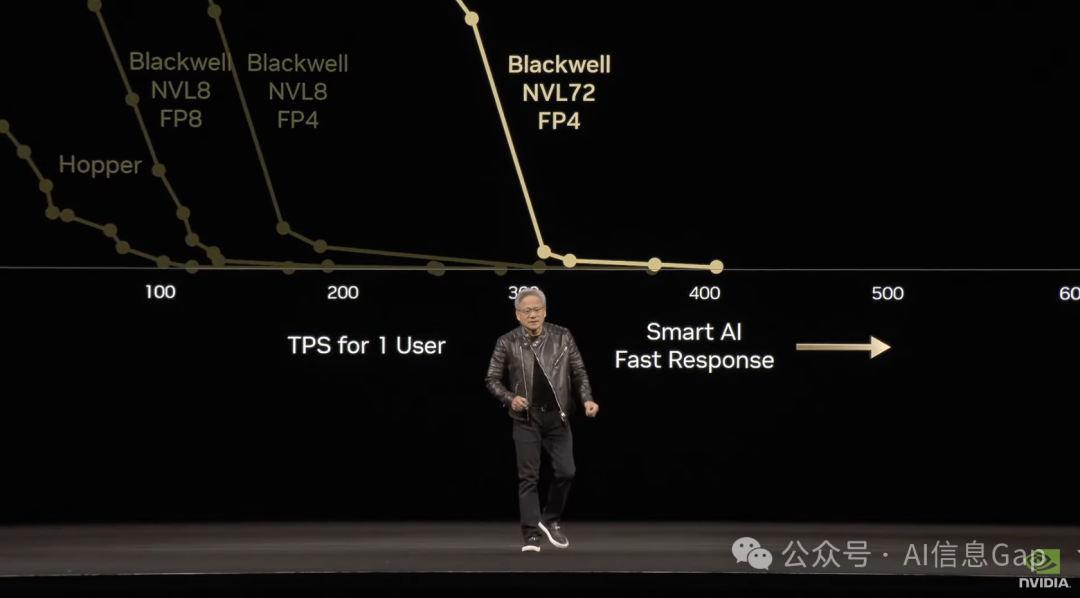
A chart showing the performance of Hopper, Blackwell with MVLink 8, Blackwell with FP4, Blackwell with MVLink 72, and Blackwell with MVLink 72 and Dynamo. Blackwell is 25x in one generation, as ISO power.
一张图表显示了Hopper、带有MVLink 8的Blackwell、带有FP4的Blackwell、带有MVLink 72的Blackwell以及带有MVLink 72和Dynamo的Blackwell的性能。在ISO功率下,Blackwell在一代中达到了25倍。
(1:16:23-1:20:32) The Frontier Pareto and Configuration Flexibility (前沿帕累托和配置灵活性)
The rainbow shows you the different configurations. You want a programmable architecture that is as homogeneously fungible as possible.
彩虹向您展示了不同的配置。您需要一个可编程的架构,该架构尽可能地同质化。
This is with input sequence length 1,000 tokens, output 2,000 tokens. Here’s an example of a reasoning model. Blackwell is 40 times the performance of Hopper.
这是输入序列长度为1,000个Token,输出为2,000个Token的情况。这是一个推理模型的例子。Blackwell的性能是Hopper的40倍。
(1:20:32-1:21:56) 100 Megawatt Factory Comparison (100兆瓦工厂比较)
Just to put it in perspective, this is what a 100-megawatt factory looks like with Hoppers and with Blackwell. The more you buy, the more you make.
为了更清楚地说明这一点,这是一个100兆瓦的工厂在使用Hoppers和Blackwell时的样子。你买得越多,赚得越多。
(1:21:56-1:24:39) AI Factory Digital Twin (AI工厂数字孪生)
AI factories are so complicated. We are starting to build what we call the digital twin of every data center.
AI工厂非常复杂。我们开始构建我们称之为每个数据中心的数字孪生。
A video showcasing the Nvidia Omniverse blueprint for AI factory digital twins.
