
MCP 最近这么火,你还不知道它是啥吗?别慌,动手实战一番就包你明白了。
你有没有想过让大模型自动给我们搜索、下载、解读文献,一条龙服务?即便像 Deep Research 之类的服务也主要是帮你搜索和整合资源,但不给你下载资源对不。
实际上,是可以手撸一个智能体帮我们干这项大工程的。只是现在不是流行 MCP 嘛,咱们也想通过这种方式来建一个。
马上给你安排上。
本篇将以 arxiv 为例,目标是让你发个话,智能体就帮你搜索、下载文献,甚至解读一条龙到家。
为了照顾不同需求,咱这里贴心地实现了两套方案,
-
Trae CN + Cline,功能强大
-
Cherry Studio,容易上手
当然,如果你喜欢的话,也不拦着你直接用 Python 开干。
1、MCP
这个概念最近很热,相信大家都见过。这里简要地作个解释,毕竟本篇的主旨是在于动手实践。
你别看网文一篇一篇,不如跟着本篇撸一撸,你就真刀真枪见识过了。
当然,概念了解下还是有必要的。先看一个图,心急的话也可以跳过此图看下面的大白话。
MCP 作为「模型上下文协议」,可以看成专门为 AI 模型设计生态系统服务,它通过一个标准化的协议来管理和交换 AI 模型所需的各种信息,从而实现与各种外部服务和数据源的无缝集成。
用大白话来说,MCP 就像是 AI 模型(比如 DeepSeek、Gemini 等)的「超级翻译官」和「万能助手」。
我们不妨想象一下,AI 模型是个很厉害的专家,但是它自己只会说一种「AI 语言」。它需要跟各种网站、数据库、工具等外部世界打交道才能完成任务。
-
翻译官: 这些「外部世界」说的都是不同的「外语」,即各种不同的数据格式和通信方式。MCP 就负责把 AI 模型说的话翻译成这些外语,也把这些外语翻译成 AI 模型能听懂的话。这样,AI 模型就不用学那么多外语了,只需要跟 MCP 说就行。
-
万能助手: AI 模型有时候需要很多信息才能做好一件事,就像做菜需要菜谱、食材、调料一样。MCP 就负责把 AI 模型需要的所有信息(比如要查的资料、要用的工具、之前的聊天记录等等)都准备好,打包成一个大礼包(上下文),交给 AI 模型。这样,AI 模型就能直接开始工作。
举个例子:
你问 DeepSeek:杭州今天天气怎么样?
