


今年英伟达大会(GTC 2025)邀请到了 OpenAI 的人工智能推理研究负责人、OpenAI o1 作者诺姆·布朗(Noam Brown)参与圆桌对话。
他先是带着大家回顾了自己早期发明“德扑 AI”的工作,当时很多实验室都在研究玩游戏的 AI,但大家都觉得摩尔定律或者扩展法则(Scaling Law)这些算力条件才是突破关键。诺姆则在最后才顿悟发现,范式的更改才是真正的答案:“如果人们当时就找到了正确的方法和算法,那多人扑克 AI 会提前 20 年实现。”
究其根本原因,其实还是很多研究方向曾经被忽视了。“在项目开始前,没有人意识到推理计算会带来这么大的差异。”
毕竟,试错的代价是非常惨痛的,诺姆·布朗用一句很富有哲思的话总结了直到现在都适用的一大问题:“探索全新的研究范式,通常不需要大量的计算资源。但是,要大规模地验证这些新范式,肯定需要大量的计算投入。”

左为英伟达专家布莱恩·卡坦扎罗,中为诺姆·布朗,右为主持人瓦尔蒂卡
在和英伟达专家的对话过程中,诺姆还对自己加入 OpenAI 之前、成为“德扑 AI 之父”的故事做了回顾,因此这部分便不再赘述,让我们先快速回顾一遍 o1 曾经造成的轰动。
众所周知,OpenAI 是 AI 圈的热搜之王。
围绕它这几年的炒作,用一篇文章可能都放不下:先是首席科学家 Ilya Sutskever 宣布“AI 已具备意识”、然后高层地震、首席执行官 Sam Altman 被短暂罢免、Ilya 不久之后离职、联合创始人 Greg Brockman 休长假、第二轮高层动荡、“硅谷美女 CTO” Mira Murati 离职……
这些惊天大瓜的背后,是曾经流传在传说中的「Q*」项目。从 GPT-4 发布后的一年里,国外各大媒体一次又一次地暗示爆料 Q* 的进展,OpenAI 自己从未正面回应它,但许多从 OpenAI 离职的科学家都暗示过他们在开发一个能“威胁人类”的 AI。
Q* 后来更改代号为“Strawberry”,最终孵化为世界上的第一个推理模型——OpenAI o1-preview。

于是在 2024 年 9 月之后,OpenAI 开始了新的炒作,并开启了 AI 领域新一轮的赛跑,目标是:谁能先把 o1 复现出来?
当时许多公司其实基本找到了追赶 GPT-4 和 GPT-4o 两款模型的路径,但面对 o1 这见鬼一样的推理能力,皆是一筹莫展。上至 Anthropic、Google 和 Meta,下至国内外各种初创公司和学术机构,都倒在“CloseAI”的闭源高墙面前。
最后的结局反倒是大家都知道的:2025 年 1 月,DeepSeek-R1 发布,英雄登场,开源了研究成果,漫长的赛跑告一段落。

难倒全天下 AI 公司的 OpenAI o1,由一百多名研究人员在多年之间研发完成,上图的 18 个人是核心贡献者,他们的项目领导就是诺姆·布朗。
在项目开始前,他就给 o1 定下了方向:“我们需要开发出一种推理方法,它应该像深度学习在快思考(System 1)思维方面所展现出的那样,具有广泛的适用性和高度的灵活性。”
最终的目标,就是为 OpenAI 开发一个能够进行慢思考(System 2)思维的推理模型。

诺姆在对话中也分享了不少自己试错中得到的感悟,比如:“预训练仍然至关重要。预训练和推理是相辅相成的,它们是携手并进的,我认为我们会在这两个方面都看到持续的进步。
当前 AI 圈人人都面临算力紧迫的问题,所以诺姆建议我们先从对算力要求不那么高的地方开始改善:“人工智能基准测试的现状非常糟糕,这种单一数字的比较,其实已经毫无意义了。你必须从“单位成本智能”的角度来思考,比如每个 token 能买到的智能。
铺垫到此为止,让我们进入正题吧。
主持人:我是英伟达战略技术合作伙伴关系负责人,瓦尔蒂卡·辛格(Vartika Singh),很荣幸主持这场专题讨论会,主题是“高级人工智能推理:从游戏到复杂推理”(Advanced AI reasoning from games to complex reasoning)。我想先为讨论设定一下背景。
现在的人工智能正处在一个关键时刻。算法的重大突破不断涌现,并得益于日益强大的计算能力。今天的对话,我们请到了两位领军人物,他们的工作正是这种融合的体现。
一位是来自 OpenAI 的诺姆·布朗(Noam Brown),他的工作促成了我们对人工智能如何在战略性复杂推理和游戏中取得卓越成就的理解。
另一位是英伟达应用深度学习研究副总裁布莱恩·卡坦扎罗(Bryan Catanzaro),他一直站在前沿,构建工业级、可扩展的训练和部署系统。
介绍完背景,我们不妨先请两位谈谈,如何将你们的工作放到人工智能推理的大背景下进行理解。诺姆,你先开始怎么样?
