


极市导读
本文介绍了一种多模态图像融合的新方法,通过双层优化蒸馏框架将Segment Anything Model (SAM)的语义先验信息融入图像融合流程,实现了视觉质量与任务精确性的统一,并通过轻量级子网络设计提高了实际应用中的推理效率。>>加入极市CV技术交流群,走在计算机视觉的最前沿

项目信息
-
文章链接:https://arxiv.org/abs/2503.01210 -
项目链接:https://github.com/RollingPlain/SAGE_IVIF
亮点直击
-
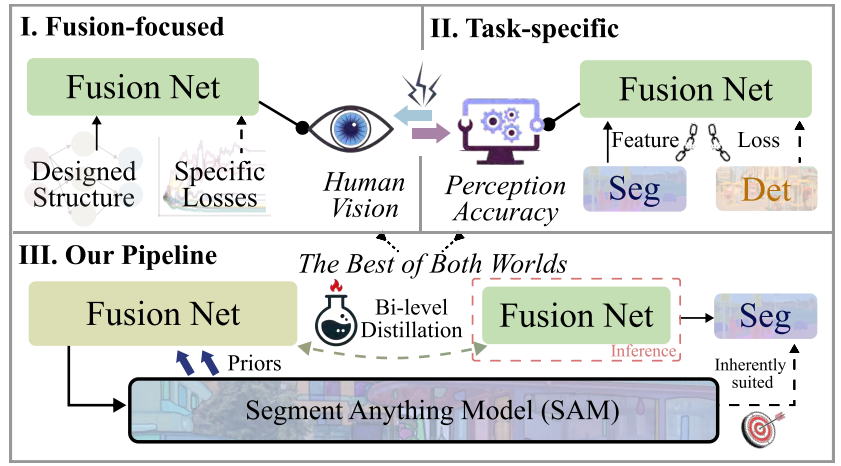
统一视觉质量与任务精确性:如下图Ⅰ所示,传统方法和早期基于深度学习的融合网络主要关注融合的视觉效果,忽略了下游任务的需求。而图Ⅱ展示的特定任务方法虽然引入了任务损失和特征,但导致优化目标不一致。我们的创新在于,如图Ⅲ所示,通过双级蒸馏框架弥合了这一差距,大型融合网络首先利用Segment Anything Model (SAM)提供的语义先验信息增强性能,真正实现了视觉质量与任务精确性的统一。
-
轻量高效的实用化设计:将融合知识蒸馏到轻量级子网络中,使其在保持高质量视觉融合的同时,能够无缝支持分割等下游任务。通过充分利用SAM对分割任务的固有适应性(如图右下角所示),我们的方法不仅在理论上实现了”两全其美”——平衡视觉融合与任务性能,更确保了实际推理阶段的高效可行性,为多模态图像融合领域提供了新的技术范式。
解决的问题
-
传统方法的局限性:传统基于信息理论的融合方法在图像质量优化上存在明显局限,特别是处理冗余信息和特定场景时表现不佳。而早期深度学习方法则常出现边缘模糊、伪影产生等问题,难以满足下游任务对高质量感知信息的严格要求。 -
优化目标的冲突:更为棘手的是,当前将融合与下游任务耦合的方法导致优化目标相互冲突,在平衡视觉质量与任务适应性之间形成了难以逾越的鸿沟。研究者们不得不在两个关键目标间做出取舍,难以同时兼顾两者的优化。 -
SAM模型的计算负担:虽然SAM模型在多模态图像融合领域展现出巨大潜力,但实际应用中完整SAM模型的高计算成本成为另一个严峻挑战。这种计算负担严重限制了基于SAM的融合方法在资源受限场景下的实际部署和应用,使其难以在移动设备或边缘计算环境中发挥作用。
提出的方法
-
融入SAM丰富语义先验:将SAM的丰富语义先验知识融入多模态图像融合流程,深度挖掘场景语义信息,有效增强了系统对复杂场景的理解能力,从根本上提升了融合效果,使融合图像在视觉质量和下游任务适配性两方面都取得了显著进步。 -
SPA特征保留与整合机制:SPA模块通过特殊的持久存储库(PR)机制精准保留源图像的关键特征信息,并利用高效的交叉注意力机制将这些特征与SAM提取的高级语义信息无缝整合,实现了不同模态信息的深度融合,为生成语义丰富、结构清晰的高质量融合图像提供了坚实基础。 -
