
1.什么是AI?
人工智能(AI,Artificial Intelligence)是指让机器具备人类智能的能力,使其能够执行如感知、推理、决策、学习和创造等任务。AI 的发展经历了多个阶段,从最早的基于规则的专家系统,到如今的深度学习和神经网络驱动的智能系统,使得 AI 具备了更强的学习能力和泛化能力。

AI 主要包括以下几个关键领域:
- 计算机视觉(CV):如人脸识别、图像分类、目标检测等。
- 自然语言处理(NLP):如机器翻译、文本摘要、语音识别等。
- 机器人技术:如自动驾驶、机械臂、智能家居等。
- 决策系统:如推荐系统、智能调度、金融风控等。
其中,自然语言处理(NLP) 是 AI 领域的一个重要分支,而 LLM(大语言模型)正是 NLP 领域的一项突破性技术。
2.AI与LLM 的关系
LLM(Large Language Model,大语言模型)属于 AI 领域的一个重要子集,它是 AI 发展的高级阶段,专门用于处理和生成自然语言。AI 主要提供了 LLM 发展的基础技术,而 LLM 是 AI 在自然语言处理上的具体应用。
LLM 的核心特点:
- 由深度学习模型(如 Transformer 结构)构建。
- 训练时使用海量文本数据,让模型学习语言结构和知识。
- 具备强大的文本理解、生成、推理和对话能力。
可以这样理解:
AI 是一个大范畴,LLM 是 AI 领域中专门用于语言任务的子集。
AI 赋能 LLM,使其具备自然语言处理的能力,而 LLM 则推动 AI 在文本生成、对话交互等领域的进步。
3.LLM与NLP的关系
自然语言处理(NLP,Natural Language Processing) 是 AI 的一个核心领域,旨在让计算机理解、生成和处理人类语言。NLP 研究的方向包括机器翻译、情感分析、文本分类、自动摘要、问答系统等。
而 LLM 作为 NLP 领域的最新突破,极大地提升了计算机理解和生成自然语言的能力。可以说,LLM 是目前 NLP 研究的巅峰成果,并推动了 NLP 进入大模型时代。
LLM如何影响NLP?
LLM 与传统 NLP 方法相比,有以下几个关键区别:
- 从特定任务模型到通用模型
- 传统 NLP 需要为不同任务(如情感分析、机器翻译)分别训练不同的模型。
- LLM 通过大规模预训练,能够一次训练,适用于多个任务(如 ChatGPT 可以进行翻译、对话、代码生成等)。
- 从小数据训练到大规模预训练
- 传统 NLP 方法通常依赖于特定数据集进行监督学习。
- LLM 通过无监督学习+海量数据预训练,然后使用少量样本进行微调(Fine-tuning),适应不同任务。
- 从基于规则的处理到深度学习驱动
- 早期 NLP 依赖规则和统计方法(如 TF-IDF、N-gram),处理能力有限。
- LLM 采用深度学习(如 Transformer 架构),在语义理解和文本生成上表现更强。
LLM与NLP的关系总结
- NLP 是 AI 的一个子领域,研究如何让机器理解和处理人类语言。
- LLM 是 NLP 发展的重要里程碑,通过大规模神经网络模型,实现了更强的文本理解和生成能力。
- LLM 让 NLP 进入了大模型时代,统一了多个任务,提高了处理复杂语言任务的能力。
4.LLM与生成式AI的关系
生成式 AI(Generative AI) 是 AI 的一个分支,指的是能够创造新内容的人工智能技术,包括文本、图像、音频、视频等。而 LLM 正是生成式 AI 在文本领域的代表。
生成式 AI 的主要分类:
- 文本生成(代表:GPT-4、Claude、LLaMA)
-
生成文章、代码、对话、摘要等。 - 图像生成(代表:Stable Diffusion、DALL·E、Midjourney)
-
根据文本描述生成图片。 - 音频/视频生成(代表:ElevenLabs、Runway Gen-2)