DeepSeek 自己没这项功能啊,咋办?它通过 MCP 获知提供这项功能的服务,然后使唤它查询外部天气预报网站,得知今天杭州的天气情况,再将数据整理好,最后给你答案:杭州今天晴,最高 27 度。
所以,MCP 的好处是:
-
简单: AI 模型不用学那么多外语,不用操心那么多杂事,只需要跟 MCP 打交道。 -
方便: 要加新的功能,比如查天气、订机票、下载文献等,只需要让 MCP 学会跟新的外部世界打交道就行,不用改 AI 模型本身。 -
整洁: MCP 把所有乱七八糟的信息都整理好,AI 模型用起来更顺手。
总之,MCP 就是一个让 AI 模型更方便、更强大、更容易跟各种服务和数据打交道的「中间人」。
这时候可以品一下这个图,
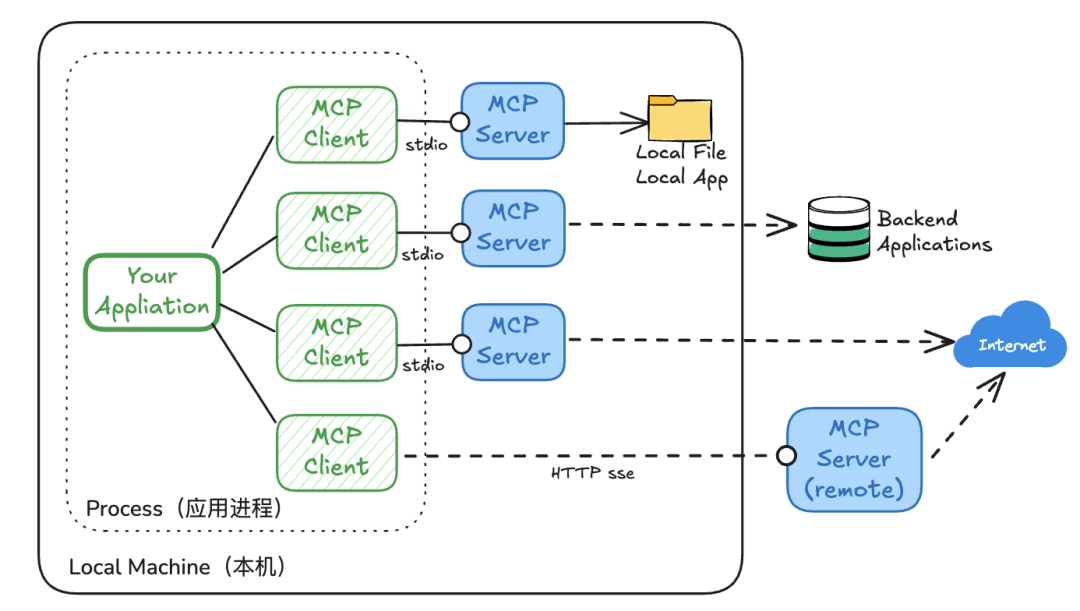
2、安装服务
回到主题,我们的目标是自动给咱从 arxiv 上下载文献,那就先搜一下提供这个功能的 MCP 服务器。
找到两个,一个如下图所示,但感觉它主要是搜索,貌似不提供下载业务。
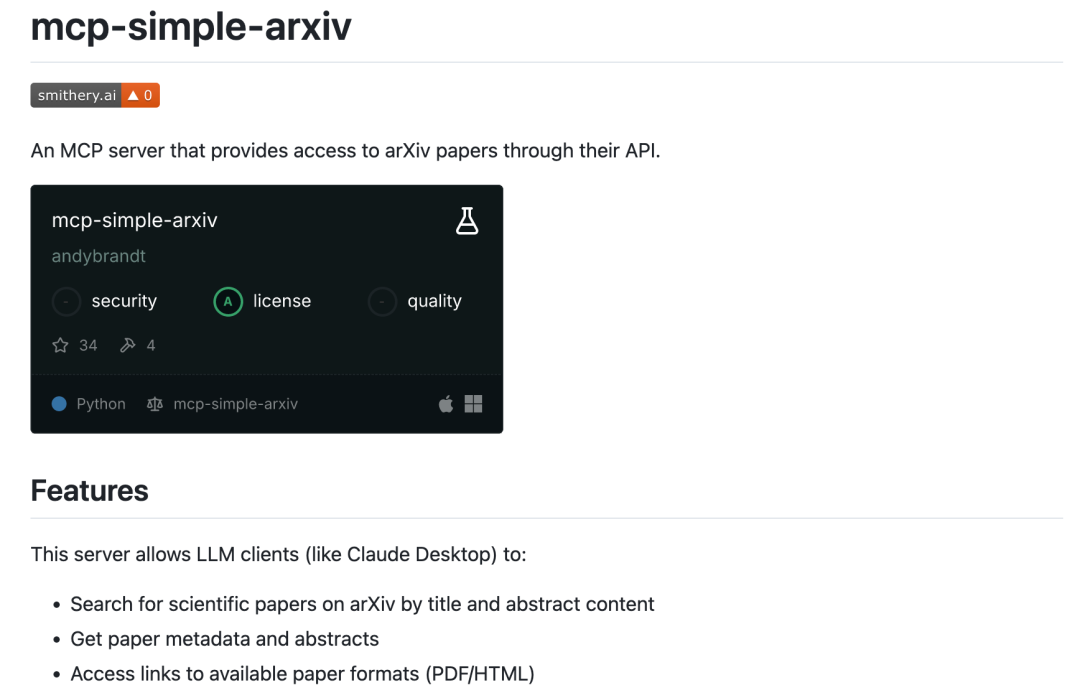
