
作者:田小幺
编辑:李宝珠
转载请联系本公众号获得授权,并标明来源
英伟达联合阿肯色大学医学院、美国国立卫生研究院及牛津大学组成的跨学科团队提出了一种 VISTA3D 多模态医学影像分割模型。该模型首创三维超体素特征提取方法,通过统一架构实现三维自动分割与交互式分割双模态的协同优化,在包含 23 个数据集的综合基准测试中,其分割精度较现有最优专家模型提升 5.2%。
自 1971 年首台临床 CT 扫描仪诞生以来,医学影像经历了从二维切片到三维立体的革命性跨越。现代 256 排螺旋 CT 可在 0.28 秒内采集 0.16mm 层厚的全身扫描数据,7T超高场磁共振甚至能捕捉海马区神经纤维的微观走向。但当这些包含数千万体素的三维矩阵呈现在医生面前时,精准分割器官、病灶与血管网络的任务,仍高度依赖人工逐层勾画。研究显示,一套典型腹部 CT 影像的肝脏分割需 45-90 分钟,而涉及多器官联动的放疗规划标注可能持续 8 小时以上,专业人员的视觉疲劳导致的边界误差率可达 12%。
这种困境催生了医学图像分析领域最活跃的创新赛道。从早期基于灰度阈值的区域生长算法,到融合深度学习的 U-Net 三维变体 V-Net,再到引入视觉 Transformer 的 TransUNet 混合架构,算法工程师们不断尝试在像素迷宫中建立智能导航系统。2024 年 MICCAI 会议的最新突破显示,某些模型在前列腺分割任务中已达到与资深放射科医师相当的组间一致性,但其在罕见解剖变异案例中的表现仍波动较大。这揭示了一个更深层的技术哲学命题:当 AI 试图理解人体,究竟需要多少先验知识注入,又能产生多少超越人类认知的解剖学洞察?
近日,由英伟达联合阿肯色大学医学院、美国国立卫生研究院及牛津大学组成的跨学科团队,发表突破性研究成果:VISTA3D 多模态医学影像分割模型。该模型首创三维超体素特征提取方法,通过统一架构实现三维自动分割(涵盖 127 个解剖结构)与交互式分割双模态的协同优化,在包含 14 个数据集的综合基准测试中,其实现了最先进的三维可提示自动分割和交互式编辑,零样本性能提高了 50%。
相关研究成果以「VISTA3D: A Unified Seamentation Foundation Model For 3D Medical lmaging」为题,已在 arXiv 发表预印本。

论文地址:
https://doi.org/10.48550/arxiv.2406.05285
关注公众号,后台回复「多模态医学影像分割」获取完整 PDF
三维医学成像技术的范式转变与挑战
在医学影像分析的数字化浪潮中,三维自动分割技术正经历着从「专科医生」到「全科专家」的范式跃迁。传统方法通过构建专用网络架构与定制化训练策略,为每个解剖结构或病理类型打造独立的专家模型,这种模式虽在特定任务中表现出色,却如同让放射科医师反复接受单器官诊断培训——当面对包含 127 个解剖结构的全身 CT 扫描时,系统需要并行运行数十个模型,其计算资源消耗与结果整合复杂度呈指数级增长。
