


北京时间 3 月 26 日凌晨,谷歌发布了号称最强推理模型的 Gemini Pro 2.5,而在谷歌之前,OpenAI 率先开了场直播,发布了 GPT-4o image generation,图像生成技术模型。有趣的是,最近半年时间里,基本上谷歌的每次发布都会与 OpenAI 的直播“撞车”。
OpenAI 表示:“从今天开始,OpenAI 将新的图像生成功能直接集成到 ChatGPT 中——该功能被称为‘ChatGPT 中的图像’。用户现在可以使用 GPT-4o 在 ChatGPT 内部生成图像。”

此初始版本仅专注于图像创建,并将在 ChatGPT Plus、Pro、Team 和 Free 订阅层中提供。
值得注意的是,GPT-4o 图像生成标记器词汇量(实际上是用于表示文本的唯一整数的数量)已从 GPT-4 和 GPT-3.5 的约 10 万个增加到约 20 万个。古吉拉特语输入使用的标记减少了 4.4 倍,日语减少了 1.4 倍,西班牙语减少了 1.1 倍。以前,除英语以外的其他语言在提示中可以容纳多少文本方面会付出实质性的代价。
同样值得注意的是价格。OpenAI 声称与 GPT-4 Turbo 相比,价格降低了 50%。更直观的对比是, GPT-4o 成本恰好是 10 倍 GPT-3.5;4o 是 5 美元 / 百万输入 token 和 15 美元 / 百万输出 token。3.5 是 0.50 美元 / 百万输入 token 和 1.50 美元 / 百万输出 token。
价格下降尤其引人注目,因为 OpenAI 承诺也将向免费 ChatGPT 用户提供该模型——这是他们第一次直接向非付费客户提供“最佳”模型。
OpenAI 研究负责人 Gabriel Goh 在接受媒体采访时表示:“该模型比以前的模型有了很大的改进”,并补充说,团队使用了 GPT-4o“全模态”——一种可以生成任何类型数据(如文本、图像、音频和视频)的模型——作为该功能的基础。
OpenAI 在公告中表示,GPT-4o 图像生成功能具有以下特点:
-
精准渲染图像内文字,能够制作 logo、菜单、邀请函和信息图等;
-
精确执行复杂指令,甚至在细节丰富的构图中也能做到;
-
基于先前的图像和文本进行扩展,确保多个交互之间的视觉一致性;
-
支持各种艺术风格,从写实照片到插图等。
先来感受下生成图片的效果怎么样。
OpenAI 在官方示例展示时放出了一张女士背对着镜头在白板上写字的图片。

图片看起来就是很日常的生活照片,但实际上,它是由 GPT-4o 生成的 AI 图片,OpenAI 给出的提示词如下 :
“在俯瞰海湾大桥的房间中,使用手机拍摄玻璃质地白板获得的宽幅图像。画面中一位女性正在写字,身着带有显眼 OpenAI 标志的 T 恤。笔迹自然且略带凌乱,白板上投射出摄影师的身影。”
接下来第二张图片转了人物朝向,以摄影师的自拍角度,画面中的女性转向与他击掌,生成的图像还是完全看不出出自 AI。

还能生成四格连环画,边框与画面边缘间注意留白。提示词如下:
“一只小蜗牛身在华丽的汽车展厅柜台上,推销员俯下身来才能看到他。特定镜头中,蜗牛表情严肃,说‘我想要你们最快的跑车……还得在车门、引擎盖和车顶位置画上大写的「S」。’ 销售员挠挠头,‘呃……当然没问题。不过为什么是「S」?’ 画面切换到时一辆红色汽车在高速公路上呼啸而过,车身上写满巨大的「S」。路旁的人们指指点点,笑着说,‘WOW! LOOK AT THAT S‑CAR GO!’”

生成一张详细解释牛顿棱镜实验的信息图。
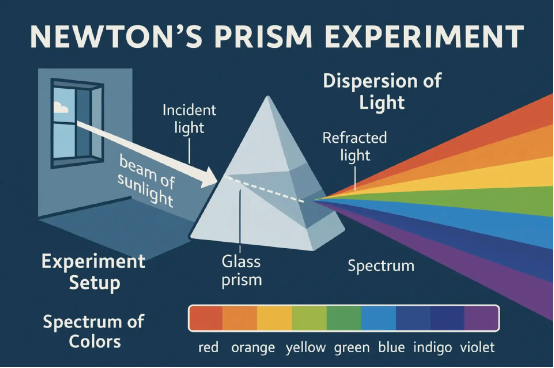
然后,现在生成一个人在华盛顿广场公园的一张图形咖啡桌旁,用笔记本绘制这张图的第一人称画面。