诺姆·布朗:我大概在 2012 年进入人工智能领域,开始在卡内基梅隆大学攻读博士学位。我研究的是游戏人工智能,最初是扑克 AI。当时,国际象棋这类完美信息博弈已经取得了很大进展,围棋也在不断进步,但没人真正知道如何将这些技术扩展到扑克这种非完美信息博弈。如何才能开发出超越人类水平的扑克 AI——更广泛地说,如何在非完美信息博弈中实现超越人类水平的 AI?这大概是我博士期间六年时间的研究方向。
2017 年,我们开发出了第一个超越人类水平的扑克 AI(Libratus),但它专攻的是两人扑克。
2018 年,我去了 Meta,并开始研究多人扑克。2019 年,我们在 Meta 开发出了首个超越人类水平的多人扑克 AI(Pluribus)。
然后,我把重心转向了其他方面,包括尝试将这些技术扩展到自然语言领域,应用到自然语言博弈,也就是经典桌游《强权外交》(Diplomacy)当中。
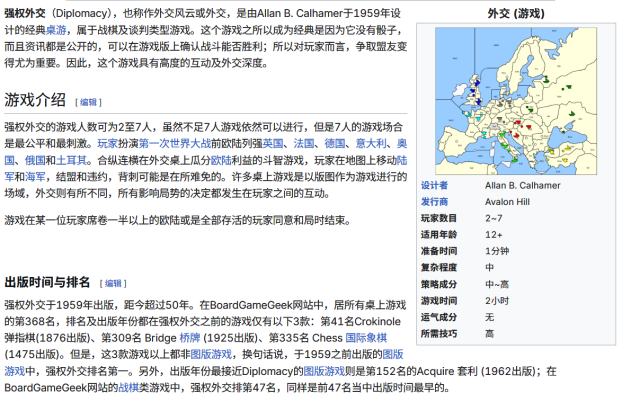
随后在 Meta 工作期间,我和同事们一起开发了 CICERO,首个在《强权外交》这款游戏达到人类玩家水平的 AI。
期间我注意到,所有这些技术都在运用推理能力。所以,一个重点就是,如何让人工智能在做决策时进行更长时间的思考,从而得出更好的结果。
我从这些研究中发现,我们在扑克中使用的技术,与国际象棋中使用的技术非常不同,我们在《强权外交》游戏中使用的技术,又与国际象棋和扑克中使用的技术大相径庭。
那么,我们能不能开发出一种非常通用的推理方法呢?最好是能应用于像语言这样广泛的领域。正是这个想法促使我来到 OpenAI,在那里,我和许多杰出的同事一起开发了 OpenAI o1 系统。
诺姆当年的豪言壮语
布莱恩·卡坦扎罗:你的工作经历真是令人印象深刻。我大概是从研究生时期开始研究 AI 系统的,我在 2008 年的 ICML 会议上发表了我的第一篇论文。
当时我展示了如何在 GPU 上训练一些模型,结果人们问我:“你来这里干什么?” 这说明十七年前,计算能力对于人工智能发展的重要性,可能还不是那么显而易见。
但我坚信,推动计算系统,是推动人工智能向前发展的巨大机遇。因此,我在 2011 年全职加入了英伟达。我的工作,促成了 QDNN 的诞生,这是英伟达首个用于 GPU 上 AI 的库。从那时起,我有幸参与了很多其他项目,包括 DLSS,它利用机器学习来加速图形渲染过程。如今,由于 AI 的实时应用,我们的图形渲染效率提高了大约 8 到 10 倍,我对此感到非常兴奋。尤其现在 AI 正在进入虚拟世界,并以全新的方式进行互动,我认为这非常重要。
还有,这些年来,我们一直在致力于语言相关的系统研发。我们构建了一个名为 Megatron 的系统,我认为它推动了行业进步,帮助扩展了大型语言模型的训练。我对未来充满期待,希望能够将所有在 AI 系统方面的工作提升到一个新的水平,以支持更强大的推理能力。
主持人:两位的工作都非常出色。那么,我们先从游戏部分开始聊起。诺姆刚刚提到了 Libratus 和 Pluribus,然后是 CICERO,我看到这三个项目之间存在着明显的区分,或者说某种程度上的界限。
你提到,这三者之间存在某种内在联系,最终促成了 OpenAI o1 的诞生,以及 OpenAI o1 中的推理能力。能否详细描述一下,你在这些工作中主要考虑了哪些技术?