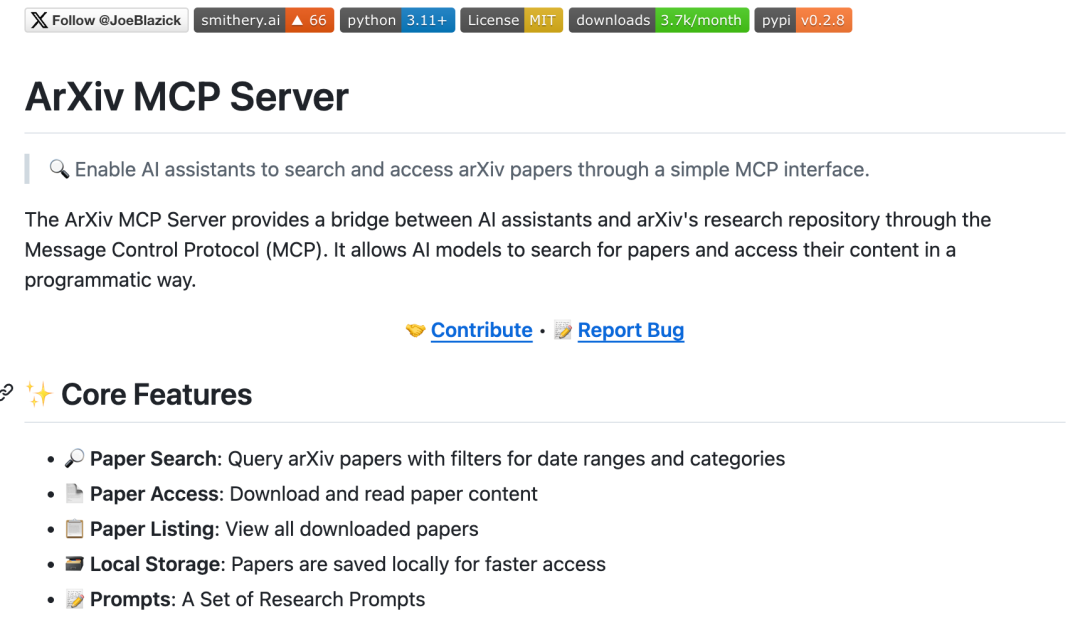
另一个见下图,看起来它是能够下载文献的。这下省事了,必须给一个大赞。
本人用的是 mac,下面的安装流程也是针对它而言。因为手头没有 Windows 电脑,稍微有点差异吧,但问题应该不大,稍微捣鼓一下肯定没问题。
-
安装第一个比较方便,用命令 pip install mcp-simple-arxiv即可; -
用 brew install uv先安装uv,然后用命令uv tool install arxiv-mcp-server安装第二个。
顺利的话,很快就搞定啦。主要一点,你安装过 Python,就方便了。
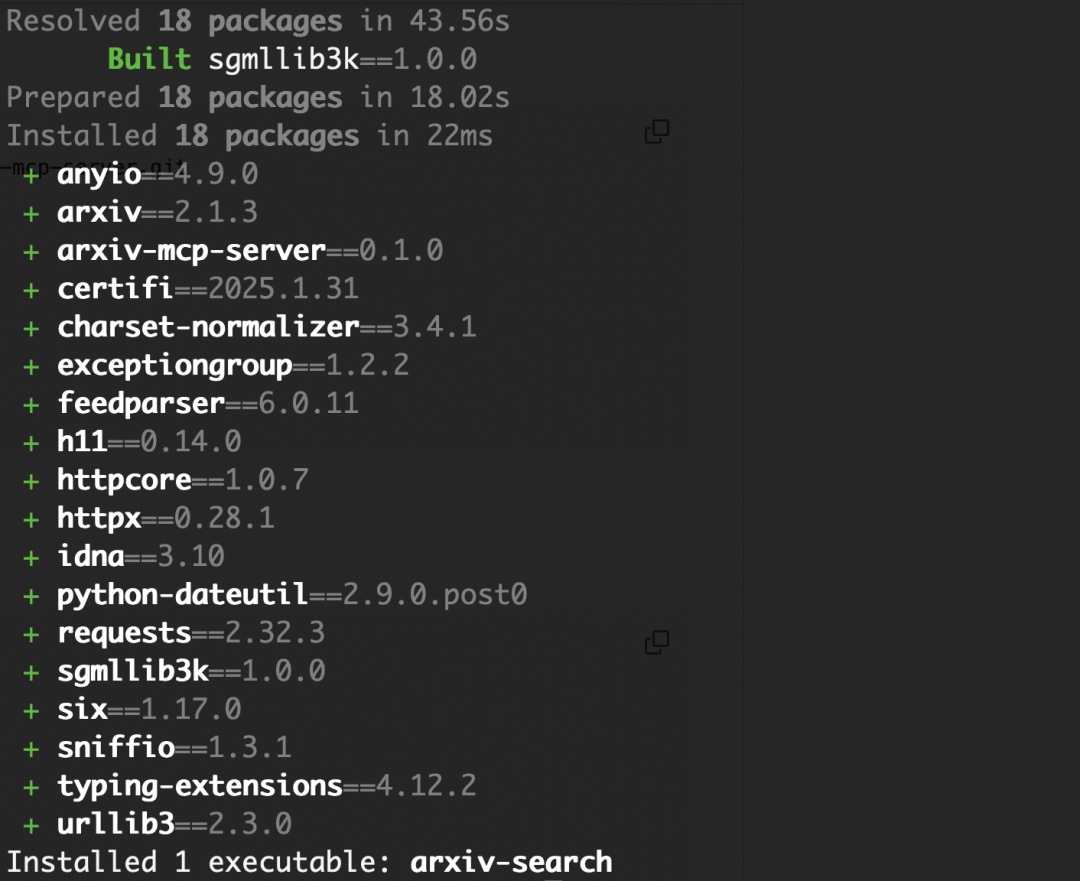
然后就是在 Cline 里配置,可以用 VS Code 或者 Cursor、Windsurf 之类的。
此处我们用国货 Trae 的国内版,安装插件 Cline 咱就略过了,直接打开 Cline,点击 MCP 服务器。
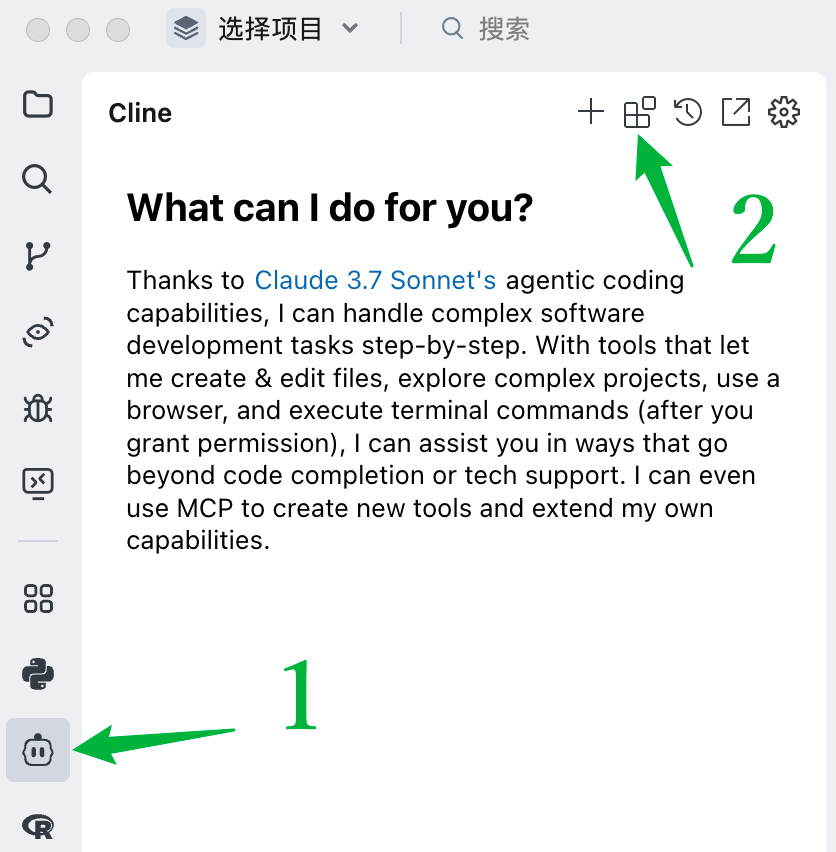
