


极市导读
在消费级显卡上将3DGS的训练耗时降低到了200秒以内。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
我们提出一种即插即用的3DGS训练加速策略——DashGaussian,其成功地在多个数据集上将多种3DGS骨干的训练速度提升了平均一倍,且保留甚至改进了这些3DGS骨干对场景的重建质量。使用DashGaussian增强先前的3DGS快速训练方法,我们成功地在消费级显卡上将3DGS的训练耗时降低到了200秒以内。
论文网址:https://arxiv.org/abs/2503.18402
项目网址:https://dashgaussian.github.io/

1. 概要
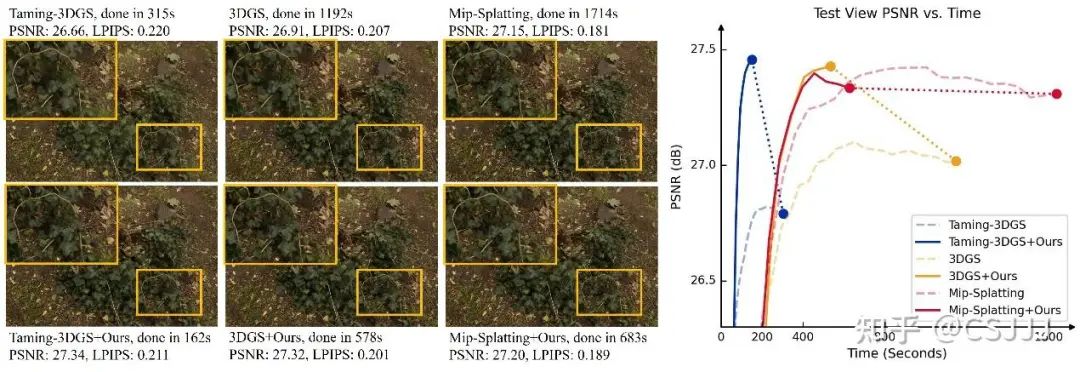
在3DGS的训练过程中,渲染分辨率与高斯基元数量作为决定渲染 (forward rendering)、梯度反传 (gradient backward propagation) 以及高斯基元优化 (optimization) 这三者时间复杂度的主要因素,极大地影响了3DGS的训练速度。我们将这两者合并称为3DGS的“计算复杂度”。在常规的3DGS训练框架下,早期训练使用高分辨率图像监督少量的高斯基元,极为浪费计算复杂度;同时在训练的半段,随着高斯基元数量的增大,计算复杂度增大导致耗时激增,而对于场景的重建质量提升却收效甚微(见图1右侧曲线图)。这些现象都表明现有的3DGS训练框架存在较大的计算复杂度冗余。
为了减小3DGS训练的计算复杂度,常见地我们可以使用coarse-to-fine的训练策略——在3DGS训练的前期使用低分辨率训练,后期使用原本的高分辨率训练。然而现有的coarse-to-fine策略面临着训练速度与训练质量的抉择:coarse阶段占比增大固然会加快3DGS的训练,但是这将导致aliasing问题并降低最终训练得到的3DGS质量,反之亦然。
为了解决这一问题,我们借鉴了传统图像分析理论。考虑两幅数字图像,其中一幅低分辨率图像由另外一幅高分辨率图像通过频域低通滤波获得。从频域分析两幅图像之间的差异(见图2):将两者的频谱中心(最高频位置)对齐,发现两幅图像的差异其来自于高分辨率图像比低分辨率图像多出的高频频谱(外围部分),而两者频谱中心部分是相同的。受上述分析启发,我们认为3DGS从低分辨率图像到高分辨率图像的训练等价于让3DGS从低频到高频逐渐拟合场景。于是,我们提出一种基于训练图像频域信息显著度的场景自适应3DGS训练分辨率规划策略。
