


极市导读
Meta提出了EdgeTAM,这是一个基于SAM 2的高效视频分割模型。EdgeTAM通过引入2D空间感知器和知识蒸馏流水线,显著降低了计算成本,同时保持了与SAM 2相当的性能,能够在iPhone 15 Pro Max上以16 FPS运行,速度比SAM 2快22倍。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

在 Segment Anything 模型 (SAM) 之上,SAM 2 通过记忆bank 机制进一步扩展了其从图像到视频输入的能力,并获得了与以往方法相比的卓越性能,使其成为视频分割任务的基础模型。在本文中,我们旨在使 SAM 2 更加高效,甚至可以在移动设备上运行,同时保持可比的性能。尽管有许多工作优化了 SAM 以获得更好的效率,但我们发现它们对 SAM 2 来说是不够的,因为它们都集中于压缩图像编码器,而我们的基准测试表明,新引入的记忆注意力块也是延迟瓶颈。
基于这一观察,我们提出 EdgeTAM,它利用一种创新的 2D 空间感知器来降低计算成本。具体来说,所提出的 2D 空间感知器使用一种轻量级 Transformer 来编码密集存储的帧级别记忆,该 Transformer 包含一组可学习的查询。鉴于视频分割是一个密集预测任务,我们发现保持记忆的空间结构对于将查询分成全局级别和片级别组至关重要。我们还提出了一种蒸馏流水线,进一步提高了性能,而无需推理开销。结果,EdgeTAM 在 DAVIS 2017、MOSE、SA-V val 和 SA-V test 上分别实现了 87.7、70.0、72.3 和 71.7 J &F,同时在 iPhone 15 Pro Max 上以 16 FPS 运行。
1. 引言
Segment Anything Model (SAM) [31] 是第一个可提示图像分割的基础模型。各种研究表明它在零样本泛化和迁移学习方面具有卓越的能力 [8, 39, 55, 70]。在 SAM 之上,最近,SAM 2 [48] 扩展了原始 SAM,以处理图像和视频输入,并具有记忆银行机制,并使用新的大规模多粒度视频跟踪数据集 (SA-V) 进行训练。
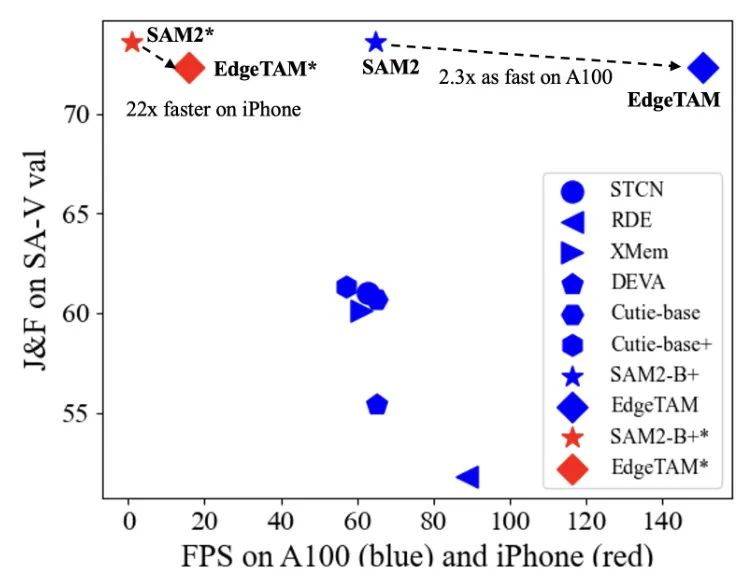
尽管 SAM 2 在与以前的视频对象分割 (VOS) 模型相比取得了惊人的性能,并允许更广泛的用户提示,但作为服务器端的基础模型,它对设备端推理效率不高。例如,最小的 SAM 2 变体在 iPhone 15 Pro Max 1 上仅运行速度约为 1 FPS。此外,现有的方法 [71, 83, 86],这些方法优化了 SAM 以获得更好的效率,仅考虑了其图像编码器,因为掩码解码器非常轻量级。然而,如图 2 所示,这对于 SAM 2 来说是不够的,即使将图像编码器替换为更紧凑的视觉支架,例如 ViT-Tiny [58] 和 RepViT [64],由于 SAM 2 中引入的计算量大的内存注意力块,延迟并没有得到显著改善。
尤其是,SAM 2 使用内存编码器对过去帧进行编码,这些帧级别内存与对象级别指针(从掩码解码器获得)一起构成内存银行。然后,这些与当前帧的特征通过内存注意力块融合。由于这些内存被密集编码,因此在当前帧特征和内存特征之间进行跨注意力时,会产生巨大的矩阵乘法。因此,尽管内存注意力块的参数数量相对较少,但内存注意力的计算复杂度对于设备端推理来说是不可承受的。Fig. 2 进一步证明了这一假设,其中减少内存注意力块的数量几乎线性地降低了总解码延迟,并且在每个内存注意力块中,删除跨注意力提供了最大的速度提升。

