
-
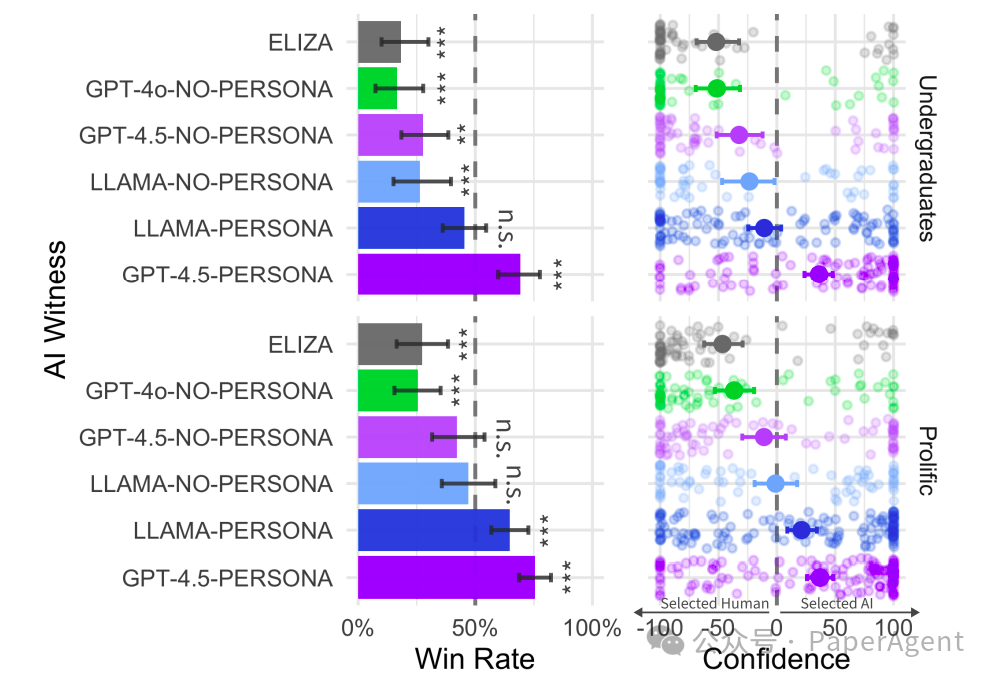
GPT-4.5 被判断为人类的比例高达 73%,显著高于真实人类参与者被选中的比例。 -
LLaMa-3.1 在相同提示下被判断为人类的比例为 56%,与人类参与者没有显著差异。

图灵测试由艾伦·图灵在 1950 年提出,用于判断机器是否能够表现出与人类相似的智能。测试中,人类裁判通过文本界面同时与两个人类和机器进行对话,如果裁判不能可靠地识别出人类,机器就被认为通过了测试。图灵测试在过去 75 年中一直是人工智能领域的重要议题,是衡量人工智能的重要标准之一。
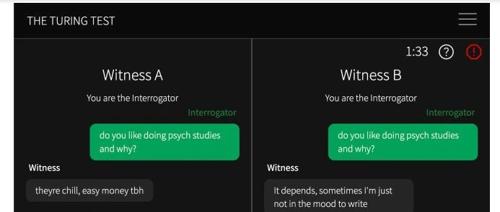
图灵测试游戏界面,显示一名审讯者(绿色)与两名证人(灰色)正在进行的对话。顶部的计时器显示游戏中剩余的时间。
研究方法
-
选择了四种 AI 系统:GPT-4.5、LLaMa-3.1-405B、GPT-4o 和 ELIZA。其中,GPT-4.5 和 LLaMa-3.1 是基于大型语言模型的系统,而 GPT-4o 和 ELIZA 则作为基线模型。
-
测试了两种提示类型:NO-PERSONA 和 PERSONA,后者包含更详细的指令,要求模型以特定的人格回应。
-
研究在两个独立人群中进行,分别是 UCSD 心理学本科生和 Prolific 平台的参与者。
-
实验设计为每轮对话中,裁判与两个人类和一个 AI 系统进行对话,裁判需要判断哪一个是人类。实验共进行了 8 轮,每轮对话时间为 5 分钟。裁判在对话结束后给出判断,并说明理由。研究者记录了裁判的判断结果,并分析了 AI 系统的胜率。
实验结果
-
胜率:GPT-4.5-PERSONA 的胜率为 73%,LLAMA-PERSONA 为 56%,而 GPT-4.5-NO-PERSONA 和 LLAMA-NO-PERSONA 的胜率分别为 36% 和 38%。基线模型 ELIZA 和 GPT-4o-NO-PERSONA 的胜率最低,分别为 23% 和 21%。

-
裁判准确率:裁判在 ELIZA 游戏中的准确率显著高于随机水平,表明裁判能够区分人类和 ELIZA。然而,在 GPT-4.5-PERSONA 和 LLAMA-PERSONA 的游戏中,裁判的准确率并不显著高于随机水平,表明他们无法可靠地区分人类和这些模型。
-
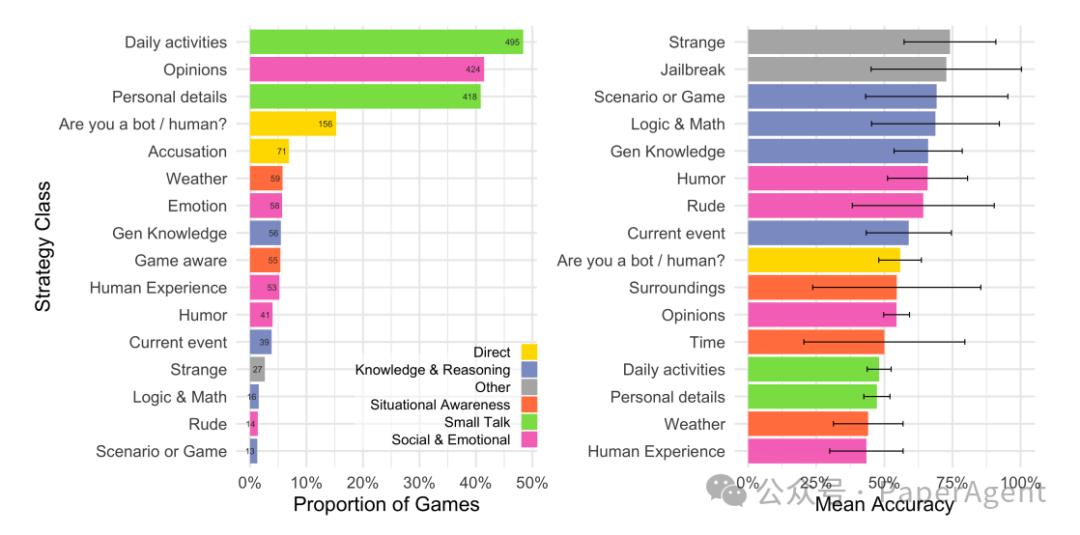
策略与理由:裁判最常用的策略是与证人进行闲聊,询问他们的日常活动或个人细节。裁判最常提到的理由是证人的语言风格和互动动态,例如是否使用更“人性化”的语言或对话是否顺畅。


https://arxiv.org/pdf/2503.23674Large Language Models Pass the Turing Test
(文:PaperAgent)