然后,点击左侧底部的 Configure MCP Servers,像右侧那样填写,然后看到灯绿就算配置好了。
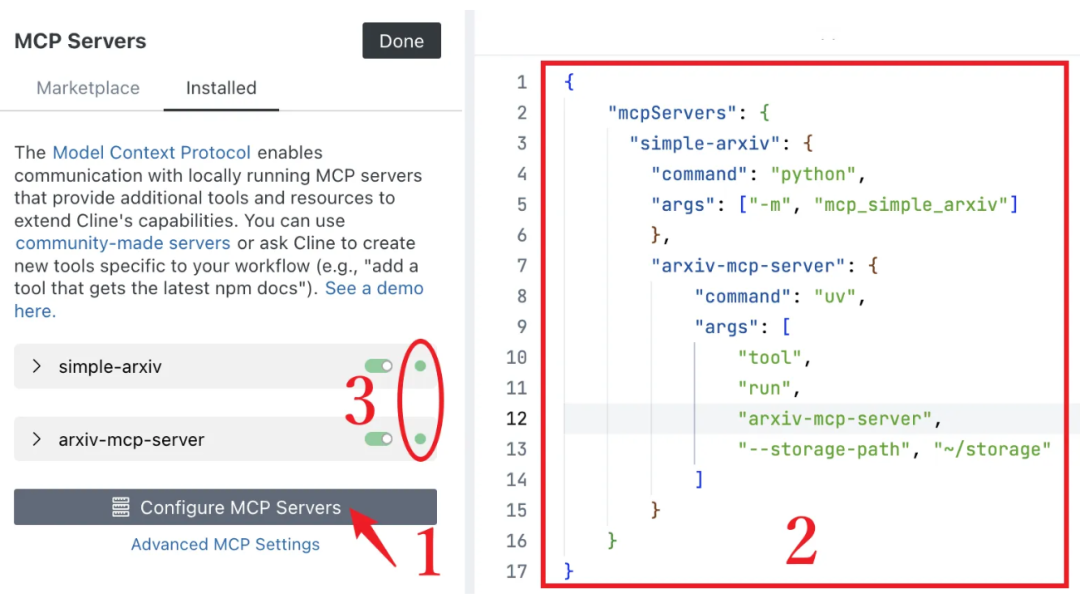
在 Cline 中提供了两种与大模型的交互模式,计划模式(Plan)和执行模式(Act),分别负责智能规划任务和高效执行任务。
3、设置大模型
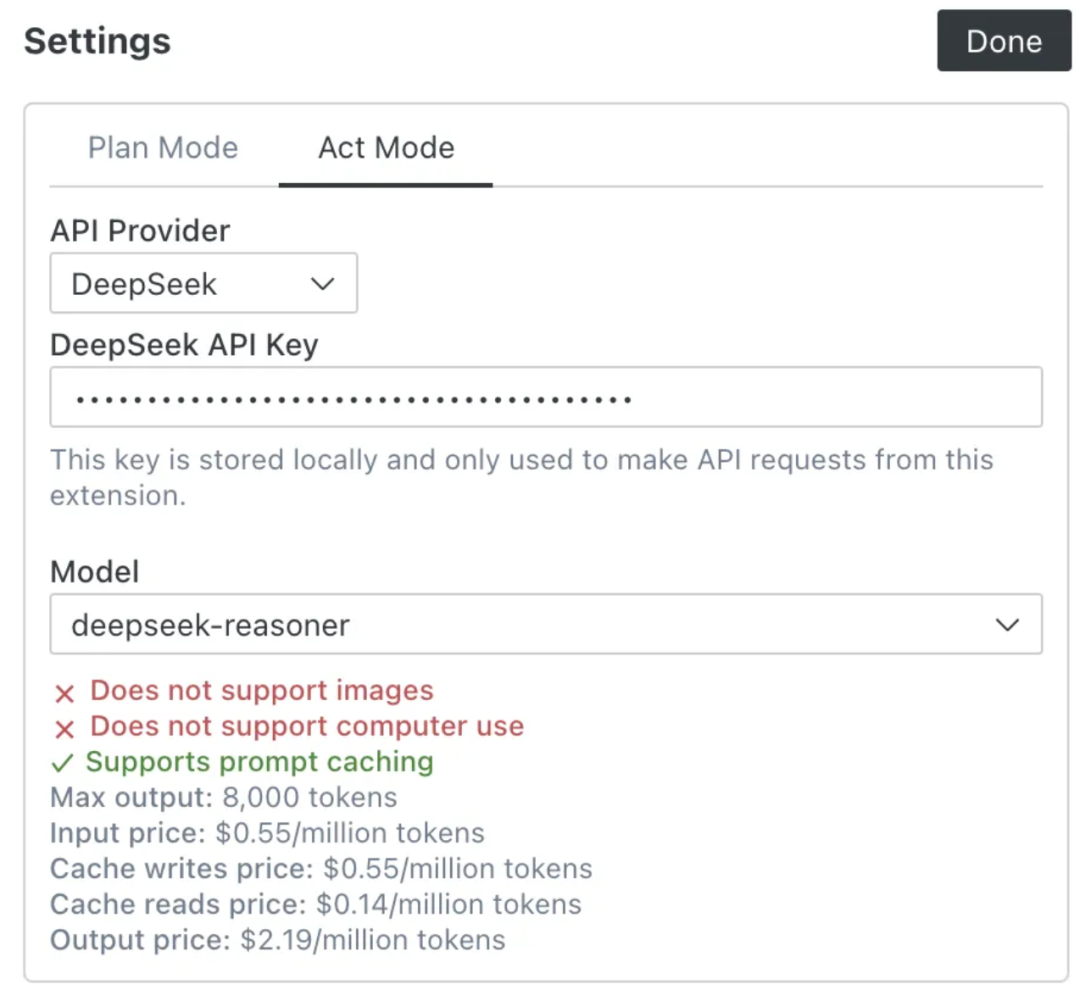
别忘了在 Cline 里选择大模型!注意,这里需要大模型的 API Key。你可以让 plan 和 act 使用同一个模型,或者让它们分别使用不同模型。比如一个用 deepseek-chat,另一个使用 deepseek-reasoner,像下面这样。
4、论文智能体
好了,现在就是整装待发的状态了。
Cline 默认在左侧,如果你习惯右侧开车的话,像下面这样点击一下即可发射到右侧。
左侧关掉,就可以右侧开车了。
给大模型下达命令:帮我搜一下扩散模型和大语言模型相结合的最新论文。