为了使这种基于视频的跟踪模型在设备上运行,在EdgeTAM中,我们关注如何利用视频中的冗余信息。为了在实践中实现这一点,我们提出在执行记忆注意力之前压缩原始帧级别的信息。我们首先使用朴素的空间池化,并观察到性能显著下降,尤其是在使用低容量的骨干网络时。 为了缓解这个问题,我们转向基于学习的压缩器,如Perceiver [29, 30],它使用一组小固定的学习查询来总结密集特征图。然而,即使是朴素地将Perceiver纳入其中,也导致性能严重下降。我们假设,作为一种密集预测任务,视频分割需要保留记忆银行的空间结构,而朴素的Perceiver则会丢弃这种结构。
鉴于这些观察结果,我们提出了一种创新的轻量级模块,该模块压缩了帧级别的内存特征图,同时保留了二维空间结构,名为 2D Spatial Perceiver。具体来说,我们将可学习的查询分为两组,其中一组的功能类似于原始 Perceiver,即每个查询都对输入特征执行全局注意力并输出一个向量作为帧级别的总结。在另一组中,查询具有二维先验,即每个查询仅负责压缩一个非重叠的局部区域,因此输出同时保持空间结构并减少总的 token 数量。作为插件模块,2D Spatial Perceiver 可以与 SAM 2 的任何变体集成,并且通过 8 倍的速度加快内存注意力,同时具有可比的性能。例如,使用 RepViT-M1 [64] 作为骨干网络和两个内存注意力块时,利用 2D Spatial Perceiver 在 iPhone 上可以获得 16 FPS,这比基线快 6.4 倍,并且在具有挑战性的 SA-V val 集中甚至超过它,达到 0.9 I&F。
除了架构改进之外,我们还进一步提出了一种蒸馏流水线,将强大的教师模型 SAM 2 的知识转移到我们的学生模型中,从而在不增加推理开销的情况下提高准确率。具体而言,SAM 2 的训练过程分为两个阶段,首先,模型使用 SA-1B [31] 中的可提示图像分割任务进行训练,同时断开与内存相关的模块,然后在第二阶段,模型包含所有模块,使用可提示视频分割任务在 SA-1B 和 SA-V [48] 数据集上进行训练。我们发现,在两个阶段,从原始 SAM 2 的图像编码器中对齐特征有益于性能。此外,我们还对教师 SAM 2 和我们的学生模型之间的内存注意力输出进行对齐,以便除了图像编码器之外,与内存相关的模块也可以从 SAM 2 教师那里接收监督信号。结果,通过提出的蒸馏流水线,我们在 SA-V val 和测试集上分别将提高了 1.3 和 3.3。
汇聚起来,我们提出了一种名为 EdgeTAM(边缘设备上的 Track Anything 模型),它采用 2D 空间感知器以提高效率,并采用知识蒸馏以提高准确性。我们的贡献可以总结如下:
• 通过全面的基准测试,我们发现延迟瓶颈在于内存注意力模块。• 鉴于延迟分析,我们提出了一种2D空间感知器,它显著降低了内存注意力计算成本,同时具有可与任何SAM 2变体相媲美的性能,可以与任何SAM 2变体集成。
• 我们实验了一个蒸馏流水线,该流水线在图像和视频分割阶段都与原始 SAM 2 进行特征级对齐,观察到在推断期间没有额外成本的情况下,性能有所提高。
• The resulting EdgeTAM 可以以 16 FPS 在 iPhone 上运行,这明显比现有的视频对象分割模型更快,并且与之前的最先进方法相当或优于。我们的知识表明,它是第一个在设备上运行的,用于统一分割和跟踪任务的模型。
2. 相关工作
