

极市导读
一种将 Diffusion U-Net 架构对齐到 ViT(Vision Transformer)特征空间的新方法U-REPA >>加入极市CV技术交流群,走在计算机视觉的最前沿
太长不看版
把 REPA 用到 Diffusion U-Net 架构的尝试。
Representation Alignment (REPA)[1]是一种对齐 Diffusion Transformer (DiT) 和 ViT 视觉编码器的文章,可以作为 DiT 辅助训练的一种有效手段。
但是,把 REPA 用到 U-Net 架构还没有过尝试。这会有些挑战,比如:
-
不同的 Block 功能需要改变对齐的策略。 -
U-Nets 的空间下采样会造成空间维度不一致。 -
U-Net 和 ViT 之间的特征差距阻碍了 token 有效对齐。
为此,本文提出了 U-REPA,一种新的表征对齐范式,意在对齐 U-Net hidden state 和 ViT feature。
U-REPA 做法:
-
观察到因为 U-Net 中 skip connection 的存在,U-Net 的中间 stage 是最好的对齐选项。 -
先把 U-Net 特征通过 MLP,再对其结果进行上采样。 -
观察到作 token 相似性对齐时有困难,因此引入了一个流形损失,规范了样本之间的相似性。
U-REPA 可以实现出色的生成质量,且大大加快收敛速度。U-REPA 在 ImageNet 256 × 256 上训练 200 epochs 可以实现 FID<1.5 的结果,比 REPA 表现更好。
本文目录
1 U-REPA:将 Diffusion U-Nets 和 ViTs 对齐
(来自北大,北京华为诺亚方舟实验室)
1 U-REPA 论文解读
1.1 U-REPA 研究背景
1.2 REPA 回顾
1.3 把 U-Net 对齐到 ViT
1.4 其他改进
1.5 实验设置
1 U-REPA:将 Diffusion U-Nets 和 ViTs 对齐
论文名称:U-REPA: Aligning Diffusion U-Nets to ViTs
论文地址:
http://arxiv.org/pdf/2503.18414
1.1 U-REPA 研究背景
表征对齐 (Representation Alignment, REPA)[1]是一种将 Diffusion Transformer (DiT) 的特征与现代视觉编码器 (MAE, DINOv2 等等) 对齐的方法,已被证明可以显著加速 DiT 的训练。鉴于 DiT 的日益突出,这种方法具有特别重要的意义。
像 U-DiT[2],DiC[3]这样的工作证明,基于 U-Net 的模型可以表现出更快的收敛速度,同时实现与基于 Transformer 的模型相当的生成质量。这个现象启发作者进行探究:基于现代 Vision Transformer (ViT) 的视觉编码器能否通过类似于 REPA 的对齐机制来指导 Diffusion U-Net 的训练,从而潜在地提高扩散模型的收敛速度上限?