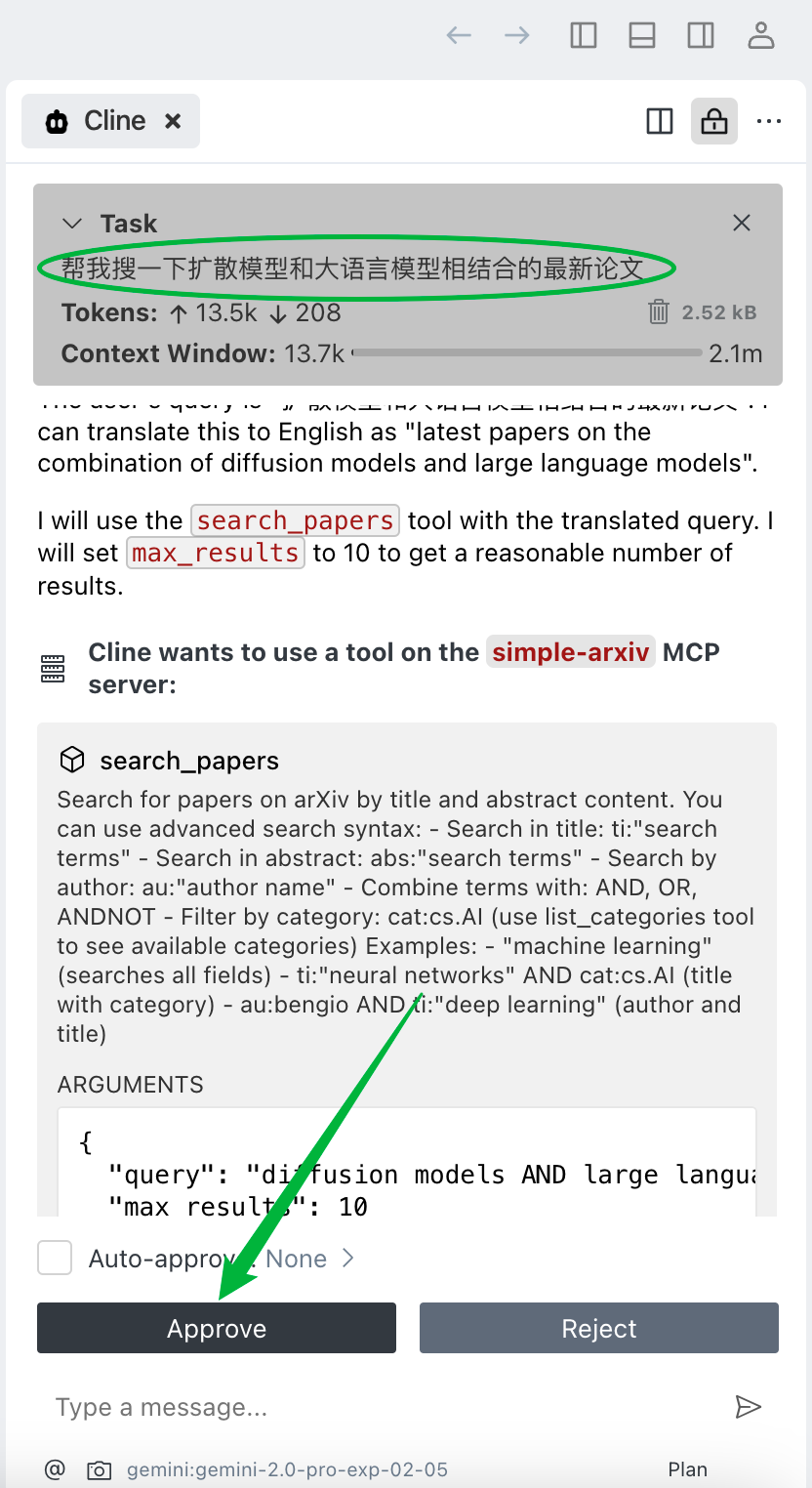
Gemini 调用 simple-arxiv 搜了 10 篇论文,

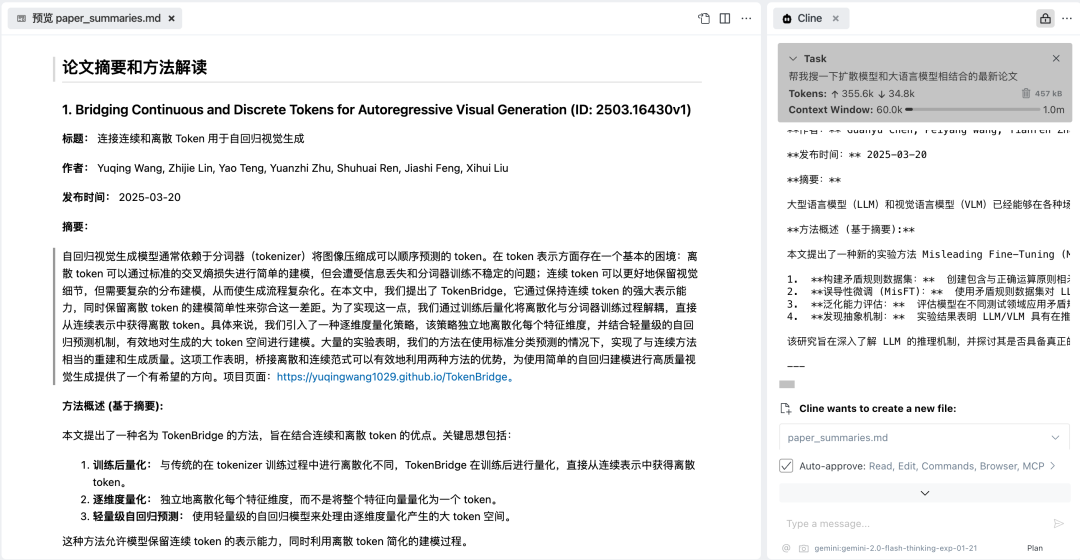
继续下命令:把这些论文的摘要和方法概要用中文解读一下,然后存放到一个 Markdown 文件中。
稍等一会儿,左侧就自动出现一个 Markdown 文件,里面就是摘要和对方法的简要解读。
下载论文
接下来,我们让它下载论文。你会发现,这时它会自动调用第二个服务,就是 arxiv-mcp-server。因为第一服务并没有提供下载业务嘛。
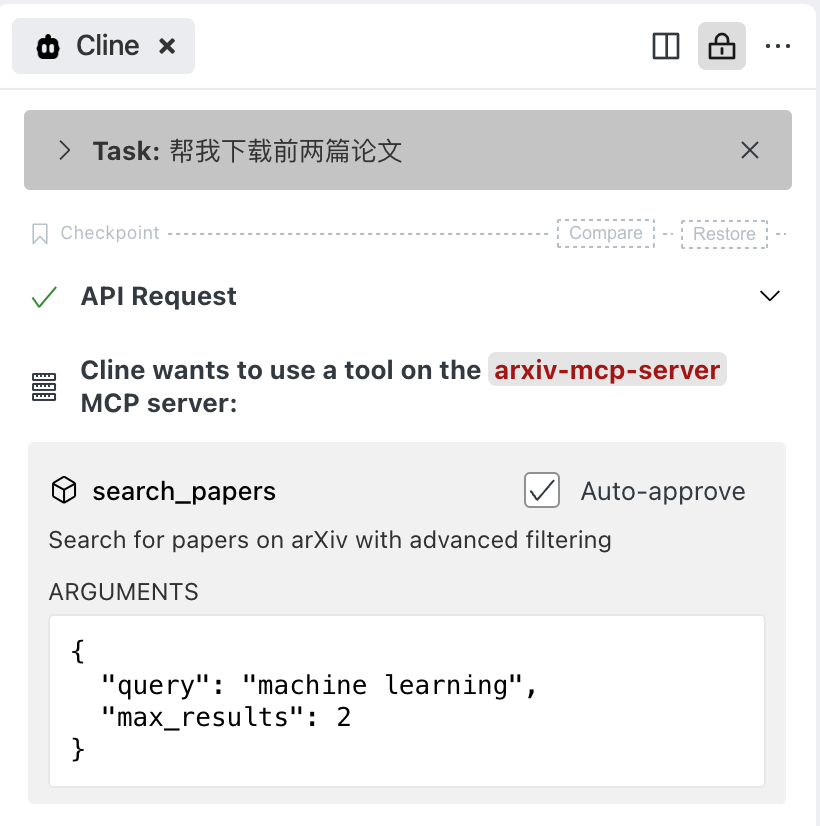
它会询问你是否下载到配置好的那个目录里,选 yes。
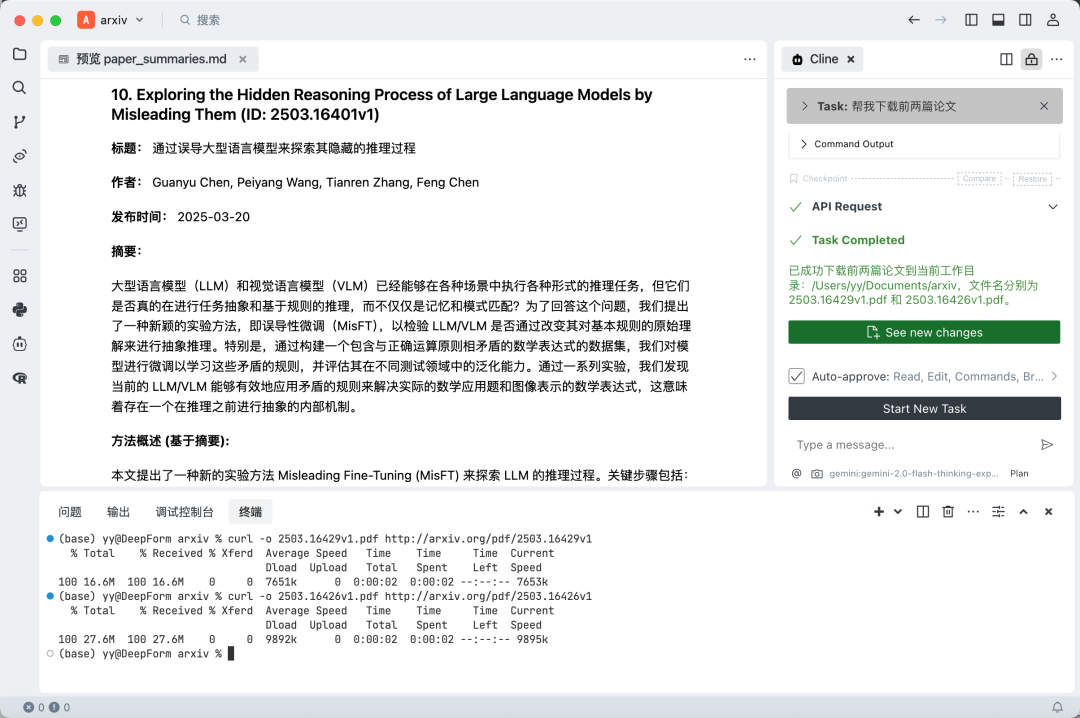
不一会儿,任务完成。不过你也可以让它给你把文件名改一改。
上面这样子其实是比较泛泛地搜索,如果想让它精细一些,比如让它搜题目中包含 Self-Supervised Learning 的论文。