-
生成语音、音乐,甚至短视频。
LLM 之所以属于生成式 AI,是因为它能够:
- 基于已有文本生成新的内容(例如 ChatGPT 可以写文章、编故事)。
- 进行上下文理解和创作(例如 LLM 生成符合逻辑的对话)。
- 支持多模态 AI 发展(结合图像、音频等,实现更复杂的生成任务)。
可以这样理解:
生成式 AI 是一个大类别,而 LLM 是其中专门用于文本生成的技术。
5.小结
- AI 是一个广义概念,包含多个子领域,如 NLP、CV、机器人等。
- NLP 是 AI 领域中的一个核心方向,专注于让计算机理解和处理人类语言。
- LLM 是 NLP 领域的最新突破,极大提升了计算机对语言的理解和生成能力。
- 生成式 AI 是 AI 的一个应用方向,而 LLM 作为文本生成的核心技术,推动了 AI 在创作、翻译、代码编写等领域的进步。
下一步,我们将深入探讨 LLM 的工作原理、应用场景以及未来的发展趋势,看看它如何改变我们的世界!🚀

6.LLM的崛起
2022 年 11 月 30 日,OpenAI 发布 ChatGPT,迅速引发全球热议,标志着大语言模型(LLM,Large Language Model)时代的到来。短短数月,ChatGPT 就登上了各大平台热搜,并推动了各大科技公司纷纷布局 LLM 研发。
- 2023 年 2 月 6 日,谷歌宣布推出 Bard 聊天机器人。
- 2023 年 2 月 24 日,Meta 开源 LLaMA,大幅降低 LLM 研究门槛。
- 2023 年 3 月 14 日,OpenAI 发布 GPT-4,模型能力再升级。
- 2023 年 3 月 16 日,百度推出 文心一言。
- 2023 年 4 月 11 日,阿里云发布 通义千问。
- 2023 年 7 月 18 日,Meta 发布 LLaMA2,进一步推动开源 LLM 发展。
与此同时,LLM 相关论文数量在 ChatGPT 发布后呈现爆发式增长,学术界与工业界纷纷投入研究,大模型的时代正式来临。
7.LLM族谱
大语言模型的基础源自 2017 年 Google 提出的 Transformer 结构。其后,LLM 发展分为两大路线:
- Encoder-only(自编码模型):代表是 BERT,擅长理解任务,如文本分类、信息检索等。
- Decoder-only(自回归模型):代表是 GPT 系列,擅长生成任务,如文本生成、翻译等。
初期,BERT 发展迅猛,但因未能突破 Scaling Law(规模法则)而逐渐式微。GPT 研究团队发现,扩大模型规模能显著提升零样本和小样本学习能力,推动自回归模型成为 LLM 发展的主流。
8.GPT的关键贡献
GPT 系列对 LLM 发展具有深远影响,核心贡献包括:
- 预训练 + 微调架构(GPT-1, 2018):利用大规模文本数据进行预训练,再微调适配不同任务。
- 迁移学习能力(GPT-2, 2019):大幅提升模型泛化能力,使其能处理多种 NLP 任务。
- 上下文学习与涌现能力(GPT-3, 2020):提出 ICL(in-context learning),无需微调,仅凭提示词即可执行多种任务,展现涌现能力。
- 代码生成与指令遵循能力(GPT-3.5, 2022):Codex 使 AI 具备编程能力,InstructGPT 通过 RLHF(人类反馈强化学习)增强指令遵循能力。
GPT 的逐步迭代,推动了 LLM 从基础语言理解迈向更复杂的推理、代码生成和任务执行。
9.如何使用LLM
企业和开发者在使用 LLM 时,需要权衡成本、效果与应用场景,主要有以下方式:
- 微调 LLM(Fine-tuning):适用于特定任务,如文本分类、情感分析等。
- 提示词工程(Prompt Engineering):适用于文本生成任务,如文章写作、代码生成等。