**视频对象分割 (VOS)**。VOS 任务的目标是,给定第一帧的地面真实 (GT) 对象分割掩码,在视频后续帧中跟踪和预测对象掩码。在线学习方法 [4, 7, 26, 38, 40, 41, 45, 46, 49, 52, 61, 69] 将该任务表述为一个半监督学习问题,在测试期间,模型会使用第一帧的 GT 掩码进行微调。然而,这项工作通常会遭受推理效率低、对输入敏感以及难以随着大量训练数据进行扩展的问题。为了避免测试期间的训练,离线训练的模型提出利用模板匹配 [10, 27, 43, 62, 74, 75, 77, 79] 或记忆银行 [34, 44] 来跟踪标注和预测帧中的身份信息。在网络架构方面,一些工作采用循环神经网络进行空间-时间编码 [32, 33, 60, 72],而最近,基于 Transformer 的模型 [3, 11, 12, 14, 19, 32, 51, 66, 68, 76, 78, 80, 84] 表现更好。
Segment Anything Model (SAM)。SAM [31] 定义了一个新的基于提示的分割任务,其中用户提示可以是点、框和掩码。SAM 2 [48] 将任务扩展到视频输入,即提示式视频分割 (PVS)。与 VOS 不同,用户可以在任意帧和多个时间步长提供标注,并使用 SAM 提示的任何组合,使 VOS 成为 PVS 的一个特殊情况。SAM 和 SAM 2 都遵循相同的元架构,即图像编码器和基于提示的掩码解码器,但为了捕捉时间信息,SAM 2 补充了一个记忆银行机制。得益于在各种大型数据集上的训练,SA-1B [31] 和 SAV [48],SAM 在通用感知和下游任务方面表现出色 [8, 9, 39, 55, 70, 81]。为了使 SAM 更加高效且更适合低容量设备,一些工作 [63, 71, 83, 85, 86] 建议将其图像编码器压缩为更紧凑的视觉支架,并采用知识蒸馏和/或掩码图像预训练。然而,通过我们的基准测试,我们发现,除了图像编码器之外,SAM 2 中新引入的与记忆相关的模块也是速度瓶颈;因此,替换图像编码器已经不再足够。因此,我们提出了一种新的插件模块来加速记忆融合以解决该问题,并结合了为视频输入而设计的蒸馏管道。
3. 方法论
在这一部分,我们首先简要介绍 Segment Anything 模型 2 (SAM 2),我们的模型基于它。然后,我们分别提出我们的架构级改进和知识蒸馏流程。
3.1. 预备:SAM 2
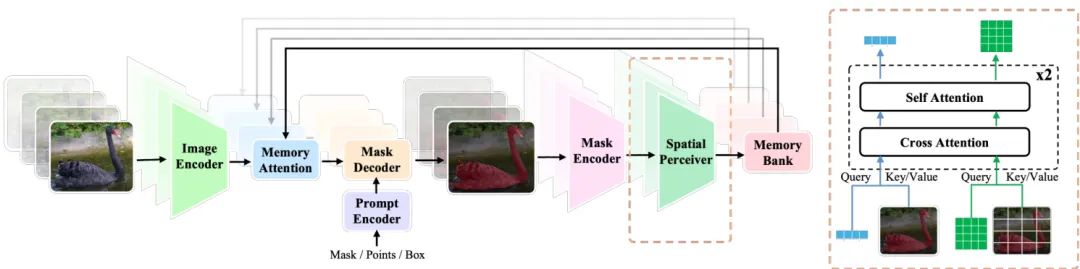
总体而言,SAM 2 由四个组件组成,包括图像编码器 ,掩码解码器 ,内存编码器 和内存注意力 ,前两者几乎与原始 SAM 相同,仅区别在于两者之间的跳跃连接。尤其是, 是一种分层骨干网络 Hiera[50],它输出具有三个不同步距的特征图,分别为 和 16 ,分别表示为 。
其中, 是当前的帧输入。然后, 与来自前 帧的记忆特征 融合,通过记忆注意力 进行融合。记忆注意力本质上是 Transformer[59]块的堆叠。在这种设置中, 作为查询,而记忆特征,沿着时间维度连接,提供键和值:
其中, 是基于记忆的图像特征。接下来,掩码解码器 编码用户提示,并根据提示嵌入 和图像特征 解码掩码预测 :
最后, 和 被融合并使用内存编码器 编码,然后以先进先出(FIFO)的方式排入内存银行:
3.2. EdgeTAM
Na¨ıve Adaptations. 如图 3 所示,SAM 2 的元架构紧随 SAM 之后,其图像编码器是参数和计算方面最重的组件。虽然新引入的与内存相关的模块只占总参数的一小部分,但我们的基准测试 (图 2) 表明,内存注意力也是一个延迟瓶颈。因此,为了追求更高的效率,一种朴素的技术是使用紧凑的骨干网络替换图像编码器,并减少内存注意力块的数量。为此,我们遵循 EdgeSAM [86] 的做法,选择 RepViT-M1 [64] 作为骨干网络,并将内存注意力从 4 个块减少到 2 个块。然而,在移动设备上部署时,推理吞吐量仍然令人满意,仅为 2.5 FPS (在 iPhone 15 Pro Max 上)。