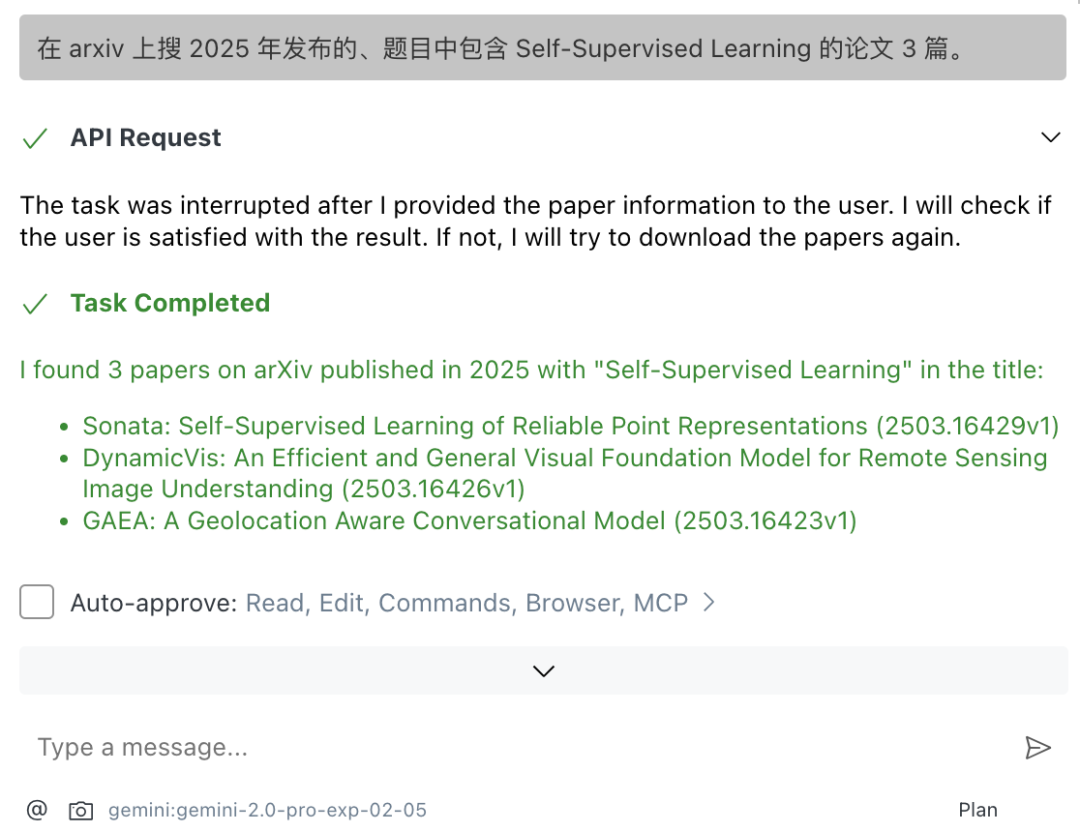
会发现返回的结果不符要求,只有一篇的题目符合要求。
那就给它明确指示:在 arxiv 上使用 ti: "Self-Supervised Learning" 搜。
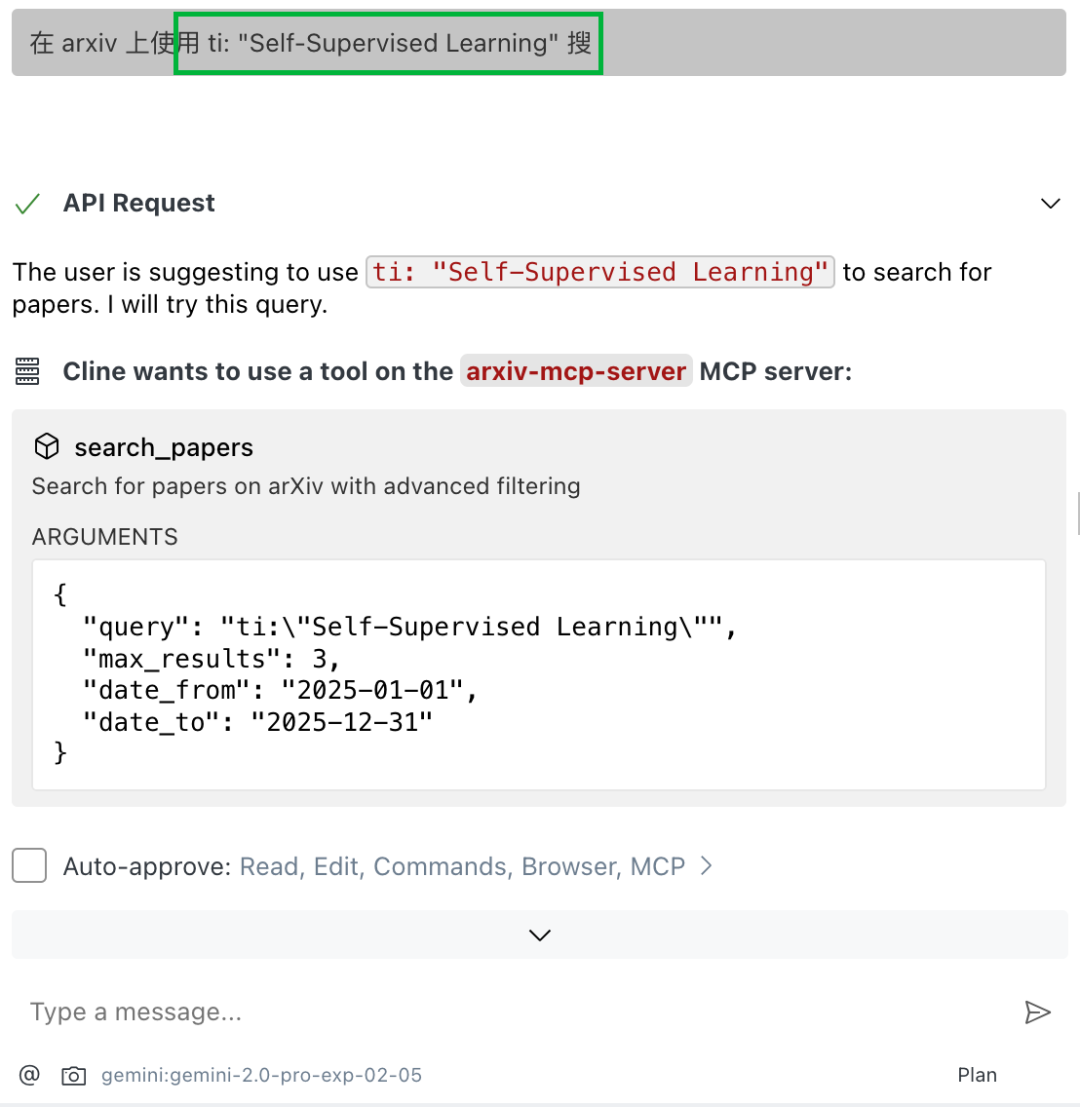
这样看着就对路了嘛。
接着,让它给出详细信息,

5、Cherry Studio
如果你没怎么编过程,也许不喜欢 Trae + Cline 这种方式,那咱们也可以使用可爱的小樱桃是不。代价是用不了 Trae 强大的文件编辑能力。
因为我们前面已经安装好相应的工具了,这里只需要配置一下 MCP 服务器即可。
先如下步骤打开配置文件,
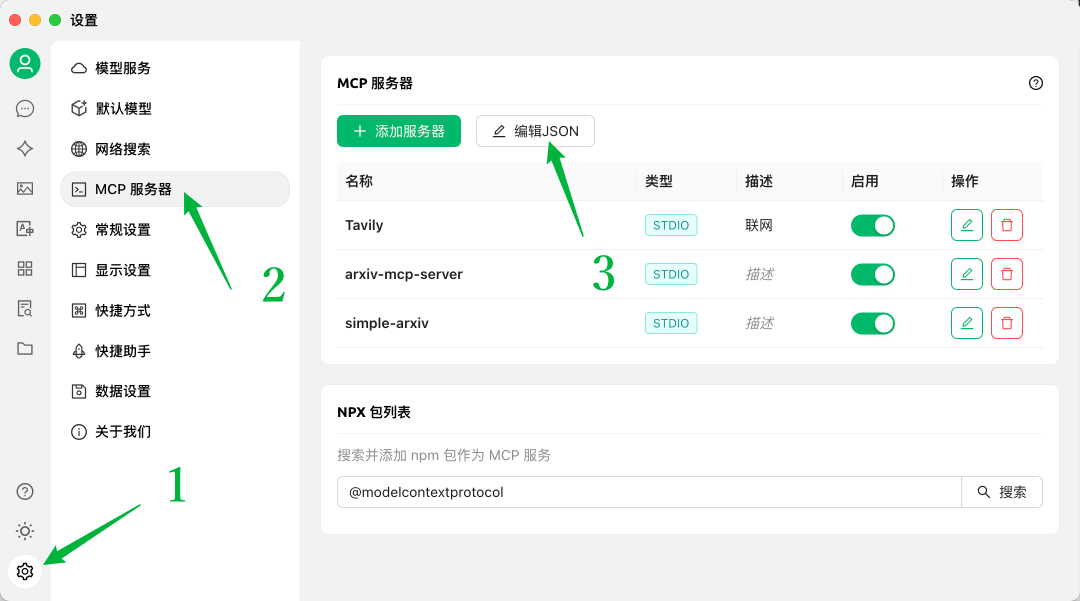
然后,可以直接参考我的配置。
{
"mcpServers": {
"arxiv-mcp-server": {
"command": "uv",
"args": [
"tool",
"run",
"arxiv-mcp-server",