但是,对齐 U-Net 架构和基于 ViT 的模型存在挑战。与 DiTs 不同,U-Net 架构与 ViT 的操作完全不同。具体来说,其一,DiT 和 ViT 都采用各向同性架构的 Transformer Block 组成,从架构上就固有地促进了两者参数的对齐。相比之下,U-Net 的 skip connection 通过将浅层和深层网络层连接在一起来创建强大的相互依赖性,产生了不同的特征传播动态。这种架构差异使得为 DiT 架构开发的 REPA 表征对齐策略不适用于 U-Net。其二,与 ViT 编码器中的固定尺度特征表示相比,U-Net 中的渐进下采样操作使得特征的空间维度不匹配,为接下来对齐操作带来了额外的复杂性。其三,U-Net 和 ViT 的特征有很大差距,使用余弦相似度作为指标可能有阻碍。像 REPA 那样使用 token 相似性作为损失不一定是最佳选项。这促使作者重新思考优化目标。
1.2 REPA 回顾
表征对齐 (Representation Alignment, REPA)[1]从现成的基于 ViT 的视觉编码器 (例如 DINOv2、CLIP、MAE 等) 中提取具有语义特征,来蒸馏 Diffusion Transformer。
给定一个基于 ViT 的视觉编码器 和干净图像 ,令 表示其 patch embedding,其中 和 分别表示 Patch 的数量和嵌入维度。REPA 把 patch embedding 和 diffusion 模型输出 对齐,其中, 是时间步 处 DiT 的 latent 表征, 代表可训练的 MLP。
REPA 通过最大化 token 特征相似性来强制对齐,即 DiT hidden-state 的 token 与 ViT Encoder 特征的 token 之间的相似性:
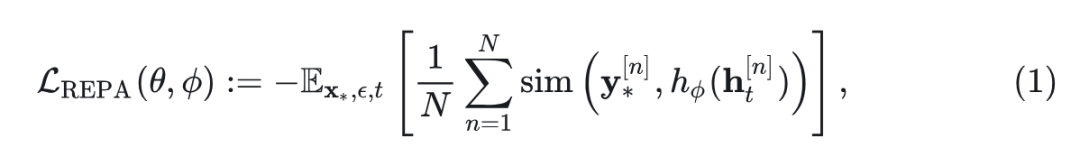
其中, 表示相似性度量(例如余弦相似度)。通常, 为 DiT 早期层输出(原始工作 REPA 采用第 8 层),以更好对齐。通过可调的系数 与 flow-based 的扩散目标(即 SiT)相结合,扩散模型训练的最终损失函数如下:

1.3 U-REPA 做法
在扩散模型中,U-Net 和 Isotropic 的 DiT 架构设计理念不同。基于 U-Net 的方法相比 DiT 强调更快的收敛。作者研究了 U-Net 的2个核心组件:skip connection 和下采样。
-
Skip connection: 在 Encoder 和 Decoder 层之间提供快捷连接,理论上有助于梯度流和特征重用 -
下采样: 降低空间分辨率 (每个阶段为 2),以实现分层、多尺度特征学习。下采样总是与跳过连接配对,以减轻信息损失。
作者首先通过一个 toy experiment 评估 U-Net 不同组件在收敛方面的贡献。
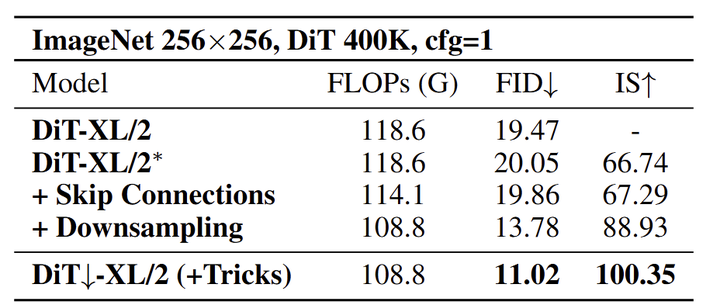