进一步地,我们认为某一具体的分辨率应当配合恰当数量的高斯基元进行3DGS训练,以平衡场景的拟合程度和训练效率。我们提出一种基于训练分辨率规划的高斯基元增长规划策略,为每个训练分辨率配备恰当数量的高斯基元。与此同时,为了让高斯基元增长规划不再需要事先通过专家先验指定最终的高斯基元数量,我们还提出了一种基于动量场景自适应3DGS基元增长终点估计方法,使得我们可以在不事先指定最终高斯基元数量的前提下合理规划高斯基元的增长。
本工作的贡献总结为以下三点:
-
我们通过合理地规划3DGS训练过程中的计算复杂度,剔除大量冗余计算,极大地加速了3DGS的训练。 -
我们提出一种场景自适应规划策略,同时地控制3DGS训练过程中的训练分辨率以及高斯基元数量的增长,来确保3DGS的重建质量。 -
我们设计了一种场景自适应的高斯基元增长终点估计策略,使得我们可以在不事先指定最终高斯基元数量的情况下合理地规划高斯基元增长。
2. 方法介绍
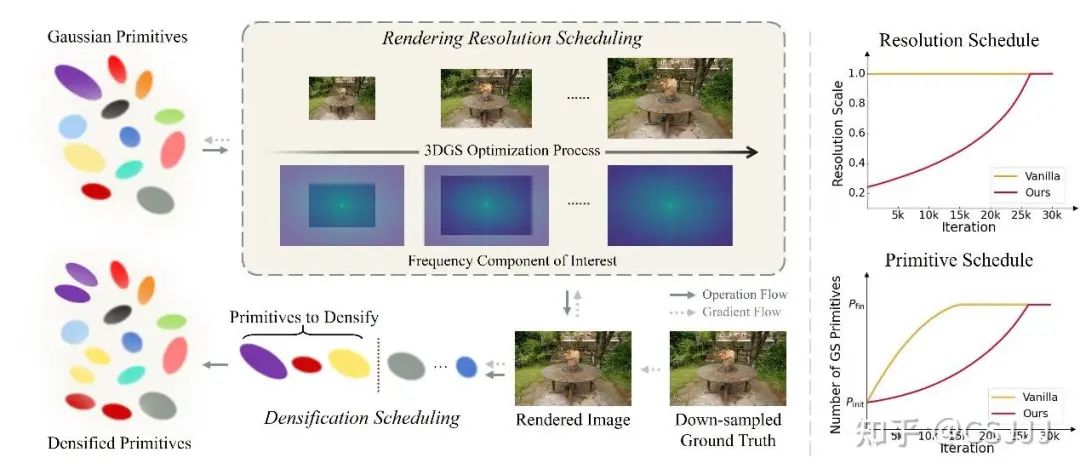
2.1 基于图像频率信息的场景自适应3DGS训练分辨率规划
假设我们目前有个3DGS训练视角 ,它们的分辨率都为 。我们定义这一分辨率的显著度为, , 其中, 为 通过离散傅里叶变换(Discrete Fourier Transform ,DFT)获得的频谱。类似地,在将 下采样到原分辨率 的情况下 ,我们可以得到分辨率 的显著度 。
直觉上,当 远大于 时,意味着分辨率 远比分辨率 更加显著,则整个3DGS的训练过程应当由较高的原分辨率主导。基于这一性质,我们定义一比率函数如下, , 基于这一比率函数,我们为原分辨率 分配个训练轮数 ,其中 为3DGS的总共训练轮数。我们在第 步训练时将训练分辨率由 升至 。我们可以通过回归法将情况推广至使用多个训练分辨率的情况。
2.2 基于自适应分辨率规划的3DGS基元增长规划
由于3DGS主要描述场景的几何表面,我们认为高斯基元的数量应与场景表面的复杂程度相关,而训练视角观察到的场景表面复杂程度又与训练视角的分辨率有关。于是,我们建立高斯基元与训练分辨率的联系如下: , 其中, 表示规划下第 步训练应有的高斯基元数量, 表示初始高斯基元数量, 表示规划下的最终高斯基元数量, 表示第 步训练的降采样倍数。我们通过乘方因子 来抑制高斯基元在早期的增长,鼓励其在中后期的增长来使得高斯基元更好地收敛。
2.3 基于动量的场景自适应3DGS基元增长终点估计
现有的研究通常基于专家先验或是数据集先验来在训练开始前决定 。通过此类手段定下的 通常难以被解释是否足以充分地描述一个三维场景,且这类手段难以被未经专业训练的普通算法用户使用。为了解决这一问题,我们提出一种基于动量的 估计策略,将 作为一个变量,在训练过程中实时更新, , 其中, 表示第 步训练时估计得到的高斯基元增长终点; 为DashGaussian所增强的 3DGS骨干无额外限制条件下在第 步训练时自身增长的高斯基元数量; 为两超参数,论文中分别统一指定为 0.98 和 1.0 。 通过上述方法,我们将高斯基元早期的增长累积到 中,随着训练的进行,通过高斯基元增长规划释放,最终实现了高斯基元与训练分辨率协同的先慢后快的增长。