Taking a closer look, we observe that each memory feature has the same size as the image feature , where denote channels, height and width respectively. With frames in the memory bank, the computational complexity of memory attention becomes , which translates to a huge matrix multiplication that mobile devices with limited scale of parallelism perform inefficiently. While is already relatively small compared to other VOS methods, reducing it will lead to the degradation of temporal consistency and occlusion handling. On the other hand, videos are known to be information redundant. Thus, we propose to summarize the memory spatially before performing memory attention. Global Perceiver. Inspired by Perceiver [29, 30], we encode each memory feature with a stack of attention modules to compress the densely stored memories into a small set of vectors , where is the number of learnable latents and Specifically, we denote the latents as and perform single-head cross attention (CA) between and , followed by self attention (SA) as follows:
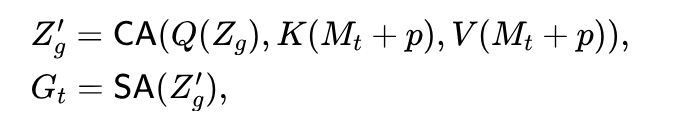
和 分别表示 CA 中查询,键和值的投影。 是中间特征, 表示位置嵌入[53]。在这里,每个潜在的表示可以全局地关注记忆特征并将其总结为一个向量。虽然全局感知器引入了可忽略的推理成本,但它将记忆注意力的复杂度降低到 。然而,尽管在全局感知器的输入中添加了位置嵌入,但生成的压缩记忆仅包含隐式的空间信息,因为输出没有保持其空间结构。同时,作为密集预测任务,视频对象分割需要更明确的位置信息[48]和局部特征[51]。因此,我们进一步提出了一种 2D 空间感知器用于此目的。
2D 空间感知器。与全局感知器类似,2D 空间感知器共享相同的网络架构和参数。然而,我们为可学习的潜在变量 分配了空间先验,并限制每个潜在变量仅关注局部窗口。具体而言,我们执行窗口分割[36]将记忆特征图分割为 个非重叠的块,并将位置嵌入 从输入移动到输出 :

不同的 Global 和 2D 空间感知器设计鼓励不同的行为,其中全局潜在变量 具有一定的冗余性(多个潜在变量关注相同的输入)并且可以动态分布在整个图像上,而 2D 潜在变量 则被迫处理局部区域。两者都具有总结特征的良好优点。因此,我们通过沿空间维度进行展平并沿展平维度进行连接来组合它们。请注意,我们的实现堆叠了 Eq. 5 和 Eq. 6 中的块两次。总而言之,在应用所提出的模块时,内存注意力复杂性从 减少到 。在实践中,我们控制速度提升比例约为 倍,即 ,以便内存注意力中的自注意力块和交叉注意力块具有相似的复杂度。