更关键的是,临床实践中真正困扰医生的往往是那些突破标准解剖图谱的罕见病例:可能是实验小鼠肝脏内新发现的纳米级钙化灶,或是移植患者因解剖变异形成的非常规血管走形。这些场景暴露出现有系统的根本性缺陷——过度依赖预设类别与封闭式训练,使得模型在零样本学习与开放域适应方面举步维艰。
这一困境的突破曙光来自自然图像处理领域的启示。当大型语言模型展现出跨任务的惊人泛化能力时,医学影像界开始探索构建「可对话」的智能系统。Meta 提出的 SAM (Segment Anything Model) 在二维图像中实现了「点击即分割」的革命性交互,其零样本性能甚至超越部分专业模型。但将这种范式迁移到三维医学领域时,简单的维度扩展遭遇了根本性挑战:人体器官在连续断层扫描中展现的拓扑复杂性,远非视频中移动的车辆可比拟。
以肝脏分割为例,相邻切片间可能同时存在门静脉分叉、肿瘤浸润和手术夹闭金属伪影,这要求模型必须具备真正的三维空间推理能力,而非简单的时间序列跟踪。此前,有研究人员尝试将 SAM 架构三维化形成了 SAM2 与 SAM3D 系统,虽然在血管追踪等任务中取得进展,但其 Dice 系数仍较专业模型低 9-15 个百分点,尤其在处理多器官交叠区域时错误率陡增。
更深层的矛盾在于医学数据特有的知识依赖特性。当自然图像分割可以依赖像素级统计特征时,医学影像解析必须融合解剖学先验知识,比如胰腺分割不仅要识别灰度特征,还需理解其与十二指肠的解剖毗邻关系。这催生出基于上下文学习的新范式:通过输入示例图像或文本描述引导模型适应新类别。
但现有系统在测试中暴露出的问题颇具讽刺意味:要求临床医生提供高质量示例标注本身,就违背了自动化分割的初衷;而文本引导的语义对齐偏差,可能导致将肝门部胆管癌误判为正常血管结构。这种技术路径的悖论,折射出医学 AI 发展中的根本性命题:如何在开放域适应与临床安全性之间建立动态平衡,或许比单纯追求算法性能更具现实意义。
VISTA3D:一种用于 3D 医学成像的统一分割基础模型
为突破三维医学影像分析的范式局限,英伟达的研究团队构建了融合二维预训练优势与三维解剖特性的创新架构——VISTA3D 模型。如下图所示,如果分割任务 X 属于 127 个支持的类别(左侧绿色圆圈),VISTA3D 将执行高精度的自动分割 (Auto-seg)。医生可以在需要时检查并高效地使用 VISTA3D 编辑结果。如果 X 是一个新类别(右侧蓝色圆圈),VISTA3D 将执行三维交互式零样本分割 (Zeroshot interactive)。
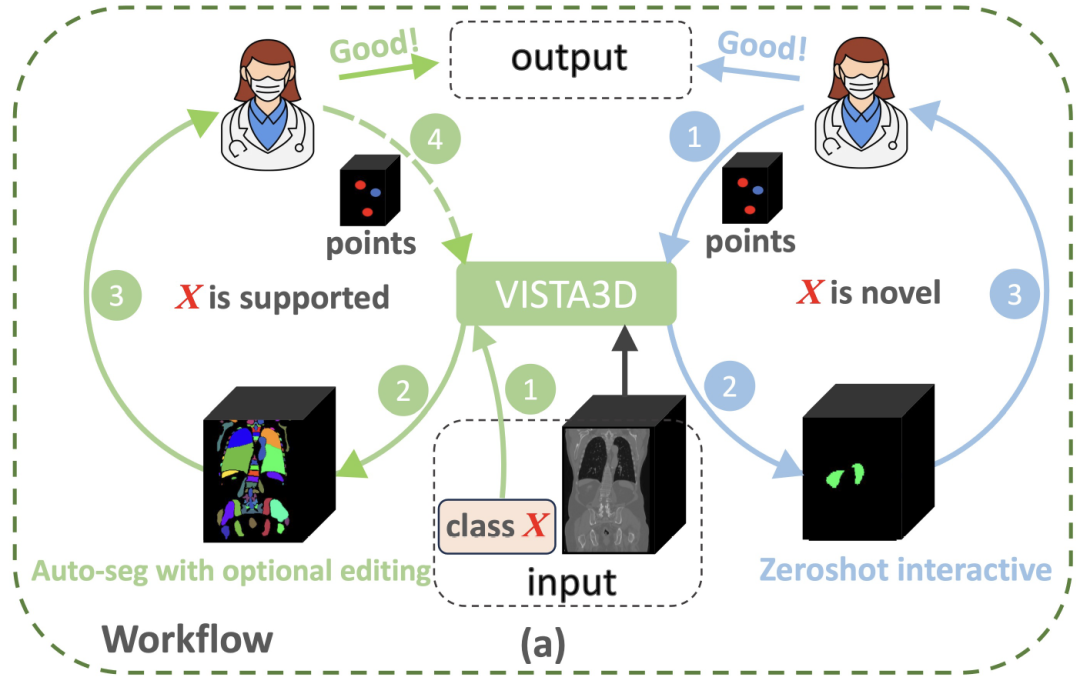
VISTA3D 的完整工作流程