诺姆·布朗:我认为我早期关于扑克 AI 的大量研究,实际上并没有过多地关注推理。很多研究更像是“预训练”。你会花大量时间来训练这些模型,可能要在大型系统上训练两到三个月。此外,我们那时还没用 GPU,实际上用的是 CPU。但是,当真正开始玩牌时,AI 的反应速度非常快,可能只需要 10 到 100 毫秒。它的工作原理就像一个查找表。
之前也有一些研究,探讨如何为这些系统增加推理计算能力,但这并不是研究的重点。原因有很多,其中一个是让 AI 具有推理能力本身就非常困难。现在大家都知道,AI 玩国际象棋运用了 Alpha-Beta 剪枝技术,AI 玩围棋则是通过蒙特卡洛树搜索。但这两种技术在扑克中都行不通。所以,扑克推理一直是一道难题。
此外,扑克是一种方差非常高的游戏。玩牌的人都知道,就算你牌技很差,也有机会靠运气赢钱。即使是职业扑克玩家,也可能因为年景不好,打了一整年牌最后还是亏钱。但如果突然之间,你对每一张手牌的思考时间从 10 毫秒变成了 20 秒,问题就来了——因为这中间可能要过掉上百万张牌,才能从结果中判断一个 AI 是否比另一个 AI 更厉害——你肯定不想花那么多时间。所以,有很多原因导致这个研究方向被忽视了,而最大的原因,是人们没有意识到推理计算会带来这么大的差异。
我在研究过程中,总觉得好像缺了点什么。人类在遇到棘手情况时,在行动之前会花很多时间思考。也许,这种思考能力会非常有用。当我深入研究这个问题,并看到它带来的巨大改变时,我立刻意识到,这方面需要大力发展。所以我们最终在 AI 扑克使用的技术,与国际象棋、围棋等游戏中使用的技术非常不同。所以对我来说,真正的启示是并不存在一种通用的系统可以解决所有问题。
主持人:这里面有一个从快思考(System 1)到慢思考(System 2)的转变。
诺姆·布朗:没错。2017 年我们开发的扑克 AI 叫 Libratus,我认为那是一个重大突破。然后在 2019 年,我们推出了 Pluribus,我认为它的性能更进一步。两者之间具体细节的差异,其实没那么重要,重点在于 Pluribus 成本更低。我们开发出了一种更好的、扩展推理计算的方法,让成本进一步降低。2019 年的 Pluribus,在云端计算上训练的成本不到 150 美元。
我认为这个结果真正表明,这不仅仅是摩尔定律或者 Scaling Law 在起作用,而是我们实际上采用了一种不同的范式,它在推理阶段利用了更多的计算资源。正因为如此,我们才能够实现这样的突破。如果人们当时知道要采取这种方法,并且知道要使用哪些算法,那么 20 年前就能做到这一点。
主持人:你说训练它只花了 150 美元。那在实际玩牌的时候,它的计算量大概是 10 万美元对 5 万美元的水平吗?