3.3. 蒸馏流水线
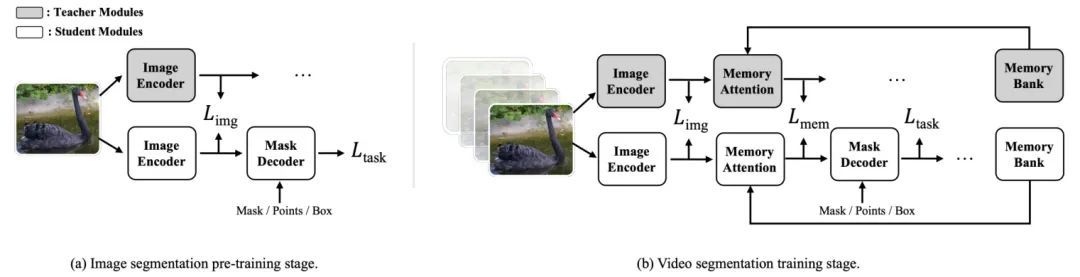
如图 4 所示,SAM 2 的训练流程可以分为图像分割预训练阶段 和视频分割训练阶段 。先前的方法[71,83,86]表明,在 上进行知识蒸馏有助于提高图像的性能。在此,我们将这一思想扩展到视频领域,并将蒸馏损失作为辅助损失,这意味着在训练过程中也同时实施了任务特定的损失。
特别是, 中,我们采用与任务相关的损失函数 ,与 SAM 相同(包括用于掩码预测的 Dice loss [54]和 focal loss[35]以及用于掩码置信度预测的 L1 loss),同时,我们使用 MSE loss 将图像编码器特征图( 在 Eq. 1 中)在教师模型和学生模型之间对齐。预训练损失 可以表示为:
其中, 是从方程 1 和方程 3 获得的掩码预测。由于缺乏内存银行,因此省略方程 。这里, 和 分别表示真实标签,损失权重,教师和学生图像编码器特征。
最后,在第 阶段,任务特定的损失包括一个额外的 BCE 损失用于遮挡预测。此外,为了让学生的记忆相关模块从教师那里获得监督,除了 ,我们添加了另一个 MSE 损失 来对齐教师和学生( 和 )(Eq.2)。最终的总损失变为:
使用 和 作为损失权重。
4.实验证明
4.1. 实施细节
训练。一般来说,EdgeTAM的训练过程遵循SAM 2。我们将输入分辨率设置为 。在图像分割预训练阶段,我们使用SA-1B数据集进行训练,共 2 个epoch,批大小为 128 。我们使用AdamW[37]作为优化器 ,并将学习率设置为 ,并使用倒数平方根调度器[82]。我们对 梯度进行截断,值为 0.1 ,并将权重衰减设置为 0.1 。骰子,焦点, 和 的损失权重分别为 和 1 。对于每个训练样本,最多允许 64 个对象,并迭代地添加 7 个修正点。在这一阶段,仅进行水平随机翻转的数据增强。对于视频分割训练,我们使用SA-V,即SA-1B的 随机抽样子集,包括DAVIS,MOSE和 YTVOS,进行训练 130 K次迭代,批大小为 256 。大多数配置遵循前一阶段,除了图像编码器学习率等于 ,其他部分学习率等于 ,并使用余弦调度器。骰子的损失平衡因子为 20 和 1 ,焦点,IoU,遮挡, 和 的平衡因子分别为 和 1 。每个视频样本包含 8 帧,几乎有 3 个对象,并使用水平翻转,颜色抖动,仿射和灰度变换进行增强。
渐进式微调,使用更长的训练样本。类似于 SAM 2.1,我们对训练好的 EdgeTAM 模型进行微调,使用 16 帧序列。在微调过程中,我们冻结图像编码器,不进行蒸馏。训练集与视频分割训练阶段相同,但总迭代次数减少到原始计划的 1/3。此外,由于 EdgeTAM 的 VRAM 消耗量远低于 SAM 2,我们能够使用 32 帧的训练样本,按照相同的计划对 16 帧模型进行进一步微调。请注意,内存银行大小保持不变,只有训练样本变长,因此推理成本不变。
Model. 默认情况下,我们使用在 ImageNet 上预训练的 RepViT-M1 [64] 作为图像编码器。我们还尝试使用在 ImageNet 上预训练的 ViT-Tiny [58],并使用 MAE [24]。内存注意力块的数量为 2,并且为全局感知器和 2D 空间感知器分配了 256 个可学习的潜在空间。帧级别记忆和对象指针的内存银行大小分别为 7 和 16,遵循 SAM 2。全局感知器和 2D 空间感知器的位置嵌入是正弦,分别是 2DRoPE [53]。我们使用 SAM2-HieraB 作为教师,并使用公开可用的 checkpoint3。
4.2. 数据集