一段视频展示了用于AI工厂数字孪生的Nvidia Omniverse蓝图。

(1:24:39-1:31:02) Nvidia’s Roadmap: Blackwell Ultra, Vera Rubin, Rubin Ultra (英伟达的路线图:Blackwell Ultra、Vera Rubin、Rubin Ultra)
Our roadmap: Blackwell is in full production. In the second half of this year, we will transition into the upgrade, Blackwell Ultra.
我们的路线图:Blackwell已全面投产。今年下半年,我们将过渡到升级版Blackwell Ultra。
One year out is named after Vera Rubin. The CPU is new, twice the performance of Grace. Reuben: brand new GPU, CX9, brand new networking smart NIC, MVLink 6, brand new MVLink, brand new memories (HBM4).
一年后以Vera Rubin命名。CPU是新的,性能是Grace的两倍。Reuben:全新的GPU、CX9、全新的网络智能NIC、MVLink 6、全新的MVLink、全新的内存(HBM4)。
Second half of the following year: Reuben Ultra. MVLink 576, extreme scale-up. Each rack is 600 KW. 14 times more flops, 15 exaflops. 4,600 terabytes per second scale-up bandwidth.
第二年下半年:Reuben Ultra。MVLink 576,极度向上扩展。每个机架600 KW。14倍以上的flops,15 exaflops。每秒4,600 TB的向上扩展带宽。
This is what Grace Blackwell looks like, and this is what Reuben looks like, ISO dimension.
这是Grace Blackwell的样子,这是Reuben的样子,ISO尺寸。

(1:31:02-1:34:46) Scaling Out with Infiniband and Spectrum X (使用Infiniband和Spectrum X向外扩展)
Once a year, an architecture. Every two years, a new product line. Every single year, X factors up.
每年一个架构。每两年一个新产品线。每一年,X因子都会增加。
We introduced Spectrum X. We brought to it the properties of congestion control and very low latency. Spectrum X is not just for AI clouds, but also for Enterprise.
我们推出了Spectrum X。我们为它带来了拥塞控制和极低延迟的特性。Spectrum X不仅适用于AI云,也适用于企业。
(1:34:46-1:42:06) Silicon Photonics and Co-Packaged Optics (硅光子学和共封装光学)
We’re going to need something long-distance running. This is where silicon photonics comes in.
我们需要一些长距离运行的东西。这就是硅光子学的用武之地。
We’re announcing Nvidia’s first co-packaged option silicon photonic system. It is the world’s first 1.6 terabit per second CPO. It is based on a technology called micro-ring resonator modulator (MRM).
我们宣布推出英伟达首个共封装选项硅光子系统。这是世界上第一个每秒1.6 TB的CPO。它基于一种称为微环谐振器调制器(MRM)的技术。
A video showcasing the MRM technology.
一段视频展示了MRM技术。
(1:42:06-1:44:25) Roadmap Summary and Fineman (路线图总结和Fineman)
Our Infiniband switch, the silicon is working fantastically. Second half of this year, we will ship the silicon photonic switch. Second half of next year, we will ship Spectrum X.
我们的Infiniband交换机,硅芯片工作非常出色。今年下半年,我们将出货硅光子交换机。明年下半年,我们将出货Spectrum X。
Our next generation will be named after Fineman.
我们的下一代将以Fineman命名。
(1:44:25-1:52:39) Enterprise Computing and New DGX Systems (企业计算和新的DGX系统)
In order for us to bring AI to the world’s Enterprise, we need a new line of computers.
为了将AI带给全球的企业,我们需要一条新的计算机产品线。
This is the original DGX1. Let me introduce you to the new DGX, DGX Spark. 20 CPU cores, 128 GB of GPU memory, one petaflops.
这是最初的DGX1。让我向您介绍新的DGX,DGX Spark。20个CPU核心,128 GB的GPU内存,1 petaflops。
This is the development platform of every software engineer in the world.
这是世界上每个软件工程师的开发平台。
We’re also announcing a new personal workstation, DGX Station. 20 petaflops, 72 CPU cores, chip-to-chip interface, HBM memory, and PCI Express slots.
我们还宣布推出一款新的个人工作站DGX Station。20 petaflops,72个CPU核心,芯片到芯片接口,HBM内存和PCI Express插槽。
We will also revolutionize the rest of the computing stack. The storage system has to be continuously embedding information.