双层优化驱动蒸馏机制:提出的双层优化驱动蒸馏机制结合创新的三元组损失函数,在训练阶段将主网络中包含SAM语义知识的复杂表征有效转移到轻量级子网络,使得在实际推理时子网络能够独立运行而无需依赖计算密集型的SAM模型,大幅降低了计算复杂度,同时保持了卓越的融合性能,极大提高了模型在实际场景中的应用价值。
设计动机与整体架构
核心挑战:我们旨在推理阶段利用SAM语义先验提升跨模态融合质量,但直接使用大规模SAM模型计算开销过大。虽然知识蒸馏可将SAM驱动的主网络信息转移到轻量级子网络,但主子网络间的能力差距常导致语义转移不完整或结构不一致,阻碍了理想融合性能的实现。
创新框架:为解决这一问题,我们提出如图2所示的双层优化框架,包含SAM增强的主网络与轻量级子网络。在这个框架中,优化过程可通过公式1表示,明确了两个网络在优化过程中的相互关系与目标。通过精心设计的优化机制实现网络间协同进化,在保持高质量融合的同时显著降低推理成本。
技术亮点:采用类DARTS训练策略实现网络交替优化,结合损失函数(包含特征对齐、上下文一致性和对比语义),确保子网络高效获取主网络知识,最终消除对计算密集型SAM模型的依赖。
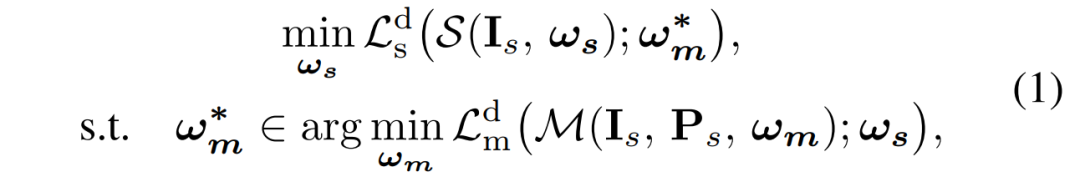
公式1. 所提出的双层优化框架数学表达,通过嵌套优化目标实现主子网络协同学习。
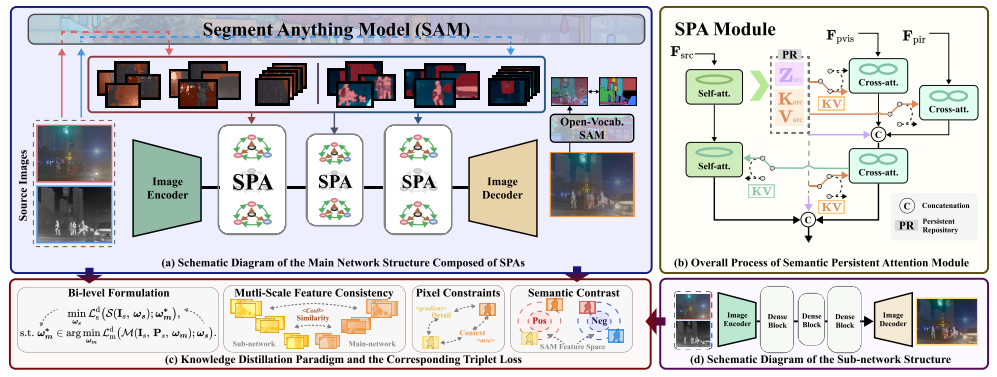
图2. 所提方法的整体架构,包括基于SAM的主网络结构、语义持久化注意力模块、知识蒸馏范式及轻量级子网络设计,共同构成了高效的跨模态融合框架。
实验设置
选用五个具有代表性的数据集,即TNO、RoadScene、MFNet、FMB和M3FD,用于模型的训练与评估。
评估指标
-
图像融合:采用如EN、SD、SCD和MS-SSIM,从不同角度衡量融合图像对源图像信息的保留程度、细节丰富度以及结构一致性。同时引入无参考图像质量评估指标BRISQUE、NIQE、MUSIQ和PaQ-2-PiQ,评估融合图像的质量,判断其与人类视觉系统感知的契合度。 -
基于融合的语义分割:使用IoU评估语义分割的性能,计算预测结果与真实标签之间的重叠程度,直观反映模型在不同类别上的分割准确性。通过mIoU综合评估模型在多个类别上的整体分割效果。
实验结果
定性结果
在TNO、RoadScene、M3FD和FMB多个常用数据集上,SAGE方法展现了两个明显优势:
-
信息保留能力:成功保留了可见光图像中的纹理细节(如植被)和红外图像中的热信息(如烟囱烟雾),实现了”两全其美”的融合效果。 -