训练。我们使用 SA-1B[31],SA-V[48],DAVIS[47],MOSE[18]和 YTVOS[73]数据集进行训练。SA- 1B 包含 1100 万张图像,带有 110 亿个 mask 标注,具有多种粒度(在部分级别和对象级别)。SA-1B中图像的平均分辨率为 像素。到目前为止,它是可用的最大的数据集,用于图像分割任务。SA-V 遵循 SA-1B 的标准,并收集了 190.9 万个 masklet 标注,涵盖 50.9 万个视频,平均时长为 14秒,室内/室外场景比例为 ,并重采样到 24 FPS。请注意,标注帧率是 6 FPS。此外,从 155个视频中的 293 个 masklet 和从 150 个视频中的 278 个 masklet 作为 SA-V 的 val/test 分割集保留,这些视频是手动选择的,以关注具有快速运动,复杂遮挡和消失的困难情况。
评估。 我们的评估可以分为三个设置:(1)提示式视频分割(PVS),用户可以点击视频中的任意帧以指示感兴趣的对象;(2)任何分割(SA),与 PVS 相同但适用于图像;(3)半监督视频对象分割(VOS),在推理过程中,第一帧上的真实掩码可用。对于视频任务,我们报告 [47]和 [73]作为指标,对于图像,我们使用 mloU。
评估。我们的评估可以分为三个设置:(1) 提示式视频分割 (PVS),用户可以点击视频中的任意帧以指示感兴趣的对象;(2) 任何分割 (SA),与 PVS 相同但适用于图像;(3) 半监督视频对象分割 (VOS),在推理过程中,第一帧上的真实掩码可用。对于视频任务,我们报告 [47] 和 [73] 作为指标,对于图像,我们使用 mIoU。
对于PVS,我们使用零样本协议在9个数据集(包括在线和离线模式)中进行评估。对于SA,我们在SA-23 [31] 上进行评估,该数据集由23个开源数据集(包括视频(每个帧被视为图像)和图像领域)组成。最后,对于VOS,我们提供了在流行的DAVIS 2017 [47]、MOSE [18] 和 YouTubeVOS [73] val集以及具有挑战性的SA-V val/test集 [48]上的性能。
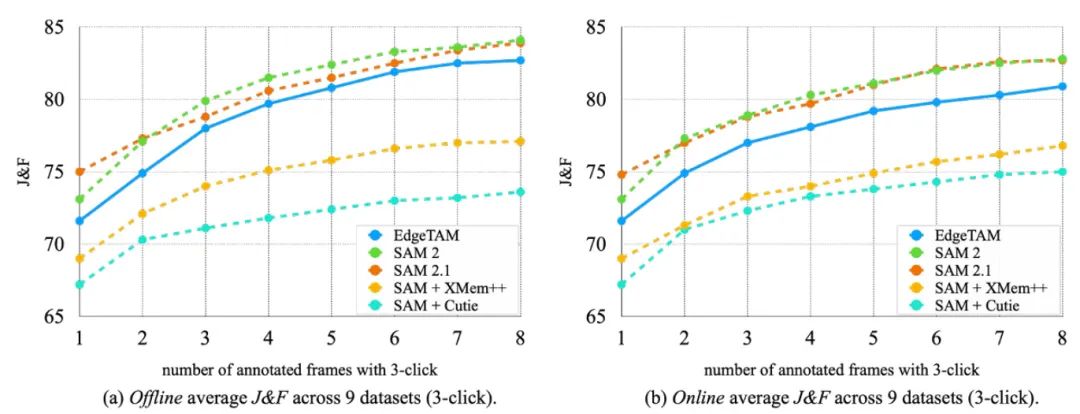
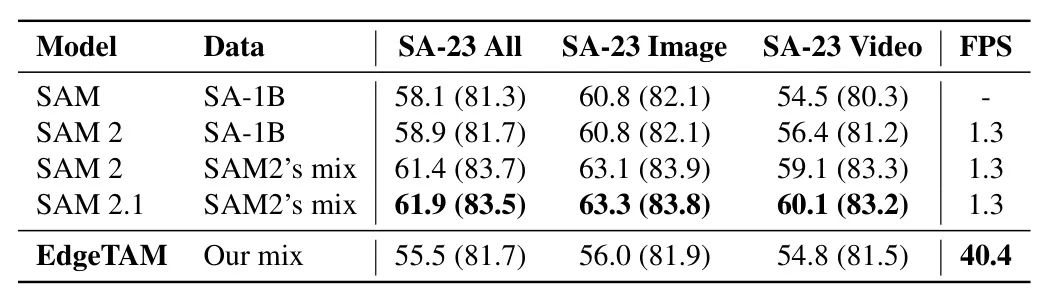
4.3. 提示式视频分割 (PVS)
EdgeTAM 的一个关键特性是它遵循 SAM 2 的相同元架构,这使得它能够使用各种用户输入在任何帧上进行可提示的视频分割。如图 5 所示,我们遵循了与 SAM 2 相同的在线和离线 PVS 设置,这模拟了真实世界中的用户交互。离线模式允许多次回放,仅在出现较大错误的帧上添加修正点,而在线模式仅在单次前向传递中注释帧。与 和 Cuite 相比,EdgeTAM 在所有设置下均有显著优势。此外,由于以端到端方式进行训练并使用 SAM 2 教师进行蒸馏,因此随着标注帧数量的增加,差距越来越大。此外,即使与原始 SAM 2 相比,EdgeTAM 也能实现可比结果,尽管它在尺寸和速度方面明显更小更快。
4.4. Segment Anything (SA)
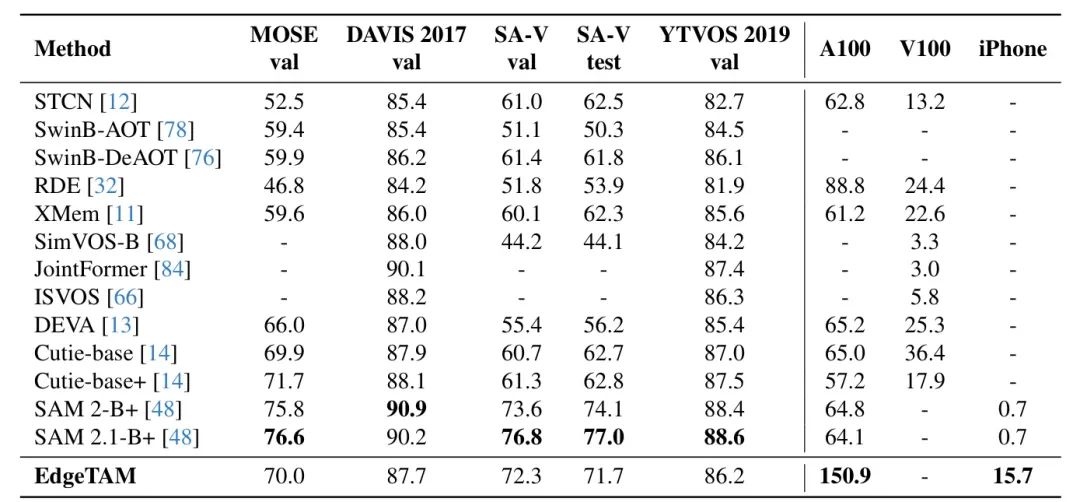
Both SAM 2 和 EdgeTAM 可以作为具有分离内存模块的图像分割模型运行。如图 1 所示,EdgeTAM 在与 SAM 和 SAM 2 相比,尤其是在具有更多输入点的情况下,可以实现可比的 mIoU 性能。例如,在五个输入点的情况下,EdgeTAM 甚至超过了专门用于图像分割的 SAM-H (81.7 v.s. 81.3)。请注意,我们的 EdgeTAM 没有使用 SAM 2 和 SAM 2.1 使用的内部数据集进行训练。鉴于其实时速度,EdgeTAM 可作为图像和视频的统一本地分割模型使用。

4.5. 视频对象分割 (VOS)