3. 实验
3.1 实验设置
我们在Mip-NeRF 360, Deep Blending, Tanks&Temples等三个数据集上验证了DashGaussian的能力,并进一步在论文附录中报告了DashGaussian对3DGS大场景重建的增益。我们汇报了PSNR, SSIM, LPIPS等三项指标以衡量场景重建质量,并同时汇报了最终模型中的高斯基元数量以及训练耗时(分钟)。
3.2 DashGaussian与其他快速训练方法的比较
在表1中,我们汇报了使用DashGaussian增强Taming-3DGS的结果。DashGaussian在大幅提升训练速度的同时显著地提升了对场景的重建质量,重建质量明显高于各比较方法,且在三个数据集上的平均重建用时均在200秒以内。


3.3 使用DashGaussian增强不同3DGS骨干
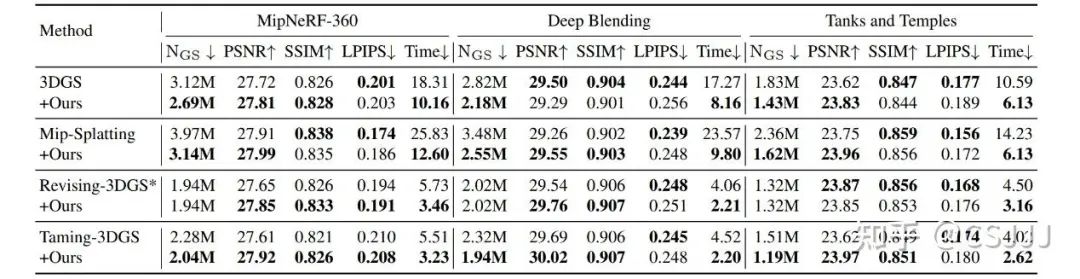
在表2中,我们汇报了使用DashGaussian增强不同3DGS骨干的结果。DashGaussian在不同3DGS骨干和不同数据集上实现了平均的训练耗时减少,训练速度提升将近一倍,维持甚至提升了训练质量,且减少了最终模型中的高斯基元数量。更多丰富的可视化结果见论文主页https://dashgaussian.github.io/。
3.4 消融实验
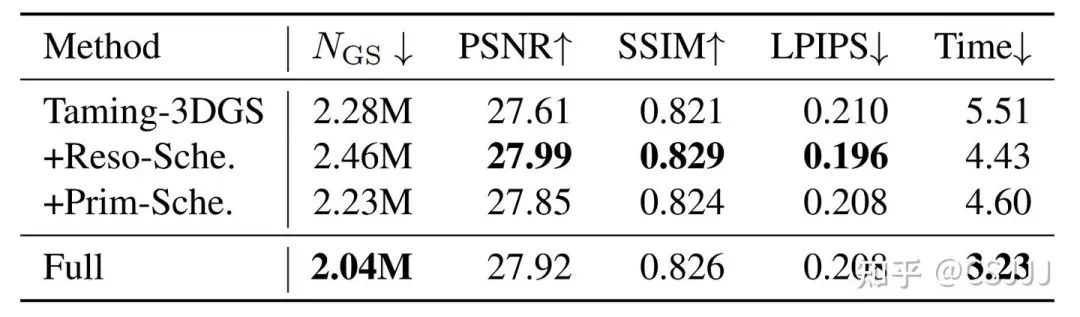
我们在表3中对DashGaussian提出的分辨率规划以及高斯基元增长规划策略进行了消融实验。我们在Mip-NeRF 360数据集上使用Taming-3DGS作为3DGS骨干进行消融实验,将仅使用分辨率规划和仅使用高斯基元增长规划分别记为+Reso-Sche.以及+Prim-Sche.,并将完整的DashGaussian记为Full。结果表明,两个模块皆能有效地降低训练时间以及提高渲染质量。
4. 总结
本文介绍了DashGaussian,一种即插即用的3DGS训练加速策略。DashGaussian将3DGS的coarse-to-fine训练过程建模为从低频到高频的场景拟合,并基于此提出了对训练分辨率以及高斯基元增长的协同规划策略。DashGaussian成功在多个数据集上将不同3DGS骨干的训练速度提升了一倍,且维持甚至改进了3DGS骨干原有的重建质量。更多方法细节请见论文原文:https://arxiv.org/abs/2503.18402。
(文:极市干货)