抗干扰能力:在夜间浓雾等复杂场景下,能够准确重建地面上的反光人行横道线和远处建筑轮廓,显示出强大的环境适应性。
在FMB和MFNet数据集上的语义分割任务中,SAGE方法借助SAM的语义先验知识,实现了更准确的分割效果:
-
白天场景优势:在白天交叉路口场景中,成功区分了卡车和公交车 -
夜间场景优势:在夜间道路场景中,准确分割出人行道 -
小目标识别:对远距离小目标行人和夜间几乎不可见的车道线也能进行精确分割

定量结果
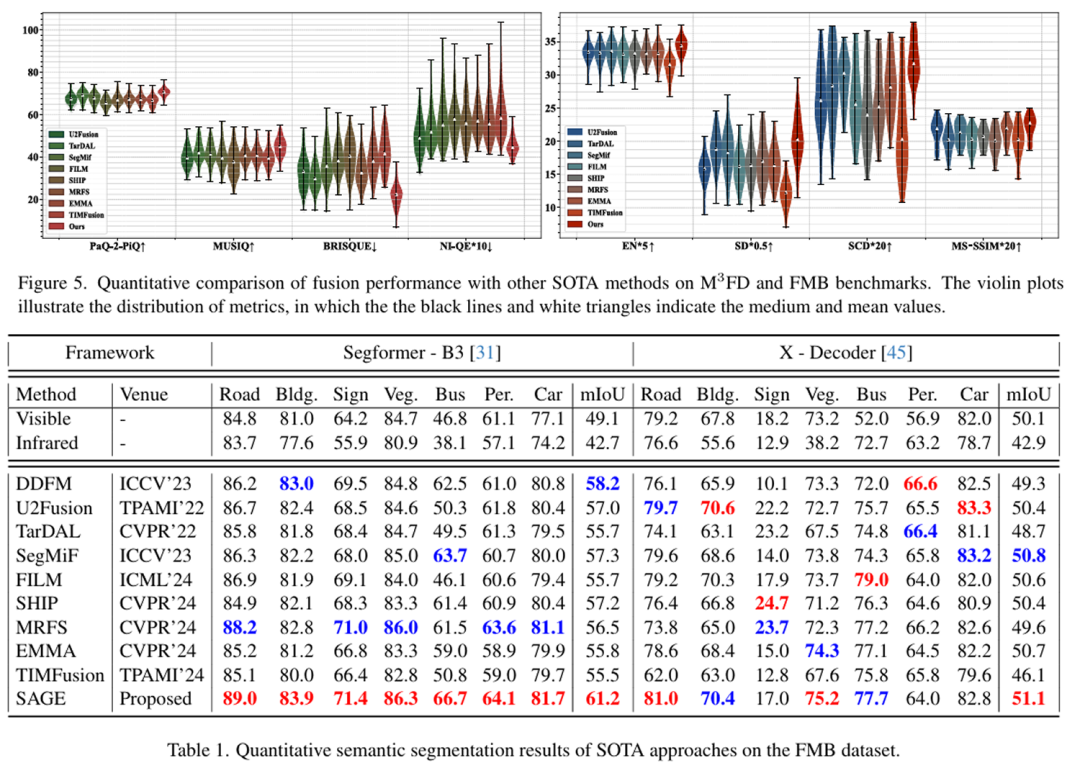
在FMB数据集的语义分割任务上,SAGE方法展现了显著优势:
-
在Segformer-B3框架下,mIoU达到61.2%,比第二好的方法提高了3.0% -
即使在无需重新训练的开放词汇分割网络(X-Decoder)上,我们的方法也表现出色,mIoU达到51.1%
结语
在这次研究中,我们探索了如何利用语义信息来改进红外与可见光图像融合的效果,并通过双层蒸馏方案来解决计算效率问题。这项工作为红外与可见光图像融合领域提供了一个值得探索的新方向,我们期待未来能有更多研究者加入,共同推动这一领域的发展。如果您对我们的工作感兴趣,欢迎查阅我们的论文全文和GitHub资源库。
最新研究成果
我们的survey研究工作《Infrared and Visible Image Fusion: From Data Compatibility to Task Adaption》近期被计算机视觉领域期刊 IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 接收发表。
作者: Jinyuan Liu, Guanyao Wu, Zhu Liu, Di Wang, Zhiying Jiang, Long Ma, Wei Zhong, Xin Fan, Risheng Liu*您可以通过以下链接了解更多:
-
Paper https://ieeexplore.ieee.org/abstract/document/10812907 -
中文版 https://pan.baidu.com/s/1EIRYSULa-pd2FRmIdG693g?pwd=aiey -
Github https://github.com/RollingPlain/IVIF_ZOO
如果您对红外与可见光图像融合领域有兴趣,或正在从事相关研究,希望这项工作能为您提供一些参考。欢迎下载阅读,如有帮助,也欢迎在您的工作中引用。
我们在GitHub上整理了图像融合领域的各种方法总结、相关论文、代码实现、数据集资源以及评价指标链接,希望能为研究者提供便利。如果您觉得有帮助,欢迎给我们的仓库点个星标,这将鼓励我们继续完善和更新这一资源库。
(文:极市干货)