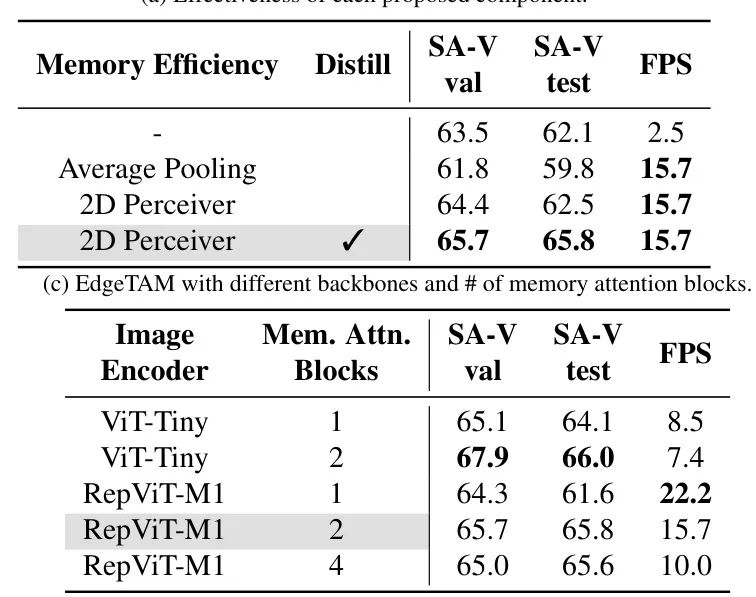
While EdgeTAM 仅使用 SA-V 和 SA1B 数据集进行训练,如表 2 所示,在 MOSE、DAVIS 和 YTVOS 上,它与或超过了在这些数据集上训练的以往最先进的 VOS 模型。这表明 EdgeTAM 在零样本设置下的鲁棒性。更重要的是,在设备上部署多个模型,每个模型针对某些类型的数据,在实践中不可行。
此外,由于在 SA-V 上进行训练,EdgeTAM 在 SA-V val 和 test 上超越了所有其同类产品,仅次于 SAM 2 和 SAM 2.1。请注意,SA-V val/test 中的掩码具有不同的粒度,而其他数据集的掩码则在对象级别。这表明 EdgeTAM 的灵活性。此外,为了速度基准测试,我们的主要目标是在边缘设备上进行推理,我们观察到,即使使用 torch 编译,EdgeTAM 的流式多处理器利用率仍然相对较低。通过 Torch profile,我们发现,在高端 GPU 上,CPU(CUDA 内核启动)成为 EdgeTAM 的瓶颈。因此,我们鼓励关注边缘设备延迟,而 EdgeTAM 旨在为此服务。
4.6. 试验结果分析
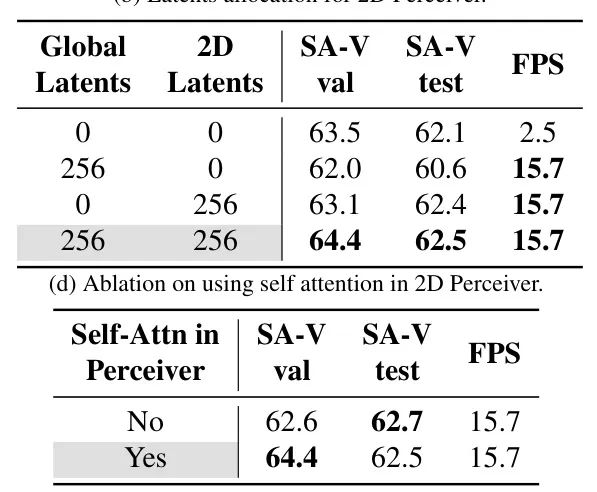
对于所有消融研究,我们使用原始训练计划的 (43k 步)进行训练。如图 3(a)所示,我们首先消融了每个拟议组件的有效性。在表中,我们将基线设置为具有两个记忆注意力块的 RepViTM1,并将其与仅使用降采样空间记忆而不是使用 2D Perceiver 进行比较。实验表明,2D Spatial Perceiver 比基线和 平均池化更快速,更准确(0.4 到 2.7 个更好)。此外,拟议的蒸馏流水线通过 1.3 和 3.3 进一步改善了 SA-V val 和测试集上的 。然后,在图 3(b)中,我们改变了全局和 2D 潜在变量的数量,并发现使用两者可以获得最佳性能和加速。请注意,使用 2D 潜在变量以 6.3 倍的速度加速了基线,同时具有更好的性能。图3(c)显示了在不同图像编码器组合和记忆注意力块的数量中使用 2D Perceiver。我们选择使用两个记忆注意力块的 RepViT-M1 以获得最佳权衡。最后,在图 3(d)中,我们研究了在 2D Perceiver 网络中使用自注意力的方法。这里的动机是,由于每个 2D 潜在变量都关注一个没有与其他 2D 潜在变量重叠的局部区域,因此引入自注意力块将鼓励 2D 潜在变量之间的通信,从而产生更好的特征。我们的结果验证了这一假设。
4.7. 质性结果
在图 6 中,我们比较了 EdgeTAM 和 SAM 2 在 YouTubeVOS val 数据集上的可视化结果。我们选取了两个具有代表性的例子,一个包含来自同一类别的多个实例聚集在一起,另一个包含快速移动的物体和大量失真。对于第一个例子,EdgeTAM 的结果与 SAM 2 相似,并且在整个片段中保持了每个实例的身份。然而,在第二个例子中,我们观察到 EdgeTAM 陷入了一个典型的失败案例,即跟踪粒度可能始终跟随 SAM 2。在该例子中,EdgeTAM 没有将鸟的脚包含在预测的掩码中,因为在之前的帧中,脚不可见。
5. 结论
在本文中,我们发现 SAM 2 的延迟瓶颈在于内存注意力模块,并提出 EdgeTAM 以减少跨注意力带来的高开销,同时最大限度地减少性能下降。具体来说,我们提出 2D Spatial Perceiver,用于将密集存储的帧级别记忆编码为更小的 token 集合,同时保留其 2D 空间结构,这对密集预测任务至关重要。作为插件模块,2D Spatial Perceiver 可以应用于任何 SAM 2 变体。此外,我们还将 SAM 中用于图像分割的知识蒸馏流程扩展到视频领域,进一步提高了 EdgeTAM 的性能,而无需推理时间成本。我们的实验表明,EdgeTAM 很好地保留了 SAM 2 的能力,在 PVS、VOS 和 SA 任务中。更重要的是,它比 SAM 2 快 倍,并且在 iPhone 15 Pro Max 上可以达到 16 FPS。