然后,现在在同一场景下,显示难掩兴奋的年轻牛顿坐在桌旁,手持棱镜演示实验结果,注意画面中不要出现笔记本。

据 OpenAI 官方说明,GPT-4o 在多个方面相较于过去的模型进行了改进:
-
更好的文本集成:与过去那些难以生成清晰、恰当位置文字的 AI 模型不同,GPT-4o 现在可以准确地将文字嵌入图像中;
-
增强的上下文理解:GPT-4o 通过利用聊天历史,允许用户在互动中不断细化图像,并保持
-
改进的多对象绑定:过去的模型在正确定位场景中的多个不同物体时存在困难,而 GPT-4o 现在可以一次处理多达 10 至 20 个物体;
-
多样化风格适应:该模型可以生成或将图像转化为多种风格,支持从手绘草图到高清写实风格的转换。
OpenAI 表示,从第一幅洞穴壁画到现代信息图,人类一直在使用视觉图像进行交流、传达与分析。如今的生成模型可以呈现出超现实、令人惊叹的场景,但却难以处理人们用于分享和创建信息的实用性图像。事实上从徽标到图表,基于共同语言和经验相关符号的图像往往可以传达精确的表达含义。
GPT-4o 图像生成善于准确地呈现文本、精确遵循提示词,并运用 4o 固有的知识库与聊天上下文——包括直接转换上传的图像,或将其作为视觉创作灵感。这些功能可轻松创建大家设想的图像,帮助用户通过视觉效果实现顺畅交流,并将图像生成真正转化为具备精确性与强大现实意义的实用性工具。
利用在线图像与文本内容共同训练模型,GPT-4o 图像生成不仅学习到图像与语言的内部关联,还掌握了二者之间的对应关系。结合积极的后训练设计,生成模型获得了令人惊喜的视觉流畅性,能够生成高度实用、一致且具备上下文感知特征的图像。
正所谓一图胜千言,但有时在正确位置添加寥寥数语即可显著提升图像的表达效果。4o 将精确符号与图像融合起来,使得图像生成真正具备了视觉交流属性。
OpenAI 放出了一些官方示例。
创建一张逼真的图像,画面中两名 20 多岁的女巫(一名有着灰色挑染头发,另一名有着赤褐色波浪长发)正在阅读路牌。
提示词:
纽约威廉斯堡一条街道上,路牌中展示大量详尽的街道标志(例如街道清扫时间、停车许可要求、车辆分类、拖车规则),其间还有一些架空信息(以合法的街道标记形式呈现),如“C 区禁止停泊女巫扫帚”、“仅允许魔毯卸货(不超过 15 分钟)”以及“仅允许驯鹿凭许可临停(12 月 24 日至 25 日),违规者将被列入淘气名单。”路标位于街道右侧,内容不可重复,标志必须真实还原。 人物:一名女巫手持扫帚,另一名抱着卷起的魔毯。二人在前景中,背对画面,头部稍微倾斜并认真观看路牌。背景到前景的构图:街道 + 停放的车辆 + 建筑物——>路牌——>女巫。人物必须在距离镜头最近的位置。

如今图像生成已经成为 GPT-4o 中的原生功能,因此用户可以通过自然对话实现图像内容优化。GPT-4o 可以在聊天环境中基于图像和文本构建而成,确保内容始终保持一致。例如,如果用户正在设计一位电子游戏角色,那么在持续改进与试验过程中,该角色的外观将在多轮迭代中保持一致。
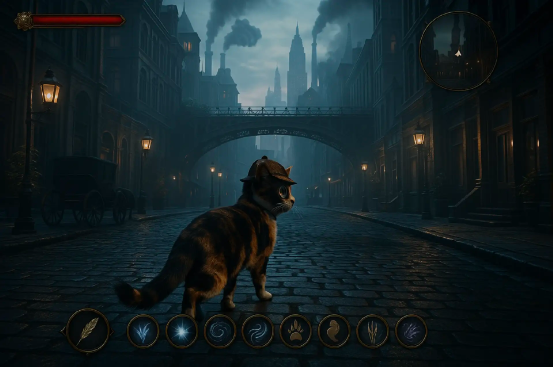
在电子游戏场景中,参考输入的小猫图像,为小猫添加一顶侦探帽和一副单片眼镜。


将画面转化为使用 4k 游戏引擎制作的 3A 电子游戏风格画面,并添加用户界面元素以呈现类似 RPG 游戏的叠加图层。顶部有生命栏和小地图,下方则是风格一致的咒语图标。