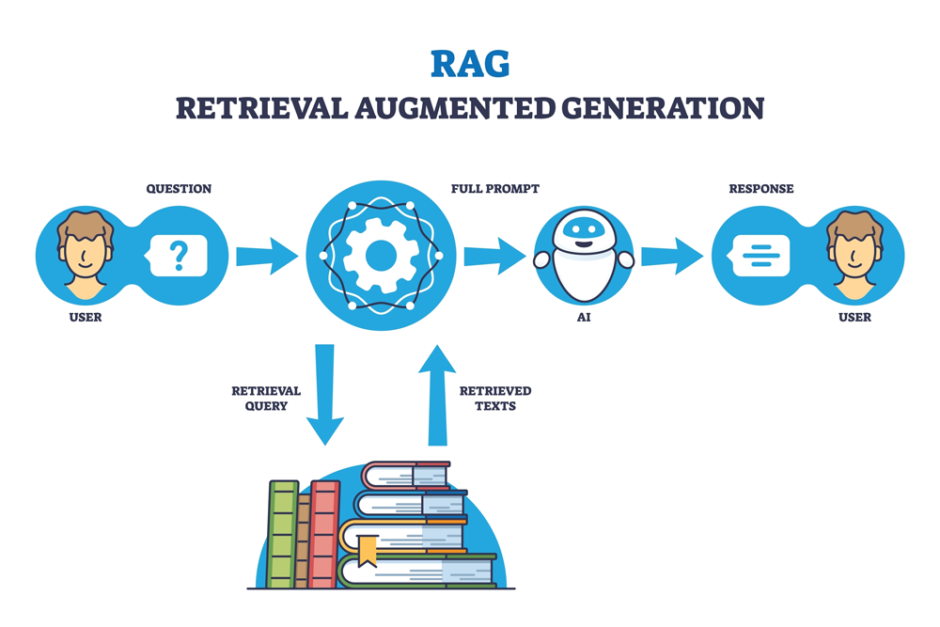
- 检索增强生成(RAG):适用于知识密集型任务,如问答系统、法律咨询等。
- Agent 结合外部工具:适用于推理计算场景,以提升准确性,减少幻觉问题。
10.LLM的挑战与局限
尽管 LLM 具备强大能力,但仍存在诸多挑战,包括:
- 模型对齐问题:确保 AI 符合人类价值观,避免生成有害或偏见内容。
- 幻觉问题(Hallucination):LLM 可能生成虚假信息,影响可靠性。
- 安全隐患:如何防止 AI 滥用,确保数据安全与隐私保护。
- 可解释性:目前仍无法完全理解 LLM 的内部工作机制,需要更多研究探索。
总结:大语言模型(LLM)的未来与挑战
大语言模型(LLM)的发展已进入全新的时代,从最初的理论探索到如今的广泛应用,取得了显著的成就。尤其是 GPT 系列模型的出现,推动了自然语言处理的飞跃,改变了许多行业的工作方式。从 GPT-1 的预训练与微调架构,到 GPT-3 和 GPT-4 的上下文学习与涌现能力,再到 GPT-3.5 的代码生成和指令遵循能力,LLM 展现了超越传统方法的巨大潜力。
然而,随着技术的进步,LLM 也面临一系列挑战。模型对齐、幻觉问题、安全隐患、可解释性 等问题依然是当前和未来研究的重点。LLM 的输出有时会产生误导性内容,称之为“幻觉”,这对应用中的可靠性提出了挑战,尤其在医学、法律等领域。
深入应用:DeepSeek与RAG
在 LLM 的应用方面,DeepSeek 和 RAG(Retriever-augmented Generation) 是两项非常重要的技术,它们扩展了大语言模型的能力,使其在处理复杂任务时表现得更加高效和精准。
- DeepSeek:作为一种先进的信息检索技术,DeepSeek 利用 LLM 来优化信息搜索和问答系统。它通过结合语义理解和检索机制,能够在广阔的数据库中精确找到相关的信息。这种方法尤其适用于需要高效检索大规模知识库、为用户提供深度解答的场景。DeepSeek 在实际应用中帮助企业构建了更智能的客服系统、法律咨询平台等,使得复杂问题的处理更加高效。
- RAG(Retriever-augmented Generation):RAG 模型结合了信息检索(Retriever)和文本生成(Generator)的优势。通过检索相关文档,RAG 模型能够为生成部分提供准确的背景信息,从而生成更符合实际问题的高质量回答。这种方法极大地提升了模型在处理复杂任务时的准确性,特别是在回答知识密集型问题和生成具有高精度内容的场景中,RAG 展现了其独特的优势。例如,RAG 可以结合外部知识库,增强模型对领域知识的理解,从而提升如医学诊断、法律分析等高风险任务的表现。
面对未来:LLM 的发展方向
随着大语言模型不断进化,除了继续优化基本的自然语言生成和理解能力,我们也看到了它在 推理、多模态学习 以及 知识密集型任务 中的潜力。未来,LLM 将逐渐变得更加多元化,可以通过增强的外部工具调用(如 Agent),结合对外部知识库的实时访问,进一步提升其智能水平。
同时,深度学习与人类认知的结合也将是未来发展的一个关键方向。如何使 LLM 更好地与人类的常识、道德观念和价值观对齐,成为了技术进步与伦理考量之间的平衡点。只有在确保大语言模型的输出与社会需求高度契合的情况下,才能真正释放其最大潜力。

持续探索与反思
虽然 LLM 在许多领域展现了前所未有的能力,但我们不能忽视它们仍然存在的风险和局限性。从技术的不断迭代到道德伦理的深入探讨,未来的 LLM 将不仅仅是技术的进步,更是人类社会、文化和智能的进一步融合。如何克服现有问题,确保 LLM 的安全、高效与可控,将是每个从业者和研究者持续关注的重要课题。
(文:PyTorch研习社)