A. 视频对象分割 (VOS)
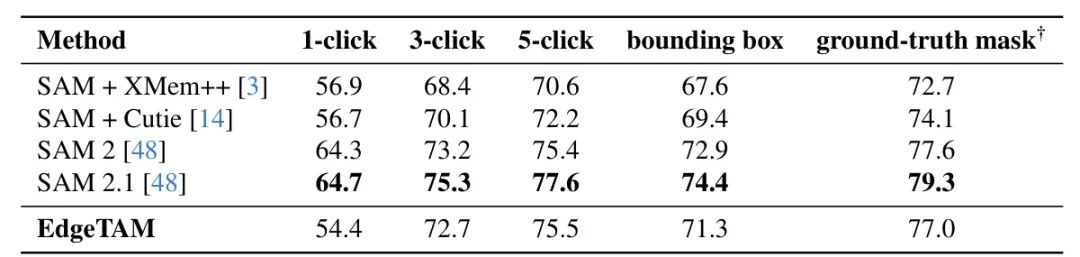
在我们的主要提交中,我们遵循标准半监督视频对象分割协议,其中在推理过程中,第一帧上的 ground- truth masks 可用。在表 4 中,我们遵循 SAM 2 [48],而不是提供第一帧上的 masks,而是使用第一帧上的点击或框提示感兴趣的对象。由于 XMem ++ 和 CuteDo 不支持这些提示,我们使用 SAM[31]将提示转换为 masks。我们评估在 17 个零样本数据集上,包括 EndoVis 2018 [2],ESD[28],LVOSv2 [25],LV-VIS[65],UVO[67],VOST[56],PUMaVOS[3],Virtual KITTI 2 [6],VIPSeg[42], Wildfires[57],VISOR[16],FBMS[5],Ego-Exo4D[22],Cityscapes[15],Lindenthal Camera[23], HT1080WT Cells[21]和 Drosophila Heart[20]。
在本次评估套件中,除了 1 键设置之外,EdgeTAM 优于强大的基线,包括 和 Cute,提高了 2 到 5 个百分点。与 SAM 2 和 SAM 2.1 相比,EdgeTAM 仍然保持了可比的性能,尤其是在更准确的提示中,例如5-点击和地面真值掩码。
B. 实施细节
我们通常遵循原始 SAM 2 训练超参数用于图像分割预训练 [31] 和视频分割训练 [48]。在此,我们仅强调差异,完整的训练细节在表 5 中显示。首先,我们不使用 drop path 或层级衰减在图像编码器中。其次,我们的图像预训练阶段采用 128 批次大小和总共 175K 训练步数。在视频训练阶段,我们减少每张图像的最大掩码数量,从 64 降低到 32。更重要的是,我们没有在 SAM 2 Internal 数据集上进行训练,因此总训练步数从 300K 减少到 130K。最后,我们的训练包括在两个阶段都采用蒸馏损失。
C. 速度基准
在表 2 中,我们提供了在服务器 GPU(NVIDIA A100 和 V100)和移动 NPU(iPhone 15 Pro Max)上的吞吐量 FPS。V100 的基准测试是从每篇单独的论文中收集的,我们自己使用另外两个硬件进行基准测试。特别是为了优化吞吐量,在 A100上,我们使用 torch 编译所有模型。对于移动 NPU,我们使用 coremltools[1]将模型转换为 CoreML 格式,并使用 XCode 的性能报告工具在 iOS 18.1 上在 iPhone 15 Pro Max 上进行基准测试。请注意,EdgeTAM 与 SAM 2 的加速比在 A100 上不如在 iPhone 上明显。为了了解根本原因,我们在 A100 上监控了两个模型的流式多处理器(SM)利用率,发现即使使用 torch 编译,EdgeTAM 的 SM 使用率只有 且推理受 CPU 和 IO 限制。我们认为这是因为高端服务器 GPU (如 A100)拥有大量的并行可执行单元(EU),而 EdgeTAM 的尺寸很小,因此无法同时占用所有 EU。然而,EdgeTAM 的设计目标是边缘设备,如手机,我们在这里看到了与 SAM 2 相比 的加速。


参考资料:
[1] EdgeTAM- On-Device Track Anything Model

(文:极市干货)