我们还将彻底改变计算堆栈的其余部分。存储系统必须不断嵌入信息。
(1:52:39-1:55:27) Partnerships with Dell, Accenture, AMD, and Others (与戴尔、埃森哲、AMD等的合作)
Michael’s slide showcasing Dell’s offering of Nvidia Enterprise AI infrastructure.
迈克尔的幻灯片展示了戴尔提供的英伟达企业AI基础设施。
We’re announcing this incredible model that everybody can run, R1. It’s now completely open-source. It’s part of our system, we call NIMS.
我们宣布推出这个令人难以置信的模型,每个人都可以运行,R1。它现在是完全开源的。它是我们系统的一部分,我们称之为NIMS。
Partnerships with Accenture, AMD, AT&T, BlackRock, Cadence, Capital One, Deloitte, NASDAQ, SAP, Service Now.
与埃森哲、AMD、AT&T、贝莱德、Cadence、Capital One、德勤、纳斯达克、SAP、Service Now的合作。
(1:55:27-2:01:07) Robotics and Physical AI (机器人与物理AI)
Let’s talk about robots. The time has come for robots. Robots have the benefit of being able to interact with the physical world.
让我们谈谈机器人。机器人的时代已经到来。机器人具有能够与物理世界互动的优势。
A video showcasing Nvidia’s three computers for robot AI: simulation, training, testing, and real-world experience.
一段视频展示了英伟达用于机器人AI的三台计算机:模拟、训练、测试和真实世界体验。
(2:01:07-2:04:32) Omniverse, Cosmos, and Newton (Omniverse、Cosmos和Newton)
Physical AI and Robotics are moving so fast. At its core, we have the same challenges:
物理AI和机器人技术发展如此之快。在其核心,我们面临着同样的挑战:
-
How do you solve the data problem? 如何解决数据问题? -
What’s the model architecture? 模型架构是什么? -
What’s the scaling loss? 缩放损失是什么?
We created a system called Omniverse. We added two technologies to it: Cosmos and Newton.
我们创建了一个名为Omniverse的系统。我们向其中添加了两项技术:Cosmos和Newton。
Cosmos: a generative model that understands the physical world.
Cosmos:一个理解物理世界的生成模型。
Newton: a physics engine designed for fine-grain rigid and soft bodies, tactile feedback, and actuator controls. A partnership of DeepMind, Disney Research, and Nvidia.
Newton:一个物理引擎,专为细粒度的刚体和软体、触觉反馈和执行器控制而设计。DeepMind、迪士尼研究和英伟达的合作。
(2:04:32-2:07:07) Demo with Blue and Introduction of Groot N1 (与Blue的演示和Groot N1的介绍)
A demo with a robot named Blue, showcasing the Newton physics engine.
与一个名为Blue的机器人的演示,展示了Newton物理引擎。
Today, we’re announcing that Groot N1 is open-sourced.
今天,我们宣布Groot N1是开源的。
(2:07:07-2:11:38) Wrap-up and Thank You (总结与感谢)
Let’s wrap up. I want to thank all of you for coming to GTC. We talked about several things:
让我们总结一下。我要感谢大家来到GTC。我们谈到了几件事:
-
Blackwell is in full production. Customer demand is incredible. Blackwell已全面投产。客户需求令人难以置信。 -
Blackwell MVLink 72 with Dynamo is 40 times the performance of Hopper. 带有Dynamo的Blackwell MVLink 72的性能是Hopper的40倍。 -
We have an annual rhythm of roadmaps. 我们有一个年度路线图节奏。 -
We have three AI infrastructures: cloud, Enterprise, and robots. 我们有三个AI基础设施:云、企业和机器人。
We have one more treat for you.
我们还有一份礼物送给您。
A final video showcasing various applications of Nvidia technology.
最后一段视频展示了英伟达技术的各种应用。
Thank you, everybody. Thank you for all the partners that made this video possible. Have a great GTC.
谢谢大家。感谢所有使这段视频成为可能的合作伙伴。祝大家在GTC过得愉快。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)