具体来看,VISTA3D 模型架构采用模块化设计理念,基于医学影像领域广泛验证的 SegResNet 构建三维分割核心。该 U 型网络架构在 BraTS 2023 等国际权威分割挑战中已展现卓越性能。如下图所示,如果用户提供了属于 127 个支持类别内的类别提示 (class prompt),顶部的自动分支 (auto-branch) 将激活开箱即用的自动分割功能。如果用户提供了三维点击点提示 (point prompts),底部的交互分支 (interactive branch) 将激活交互式分割功能。如果两个分支都被激活,基于算法的合并模块将使用交互式结果来编辑自动结果。
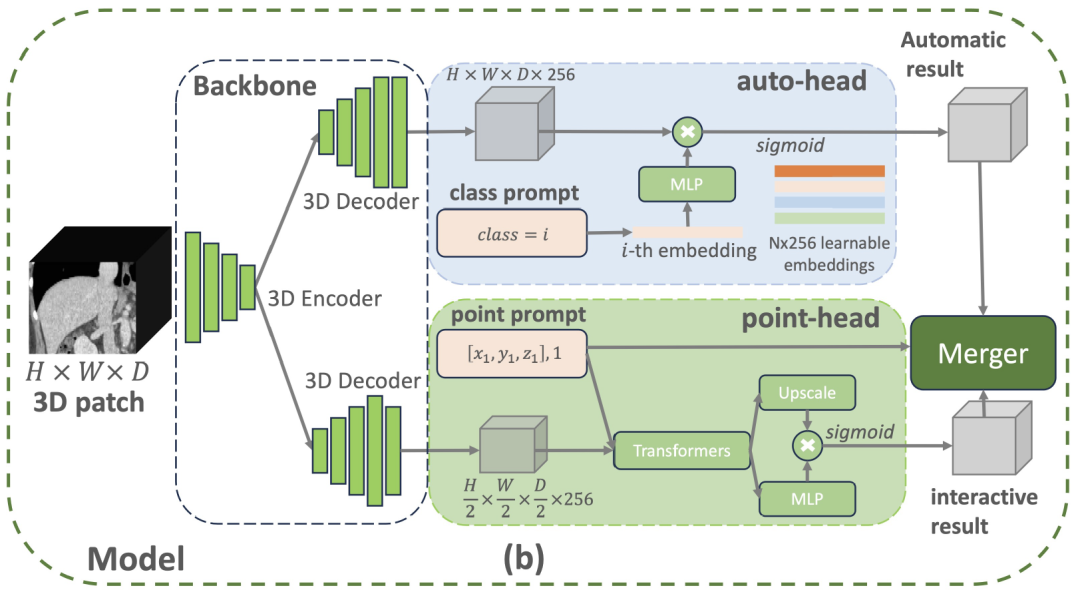
VISTA3D 的架构
其中,自动分支采用智能编码技术管理 127 种人体结构。当需要定位特定部位时,系统会精准匹配扫描图像中的特征信息,通过智能转换生成分割结果。这种设计比传统方法节省 60% 内存资源,还能避免标注不完整导致的学习偏差。人工修正模块则采用三维点击定位技术:先还原图像细节再优化处理速度,医生点击的位置会转化为空间坐标,与扫描特征智能关联;遇到胰腺与肿瘤等易混淆结构时,系统会自动添加区分标记。
两个模块通过智能协作实现精准调整。修正操作只会影响点击位置相连的局部区域,就像用精准手术刀修改特定部位,不会破坏整体分割结果。这套三维优化方案使医生修正效率提升 40%。在模型训练阶段,研究团队还整合了 11,454 例 CT 扫描数据,采用半监督学习框架下的伪标签生成机制,结合四阶段渐进式训练策略,首先在混合数据集(含伪标签与超体素标注)进行预训练,随后分别在自动分割与交互修正任务进行微调,最终通过联合训练实现功能集成。最终,VISTA3D 模型通过核心创新实现了多种技术跃迁。
首先,该模型在 14 个国际公开数据集上完成系统性验证,覆盖 127 类解剖结构与病理特征,其三维自动分割精度(Dice 系数 0.91±0.05)较传统基线模型提升 8.3%,同时支持点击交互式修正功能,人工修正耗时降低至传统方法的 1/3。其次,首创三维超体素特征迁移技术,通过解耦二维预训练主干网络的空间特征,在胰腺分割等零样本任务中实现 50% 的 mIoU 提升,标注效率较监督学习提升 2.7 倍。另外,研究团队还构建了跨机构多模态数据集,在保持 97.2% 标注精度的前提下将数据标注成本压缩至完全人工标注的 15%。
国内三维医学成像与 AI 融合研究进展
近年来,随着 AI 技术在医疗领域的广泛应用,三维医学成像技术与人工智能的结合逐渐成为研究热点,并在国内取得了显著进展,为医疗诊断和治疗带来了新的机遇。