诺姆·布朗:Pluribus 在推理时,使用了 28 个 CPU 核心。每张手牌大约需要 20 秒的推理时间。这其实已经很便宜了,但如果和以前的技术相比,以前只用一个 CPU,每张手牌大约只能推理 10 毫秒甚至更短的时间,所以在推理计算方面,这绝对是一个巨大的提升。
主持人:这真是令人印象深刻。我们接下来聊聊你的另一项工作,CICERO。你在其中融入了语言组件,用于 AI 的对话、谈判和沟通。
布莱恩·卡坦扎罗:诺姆,我想请你先解释一下《强权外交》这款游戏,可能有些人还没玩过。
诺姆·布朗:《强权外交》是一个七人游戏。它涉及到自然语言交流。实际上,这款桌游的真正复杂之处,在于与其他玩家进行谈判。游戏实际的机制非常简单,复杂性主要来自于与人互动。
在我们的扑克 AI 取得成功之后,与此同时,DeepMind 在《星际争霸》和 OpenAI 在《Dota 2》等游戏上也取得了成功。我们当时就在思考,接下来应该关注什么方向?差不多在那个时候,我们也看到了语言模型方面的图片,因为 GPT-2 就在 2019 年发布。
总之,一直以来,我和我的同事们都在讨论《强权外交》这款游戏。实际上,我以前觉得研究这种桌游简直是天方夜谭。我当时想,这太难了。但是,我的同事 Adam Lerer 说服了我,他说,为什么不试试呢?不妨把目标定得更高一点。

Adam Lerer
我们已经在扑克 AI 上取得了巨大的成功。所以我们当时就在想,我们怎样才能超越之前的成就呢?不如就瞄准一个高风险、高回报的目标,如果成功了,那肯定会非常酷。
布莱恩·卡坦扎罗:我认为要玩好《强权外交》这款游戏,不仅要非常擅长推理和战略思考,还要有说服力。你必须建立同盟,然后在合适的时机背叛他们。所以我认为,这比扑克或国际象棋要难得多,扑克和国际象棋的规则要严格得多,也更机械化。《强权外交》这款游戏更加模糊,也更人性化。
主持人:这就是我想说的,与你之前在扑克 AI 方面的工作相比,CICERO 是在 Meta AI 做的,对吧?不是在 CMU 做的。它包含了一些超越你之前为扑克 AI 所做的工作的内容。
诺姆·布朗:《强权外交》这款游戏的复杂性,我认为可以从三个维度来看。
首先,我们的研究从扑克这样的双人零和游戏,变成了一个涉及多名玩家、涉及到真人并且需要理解真人的游戏。这其中还有很多复杂性,我们可以专门开一个讨论会来探讨。
还有一个维度是,我们进入了自然语言领域,在一个如此开放、如此自由的行动空间中进行推理,又意味着什么?在国际象棋中,任何一个时刻,都有大约 20 个合理的行动可以选择。而在扑克中,可能就是弃牌、跟注、加注这几个选项,
当然,还有如何平衡这些行动的问题,但总的来说,行动空间还是相对有限的。而在《强权外交》这种桌游里,你的行动空间是你可能对另一个人说的一切。这种复杂性,直接把推理难度提升到了一个全新的水平。
主持人:在我们深入讨论 CICERO 之前,我想补充一个问题。你刚刚提到计算量显著减少了,这为后来 Libratus 和 Pluribus 之间的发展奠定了基础。是什么让这种降低成为可能?主要是算法上的改进,对吗?
诺姆·布朗:从 Libratus 到 Pluribus,双人扑克 AI 变成了六人扑克 AI,训练成本降到了 150 美元,这主要是算法上的改进。而真正的原因是,我们开发出了更好的推理技术,这让我们可以在预训练上投入更少的精力,并将更多的计算负担转移到了推理阶段。
主持人:那么,当你转向 CICERO 时,计算需求发生了怎样的变化?它是你在 CPU 上对扑克 AI 所做的工作,与 GPU 计算的结合吗?
诺姆·布朗:不,那时候我们已经转向了。一旦你开始处理自然语言谈判,你就必须转向神经网络,转向语言模型。所以,计算负担就转移到了 GPU 上。
主持人:我想接着 GPU 的话题来问一问布莱恩。传统的深度学习一直都是矩阵乘法密集型的,因此 GPU 在这方面表现非常出色。自从诺姆和他的团队和导师们最初在扑克 AI 方面开展工作以来,推理方面的工作也成倍增加。当你在英伟达内部进行设计或研究时,你是如何考虑这个问题的?
布莱恩·卡坦扎罗:我们在英伟达所做的工作,实际上是试图理解世界上最重要的计算,然后从头到尾优化它们。显然,我们制造 GPU,然后制造网络,但我们也构建编译器、库、框架,并且我们也研究算法和应用。我们加速计算的目的,是为了让大家能够做到以前做不到的事情。
黄仁勋在他的主旨演讲中说,他听到的最高赞扬,是一位科学家说:“感谢你们,我真的可以在我的有生之年完成我毕生的工作了。” 这就是我们在英伟达的目标。我们坚信,要提供真正能改变行业格局的加速,实现像诺姆提到的那种突破,唯一的办法就是从头到尾地思考问题,并在技术栈的每一层,寻找加速的机会。所以,这就是我们所做的事情。
现在,你刚才提到了一个很有意思的点,说这项工作实际上是矩阵乘法密集型的。这确实没错。我相信,人工智能算法和人工智能系统的发展是相辅相成的。人工智能系统对于人工智能的发展至关重要。算法显然也非常重要,而且成功的算法往往是协同进化的。
有趣的是,如果大家回顾一下 2012 年,当 Alex Krizhevsky 和 Ilya Sutskever 发表 ImageNet 论文时,如果你仔细阅读那篇论文,它完全重新定义了整个计算机视觉领域,但它本质上是一篇系统论文。它主要探讨的问题是,我们如何以更有效的方式训练更大的模型?