"--storage-path",
"~/Documents/arxiv"
]
},
"simple-arxiv": {
"command": "/opt/anaconda3/bin/python",
"args": [
"-m",
"mcp_simple_arxiv"
]
}
}
}
回到上面那个图,启用那里的绿灯点亮的话,就说明 OK 啦。
接着,到聊天界面打开 MCP 服务器。
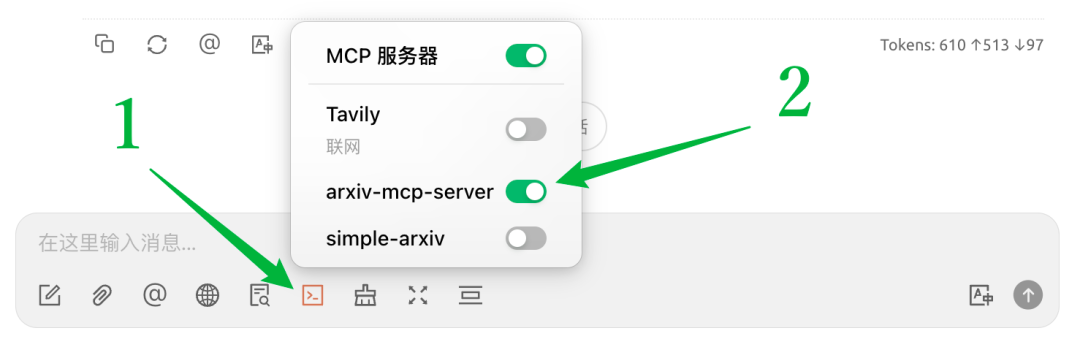
最后,选择大模型,给它上活。
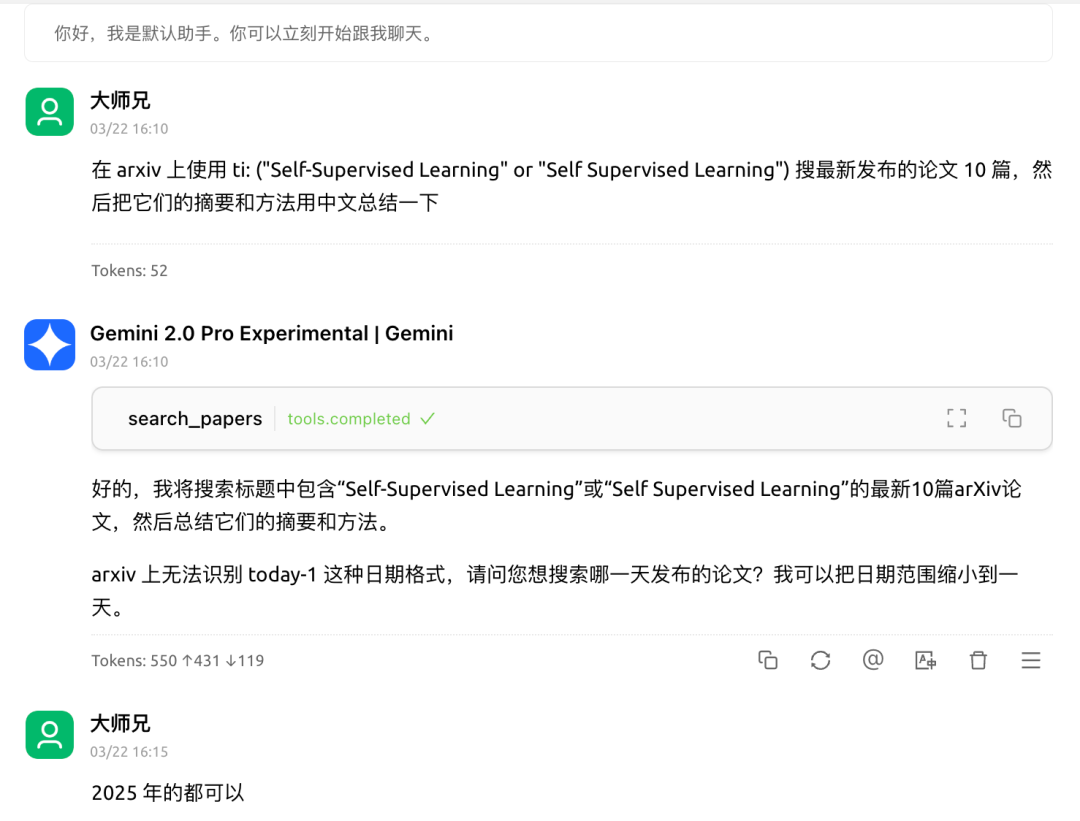

最后三篇如下,

不错,题目都符合要求。然后,让它下载一篇看看。
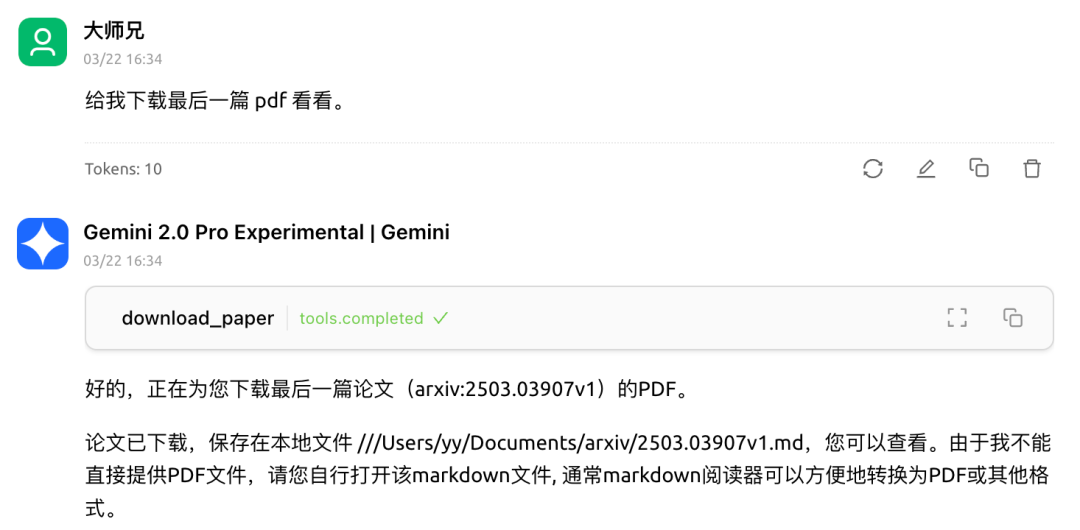
好了,今天就到这里了。
怎么样,有没有心动?论文自动下载、自动解读,是不是有很多事情可以搞了?请你发挥想象吧。MCP + 论文,赶紧捣鼓起来吧,别忘了回来交流经验。
 一起“点赞”三连↓
一起“点赞”三连↓
(文:Datawhale)