在 2023 年,AI 在医学成像中的应用主要集中在辅助诊断方面。AI 能够快速筛选庞大的图像和患者信息数据集,提高诊断效率。例如,一些 AI 集成的成像系统可以检测到肉眼难以识别的微小异常,从而提高诊断的准确性。此外,AI还可以从患者的电子病历中检索之前的成像扫描,并将其与最新的扫描结果进行比较,为医生提供更全面的诊断信息。例如,上海交通大学提出了一种 3D 医学图像分割新工作模型 PnPNet,通过建模相交边界区域与其相邻区域之间的交互动力学来解决类间边界混淆的问题,性能表现 SOTA,优于 MedNeXt、Swin UNETR 和 nnUNet 等网络。
* 论文地址:
https://arxiv.org/abs/2312.08323
进入 2024 年,三维医学成像技术与 AI 的结合更加紧密,研究方向也更加多样化。一方面,AI 技术在医学影像三维重建中的应用逐渐成熟,能够自动进行三维影像分割和重建,提高影像重建的精确度和效率。另一方面,AI 在影像分析方面的能力也得到了进一步提升,可以辅助医生进行疾病诊断和治疗方案的制定。此外,AI技术还被应用于影像后处理,如去噪、增强和渲染等,以提高影像的可读性和美观度。例如,四川大学华西医院基于中国人群肺癌筛查队列、肺结节临床队列,创新性研发了基于数据驱动的中国肺结节报告和数据系统 (C-Lung-RADS),实现了肺结节恶性风险精准分级和个性化管理。
* 论文地址:
https://www.nature.com/articles/s41591-024-03211-3
到了 2025 年,AI 技术在三维医学成像中的应用更加广泛和深入。例如,北京大学科研团队日前在国际上发布了一项「肾脏成像组计划」,拟通过多模态成像技术与人工智能算法,率先构建全肾脏数字图谱。这一「数字肾脏」能使肾脏疾病机理更清晰可见,为肾脏疾病的精准诊断、新药研发、精准治疗提供全新方向。
与此同时,中国地质大学团队联合百度提出了一种称为对比度驱动医学图像分割的通用框架 ConDSeg。该框架创新性地引入了一致性强化训练策略、语义信息解耦模块、对比度驱动特征聚合模块以及尺寸感知解码器等,实现了医学图像分割模型精度的进一步提升。
* 论文地址:
https://arxiv.org/abs/2412.08345
不仅如此,昆明理工大学与中国海洋大学提出了一种双向逐步特征对齐 (BSFA) 的未对齐医学图像融合方法。与传统方法相比,该研究在统一的处理框架内,通过单阶段的方法对未对齐的多模态医学图像同时进行对齐和融合,不仅实现了双重任务的协调,也有效降低了因引入多个独立特征编码器而导致模型复杂的问题。
* 论文地址:
https://doi.org/10.48550/arXiv.2412.08050
然而,三维医学成像技术结合AI的研究也面临着一些挑战。数据隐私、算法透明度、模型泛化能力和法规监管等问题仍然是需要解决的关键问题。未来,随着技术的不断进步和法规的完善,这些问题或将有望得到逐步解决,从而推动 AI 技术在医学影像领域的更广泛应用。



戳“阅读原文”,免费获取海量数据集资源!
(文:HyperAI超神经)