这种系统层面的投入,带来了许多算法上的突破,这些突破彻底重塑了整个计算机视觉领域。然后,随着不断迭代,就会形成一个良性循环。我相信,人工智能领域之所以如此受矩阵乘法主导,原因之一在于,这是构建能够完成大量计算工作的计算机,最有效的方式。
矩阵乘法的特性,非常适合我们现有的技术,比如构建系统、在数据中心之间分配计算任务,以及构建可以投入大量计算资源的模型。我认为这非常重要。当然,将矩阵乘法转化为智能,绝非易事。我们整个社区花费了数十年的时间,才弄清楚如何达到今天的水平。但我认为,重要的是要认识到,这些要素——系统和算法——它们是相互关联和协同发展的。在我的职业生涯中,我一直看到它们彼此需要。我们投入到人工智能中的计算资源越多,效果就越好,算法也会变得更智能,这反过来又会推动下一轮的创新。
诺姆·布朗:我认为布莱恩说得 完全正确。算法和计算之间确实存在着紧密的联系,设计优秀算法的关键,在于开发出一种能够最有效地利用计算资源,并最大程度地扩展计算能力的技术。当我们思考算法时,我们总是会考虑它的可扩展性。比如,如果我们将计算规模扩大一千倍,会发生什么?它会遇到什么瓶颈?这实际上是我很多工作,当然也是很多其他研究工作的出发点。
主持人:你们早期的很多工作都是在学术界完成的。现在我看到很多论文,也和很多研究人员交流过,感觉现在发表的大部分论文,都离真正令人兴奋的成果还差一口气,这主要是因为缺乏足够的计算资源。
但即便如此,当你们最初开展研究工作时,也已经能够使用相当强大的超级计算机了,这在多大程度上是一个关键因素呢?因为从你们从学术界过渡到 Meta,再到 OpenAI,发展轨迹一直非常顺畅和连贯。
诺姆·布朗:确实,如果以研究生的标准来看,我当时能使用的计算资源已经非常多了。我们当时用的是数千个 CPU——现在看来这不算什么,但对于当时的研究生来说,已经非常了不起了。我确实认为,在某种程度上,这最终成为了一个非常重要的因素。我认为,如果没有那些计算资源,我们不可能在扑克 AI 方面达到超越人类的水平。
我之前说过,在 2019 年,我们开发的那个机器人,训练成本不到 150 美元,并且可以在 28 个 CPU 核心上运行。当你达到那个阶段,最后的训练成本非常低,推理成本也相对较低,但是,所有前期为了找到正确的研究范式所做的探索,成本是非常高昂的。为了能够比较不同的推理技术,并得出结论,像是“这种技术的性能,和将推理规模扩大一千倍,并在 2000 个 CPU 核心上运行三个月的效果相当”——为了能够进行这样的比较,就需要大量的计算资源。
因此,我认为现在这确实是一个挑战。我经常和很多研究生交流,他们会问我,在计算规模变得如此巨大的时代,我们如何才能做出有影响力的研究?这是一个很难回答的问题。当然,在像 OpenAI 这样的前沿实验室,进行这种前沿能力的研究,肯定要容易得多。在学术界,仍然可以做出有影响力的研究。
我认为,探索全新的研究范式,通常不需要大量的计算资源。但是,要大规模地验证这些新范式,肯定需要大量的计算投入。不过,前沿实验室和学术界之间,还是存在合作机会的。前沿实验室肯定会关注学术界发表的论文,并认真思考,这些论文是否提出了令人信服的论点,证明如果将论文中提出的方法进一步扩展,将会非常有效。如果论文中确实有这种有说服力的论点,我们就会在实验室里进行深入研究。
此外,像评估、基准测试之类的工作,也存在机会。人工智能基准测试的现状非常糟糕,而改进基准测试,并不需要大量的计算资源。
主持人:但这需要一些投入,比如在设计和整合方面。
诺姆·布朗:这确实需要大量的工作和努力,但对于计算的负担相对较低。
布莱恩·卡坦扎罗:是的。我认为,人们开展研究工作的方式,也存在一些必要的差异。前沿实验室,可以负担得起在一个项目上投入大量资源,并将其做大的成本。比如,大家可以看看 GPT-4 的论文,有多少作者参与了这篇论文,对吧?而学术界,有发表论文的需求,这样学生才能毕业。学生需要完成博士论文,所以他们需要对某一部分工作拥有主导权。
我之所以说这些,是因为我实际上相信,人工智能正在吞噬的第一个领域,就是人工智能研究本身。因为各种力量都在推动我们进行合作,构建更宏大的项目,让更多人参与进来,这样我们才能真正敢于下大赌注,进行大规模投入。这使得那种研究模式,变得非常困难,即我们有很多小型项目,每个项目都试图在某个方面达到最先进的水平。
我认为,这正在推动整个领域,走向一种新的模式,即学术界仍然会涌现出许多非常有趣和重要的研究工作,但这些工作必须以较小的规模进行。然后,将这些学术研究成果,整合到前沿模型中的过程,也就是整合到像你在 OpenAI 构建的那种,最终会被实际部署的模型中的过程,我认为这必须作为第二步来完成。这主要是因为,构建这些模型所需的投入实在太大了,我认为这确实正在改变我们进行研究的方式。
主持人:这是一个值得进一步探讨的话题。让我们回到《强权外交》和 CICERO 相关的工作上。诺姆,你前面也有提到 OpenAI o1,而在最终目标方面,它和 CICERO 之间存在一些差异。
但是,如果大家对外交这类事情非常感兴趣,并且你们已经在某种游戏环境场景中,成功地实现了用于外交的 AI。那未来是否有可能将这项技术,应用到现实世界的情境中,比如谈判或多方政府对话等等?