将画面更新为 16:9 横向图像,在 UI 中添加更多咒语元素,并缩小生成的小猫以通过第三人称视角观看其穿过蒸汽朋克风格的曼哈顿街头。注意使用 3A 游戏中常见的漂亮对比与光照效果,使用冷色调。
创建界面,当玩家打开菜单时显示小猫的角色资料和装备,另一页显示当前任务(任务内容应与图像中呈现的世界观保持关联)。
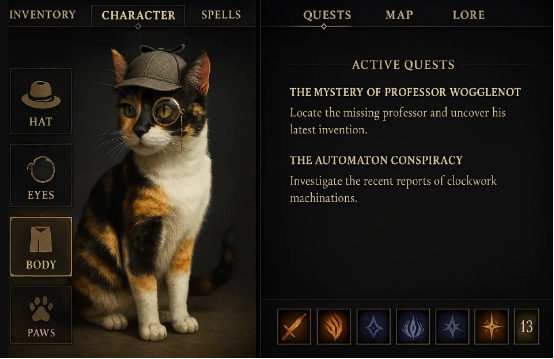
GPT-4o 的图像生成功能可遵循详尽提示词并始终关注细节。其他系统在处理包含 5 到 8 个对象的画面时往往表现不佳,而 GPT-4o 能够处理多达 10 到 20 个不同对象,同时更好地控制各对象、其特征及彼此关系之间的紧密绑定。
生成一幅正方形图像,包含一个 4 行、4 列的网格,共包含 16 个对象,背景为白色。从左至右、从上到下,各对象依次为:
-
一颗蓝色星星
-
红色三角形
-
绿色正方形
-
粉色圆形
-
橙色沙漏形
-
紫色无穷符号
-
黑白圆点领结
-
扎染纹理的“42”数字
-
一只戴着黑色棒球帽的橙色猫
-
一张带有宝箱的地图
-
一双大眼睛
-
竖起大拇指的表情符号
-
一把剪刀
-
一只蓝白相间的长颈鹿
-
用草体书写的“OpenAI”单词
-
一道彩虹色闪电

通过在训练中纳入反映多种图像风格的素材,4o 模型能够逼真地生成或转换图像。
一张狗仔队偷拍风格的照片,画面中卡尔·马克思匆匆走过美国购物中心的停车场,他回头一看,脸上带着惊恐的表情,不想被偷拍骚扰。他手里抓着几个装满奢侈品的闪亮购物袋。他的外套在风中飘扬,其中一个袋子在摆动,好像他正在大步走。模糊的背景,汽车和发光的购物中心入口,以强调运动。相机的闪光灯部分曝光过度,给人一种地下小报的感觉。

尽管生成的图片生动又逼真,但 OpenAI 也坦言,这些模型并不完美,目前也发现其存在的诸多局限性。OpenAI 将在先期发布之后,通过不断改进来解决这些问题。
在接受媒体采访时 Goh 也提到,“归根结底,没有一个系统是完美的,但我们正在不断改进我们的保障措施,我们认为这是一个起点。ChatGPT 生成的所有图像都有一个共同点,那就是用户拥有它们,并可以在我们的使用政策范围内随意使用它们。”
此外,OpenAI 支持生成公众人物形象和不符合历史但用户指定的图片。


此次更新,OpenAI 比以往更加关注安全性。
OpenAI 称,“根据模型规范,我们希望通过支持游戏开发、历史探索和教育等具有现实价值的用例以最大限度提升创作自由,同时保持严格的安全标准。换言之,阻止违规请求是保障制度落实的必要前提。我们正努力通过以下手段保障安全且高度实用的内容,同时支持用户借助创意广泛表达自己的灵感与思路。”
首先,通过 C2PA 与内部可逆搜索进行溯源。目前,生成的所有图像均带有 C2PA 元数据,用于注明图像来自 GPT-4o 以保证公开透明。此外,OpenAI 还构建了一款内部搜索工具,其使用生成技术属性以帮助验证内容是否来自我们的模型。
其次,OpenAI 称会坚决屏蔽不良内容。将继续阻止可能违反内容政策的生成图像请求,例如儿童性虐待素材与深度伪造色情图像。对于上下文内的真人图像,OpenAI 会加强对于所能创建图像的限制,并对裸露及暴力画面采取极其严格的处理措施。当然,安全升级永远不会结束,也将成为持续投资的重要领域。
第三,使用推理增强安全性。OpenAI 已经训练了一套推理大模型,负责根据人类编写的可解释安全规范识别并解决政策中的歧义。结合 ChatGPT 与 Sora 所使用的多模态安全技术,得以根据现有政策灵活调整输入文本与输出图像。
但目前尽管 4o 图像生成技术在性别表现的多样性上超过了 DALL·E 3,但输出结果仍然主要偏向男性主体。因此,OpenAI 表示其未来的工作将着重于提高数据均衡性,让模型更加公平。
作为 ChatGPT 中的默认图像生成工具,4o 图像生成功能从即日起开始向 Plus、Pro、Team 及 Free 用户全面开放。Enterprise 及 Edu 访问权限将后续开放。Sora 也可享受到此次功能升级。对于希望继续使用 DALL-E 的用户来说,则可通过专门的 DALL-E GPT 访问这项新功能。
开发人员很快就能通过 API 使用 GPT-4o 生成图像功能,访问权限将在未来几周内开放。
OpenAI 表示,整个图像创建与自定义过程,就像与 GPT-4o 聊天一样简单——只需描述你的需求,包含画面比例、使用十六进制代码的精确色彩或透明背景等细节即可。由于此模型能够生成涉及更多细节的图像,因此渲染时间可能更长,最多可能达到 1 分钟。
(文:AI前线)