诺姆·布朗:对于外交 AI 的研究工作,也就是关于《强权外交》游戏的 CICERO 项目,我们从这项工作中学习了很多,我认为整个社区也从中获益匪浅。我认为我们更深入地理解了,开发用于多智能体环境的 AI,意味着什么?在一个非常灵活、开放的环境中进行推理,又意味着什么?用于外交 AI 的技术,在某种程度上是特定于《强权外交》这款游戏的。
主持人:那如果有人问,CICERO 能否直接用于现实世界的谈判?
诺姆·布朗:不能。至少没法开箱即用。这并不是我们研究的真正目的,这并不是我们最初的目标。我们的目的是,探索自然语言博弈中的“外交”这个领域。因为如果你把所有现有的技术,比如 Alpha Zero、Pluribus,都拿来尝试应用于这款游戏,你会发现它们根本行不通。这说明,一定有什么东西是缺失的。然后,通过探索这个领域,弄清楚缺失的到底是什么,你就能从这个过程中学到很多东西。
学术界也能从这个过程中学到很多。我个人从中得到的一个重要启示是,我们之前开发的推理技术,都太过于狭隘了。深度学习最美妙的地方之一,就是它极其灵活的范式。你可以把 Transformer 模型,应用到各种不同的领域,它基本上都能开箱即用。但事实上,我们却不得不为所有这些不同的场景,为扑克、国际象棋、围棋和《强权外交》开发出非常特定于领域的推理技术,这大大减缓了开发进程。
我们确实开发出了一种在《强权外交》游戏中有效的推理技术。我们也取得了非常出色的性能。但这却花费了数年的时间才开发出来。如果我们接下来想研究,比如现实世界中的实际谈判,那又需要花费数年时间,才能开发出适用于那种场景的技术。所以,我从这项工作中得到的启示是,我们需要开发出一种推理方法,它应该像深度学习在快思考(System 1)思维方面所展现出的那样,具有广泛的适用性和高度的灵活性。
主持人:我想问两位一个问题。首先,我假设我们最终肯定会达到目标,我们会构建出真正的多智能体环境,在其中可以进行复杂的谈判。那在那种情况下,计算能力,计算技术的进步,以及算法的进步,都必须携手并进。Brian,你是如何看待这种未来发展趋势的?
布莱恩·卡坦扎罗:其实黄仁勋在他的主旨演讲中,已经很好地阐述了这一点。他谈到了针对不同任务的不同扩展方式。我认为我们现在可以清楚地看到,推理作为一个计算问题,其规模是非常庞大的。因为,当我们在训练这些模型,当它们学习如何推理时,它们需要不断练习,它们需要学习,需要不断尝试,获得反馈,然后再尝试。因此,这里存在着一个巨大的机会,可以将计算资源,或者说模型的推理能力,转化为智能,这是一种我们以前从未实现过的转化方式。这就是我对这个问题的看法。
现在,这对于我们将要构建的系统类型,以及我们将要运行的软件,都产生了巨大的影响。这与之前那种预训练密集型的模型,截然不同。在预训练密集型模型中,绝大部分计算资源,都投入到了训练模型本身,也就是在越来越大的数据集上,训练越来越大的模型。
我认为,预训练仍然非常重要,因为我把预训练看作是构建推理能力的基础。基础越牢固,推理能力就越强大。因此,我们将继续看到进步,而且这些进步的速度,甚至超过了摩尔定律。无论是训练模型的速度,还是在相同的计算资源下,模型所能拥有的智能水平,都在以超越摩尔定律的速度提升。这要归功于所有投入到基础模型本身的研究工作。
但是,我们投入到后训练和推理计算中的计算资源,正在快速增长。我们英伟达正在思考,这对网络技术、低精度运算、稀疏性计算以及如何设计下一代推理系统,会产生怎样的影响,这十分令人激动。我认为这才是我们当前的首要任务。如果大家回顾一下昨天主会演讲的内容,就会发现,英伟达认为这对于整个世界来说,都是一个巨大的机遇,我们非常兴奋能够帮助推动它向前发展。
诺姆·布朗:我完全同意布莱恩的看法。我认为,我们现在正处在一个非常激动人心的时刻。我们现在拥有了真正的推理模型。我认为,从 OpenAI o1 开始,这些模型就能以非常广泛的方式进行推理,这在我看来,是一种全新的范式。就像 AlexNet 的出现,引发了对推理计算的大规模投入一样,而不是仅仅关注训练,而是开始大力投入 GPU 和其他硬件的研发。我认为,我们现在正处在一个关键节点,我们拥有了能够进行慢思考(System 2)思维的推理模型,而不仅仅是快思考(System 1)思维。而且,这个领域还有巨大的扩展空间,也有很大的潜力去开发,专门针对推理计算的硬件。
当然,这并不是说预训练已经过时了。我也同意布莱恩的观点,预训练仍然至关重要。我和一些尝试为小规模 LLM 开发推理技术的人交流过,结果发现根本行不通。比如,你尝试在 GPT-2 这样的小模型上,实现像 OpenAI o1 这样的推理能力,根本无法取得进展。所以,预训练和推理是相辅相成的,它们是携手并进的,我认为我们会在这两个方面都看到持续的进步。
布莱恩·卡坦扎罗:我认为,也许目标已经发生了转变。至少在我过去从事预训练研究时,预训练的目标只是尝试获得一个能够收敛的模型,并且要尽可能地扩大模型规模,尽可能在最大的数据集上训练模型。然后,模型主要还是以快思考(System 1)的方式来使用,比如,你给它一个问题,它会直接给出一个答案,对吧?因此,在那种模式下,当你考虑如何构建系统,以及如何使用系统的平衡时,你会发现,大部分的计算资源,都投入到了构建系统本身,而使用系统则相对简单直接。
但随着推理技术的进步,现在,我们有了一个更加复杂的训练过程,因为推理本身,也成为了训练过程的重要组成部分。因此,用于在推理后训练阶段,进行大规模推理的软件和硬件,与我们用于预训练的软件和硬件,是完全不同的。
这里面蕴藏着巨大的加速潜力。所以,我对此感到非常兴奋。此外,当模型被部署之后,现在在我看来,推理成本与智能水平是直接相关的。因为,如果你能大幅降低模型的推理成本,那就意味着它可以进行更长时间的思考,从而更好地解决问题。
而在过去,情况并非如此,对吧?在以前的思维模式下,我们总是希望模型尽可能地庞大,因为模型越大,就越智能。但现在,我们希望模型能够达到一个最佳平衡点,也就是,在单位推理成本下,模型所能达到的最大智能水平。这样的模型最终才会成为最智能的模型。因此,从加速计算的角度来看,这已经是一个完全不同的问题了。
诺姆·布朗:我认为布莱恩提出了一个非常好的观点。很多人可能没有意识到,用基准测试的性能来衡量模型智能,这种单一数字的比较,其实已经毫无意义了。你必须从“单位成本智能”的角度来思考,比如,每美元能买到的智能,或者每 token 能产生的智能。如果一个模型可以进行非常长时间的思考,它在所有这些基准测试中的表现都会更好。因此,你真正需要考虑的,是一条智能与成本的曲线。上限可以非常高,如果你愿意投入足够的成本。我认为,这就是我们未来发展的方向。
布莱恩·卡坦扎罗:我们未来肯定会愿意投入更多成本。我对此相当确信,因为即使是现在最昂贵的模型,也比人类便宜得多,令人惊讶的是。它们产生的碳排放量也比人类少。这意味着,我们将能够找到更多方法,利用它们来解决比今天更多的问题。而且我认为,作为一个社区,我们将会找到各种方法,让真正深度参与的推理程序,来解决真正重要的问题。我认为,这将彻底改变人工智能的应用方式。
诺姆·布朗:我认为,当人们看到这些推理模型时,他们可能会觉得,哦,这东西太贵了。但问题是,和什么比呢?如果和 GPT-4 相比,那当然,它确实很贵。但如果和试图完成同样任务的人类相比,那就太便宜了。与人类进行比较,是非常有意义的,尤其是在智能水平不断提升的情况下。一旦这些模型在某些领域超越了顶尖人类,你就可以思考一下,世界上最顶尖的人才,完成一项任务,会获得多少报酬?他们会因为自己的专业知识,而获得非常高的溢价。而现在,模型已经具备了这种专业知识,但成本却只有人类成本的一小部分,这其中蕴含着巨大的价值。
主持人:那么,回到今天讨论会的主题,你们从游戏和人类的互动中,学到了一些东西。你从 Libratus 到 Pluribus 的转变,观察到人类在回答问题之前,会花更多的时间思考。你们是否会重新审视这一点?因为人类本性中,还有一些方面,比如适应性等等,实际上尚未被 AI 模型所捕捉。这仍然是一个开放的研究领域吗?还是说,已经有其他和你一样优秀的科学家正在研究这个问题了?
诺姆·布朗:我认为,如果你审视一下今天的人工智能范式,就会发现,我们还没有完全解决所有的研究问题。仍然存在一些开放性的研究问题,需要我们去探索和解答,才能最终解锁,我个人认为,是全面解锁超级智能。如果你回顾过去 15 年,特别是过去 5 年的进步速度,我认为这已经超出了所有人的预期。而且现在有很多 AI 批评家,他们会指出某些方面,然后说“你看,这些模型做不到这个或那个”。人们已经这样说了 10 年了。
布莱恩·卡坦扎罗:哦,不止 10 年了。
诺姆·布朗:是的,但真正重要的是,你必须关注技术发展的轨迹。没错,现在有一些事情是模型还做不到的。但是,已经有人在努力解决这些问题了。在我看来,我们有非常充分的理由,对未来的进步保持乐观。因此,你必须从发展的眼光来看待问题,思考一年后、两年后,人工智能会发展到什么程度。我认为,未来的发展会非常令人印象深刻。我的意思是,即使未来没有任何进一步的研究进展,我们今天拥有的模型,也已经足以带来变革性的影响。
主持人:最后一个问题想问两位。在几年之后,拥有最先进人工智能推理能力的理想世界,在你们看来会是什么样的?它会是一个理想的世界吗?
布莱恩·卡坦扎罗:假设所有这些研究都取得成功,人们也找到了应用这些技术的有效方法。
主持人:并且,我们暂且不讨论它的合法性问题。
布莱恩·卡坦扎罗:我认为人工智能最终会是合法的,因为我们确实需要它。我认为世界需要人工智能。当我环顾四周,我看到这个世界对智能的需求是如此巨大。我们有太多问题不知道如何解决。我们有太多的机会,可以找到更好的方法来建设世界,让世界变得更安全,解决我们社会长期存在的各种难题。我认为,我们需要更多的智能来应对这些挑战。而人类的力量,与强大的推理模型相结合,意味着你将拥有一个强大的团队,来帮助你解决最复杂的问题,帮助你理清最棘手的问题。这将使人类能够做出一些真正重要的改变,帮助我们所有人生活得更好。所以我对未来,真的非常乐观。
诺姆·布朗:我对未来持乐观的愿景。我认为人工智能是一项非常强大的技术,我对未来最乐观的设想是,它将显著提高生产力,加速科学进步。就像我们在过去一百年,甚至更长时间里,看到的令人难以置信的社会进步一样,婴儿死亡率大幅下降,人类文明在许多方面都取得了巨大的进步。人工智能将进一步加速这些进步。所有这些美好的事物都将继续发展壮大。
当然,任何强大的技术,都存在风险,既有积极的一面,也有消极的一面。我希望,消极的风险也能得到妥善解决。但我个人还是比较乐观的。我相信,这些模型最终将能够,正如布莱恩所说,增强人类的能力,与人类形成互补,促进科学进步,实现那些原本不可能实现,或者需要花费更长时间才能实现的突破。我认为,这就是我们对未来保持乐观的理由。
* 本文由 CSDN 精编整理。
* 本场对话源自 GTC 2025,日程为北京时间 2025 年 3 月 20 日 2:00 AM – 2:40 AM。
【活动分享】2025 全球机器学习技术大会(ML-Summit)将于 4 月 18-19 日在上海举办。大会共 12 大主题、50+ 位来自学术界和一线技术实战派的顶尖专家,聚焦下一代大模型技术和生态变革技术实践。详情参考官网:http://ml-summit.org/。

(文:AI科技大本营)