图 1 表明,U-Net 的快速收敛主要源于通过下采样的多尺度分层建模,而不是 skip connection。下采样将特征压缩为紧凑、语义丰富的表征,加速学习,同时保持信息流通过跳过增强 Decoder。但是 skip connection 并非无用的,因其补偿了下采样造成的信息丢失。
本文动机是研究 REPA 是否可以在 U-Net 上 work。
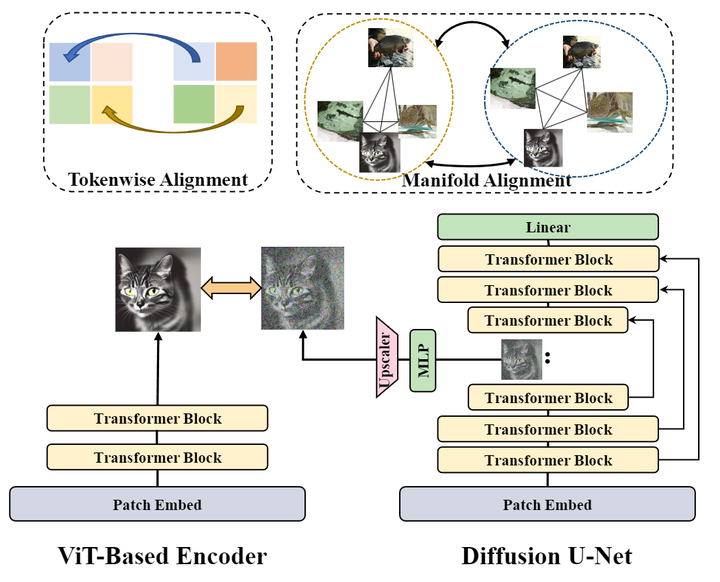
对齐的位置
U-Net 和 DiT 之间的 Block 功能存在差异。U-Net 架构通常使用中间网络层进行高级语义合成,同时保留浅层用于低级图像细化,而 DiT 表现出完全不同的模式,浅层主要控制语义丰富的轮廓形成,更深的层处理详细的图像细化。
REPA 的实验结果也支持这些结论,也就是把表征对齐用在初始的 Transformer Block 是最有效的。这个现象的原因是 DiT 浅层编码了丰富的语义信息,这些表征与基于 ViT 的视觉编码器的输出很好地对齐,从而实现有意义的指导。
与 DiT 相比,U-Net 架构中的 skip connection 会产生根本不同的 Block 功能。U-Net 的跨层快捷连接在浅层和深层之间建立直接依赖关系,从根本上改变了特征图的演化模式。如图 3 所示,带有 skip connection 的 DiT 的中间层最适合做表征对齐。尽管 U-Net 有下采样操作,但也是这样。
特征尺寸对齐
Diffusion U-Net 中间阶段和 ViT 没法直接对齐,因为特征大小不一致。这种维度的不匹配阻碍了 REPA 的 token 相似度计算,因为这需要比较特征之间的严格基数匹配。
为了对齐 2 个特征图 (U-Net 和 ViT 编码器的特征),作者试了下面 3 个方案:
-
先 Upscale,再 MLP:特征先上采样再给 MLP。 -
在 MLP 过程中 Upscale:MLP 充当特征上采样器。 -
先 MLP,再 Upscale:特征首先通过 MLP,然后进行上采样。
在以上方案中,作者发现 “先 MLP,再 Upscale” 在性能和效率方面是最好的。
流形空间对齐
虽然在上面的步骤中选择出了最合适的 U-Net 特征来对齐,也已经在空间维度上匹配了,但是还有一个问题就是特征空间本身的问题。
首先,DiT 和 ViT 的结构是一致的,但是 U-Net 却不是,因其 skip connection 和下采样。因此,其隐藏状态和视觉编码器输出之间有明显的特征分布差距。其次,对齐所需的维度转换不可避免地修改了 U-Net 的原生特征空间特征。
最近,一些关于 Diffusion U-Net 的研究表明,高 stage 的 U-Net 特征会丢弃高频分量,包括噪声。作者认为原始 REPA Loss 这样的严格 token-level 的对齐是次优的,因为它假设对齐模态之间的隐式特征空间的同质性。
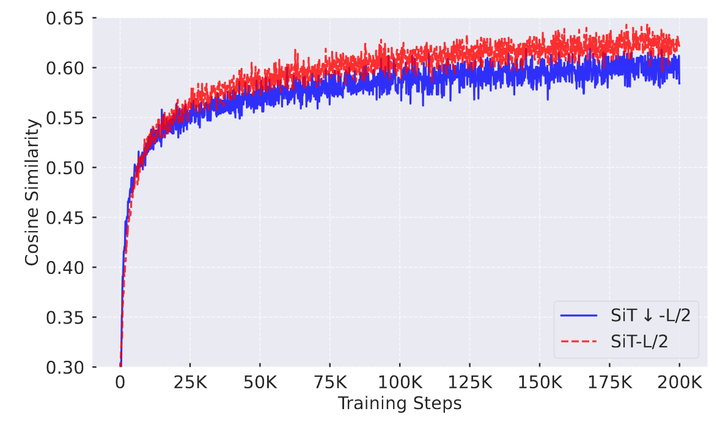
如图 4 所示,作者测量了在训练期间与 ViT 特征的 cosine similarity。对比的 2 个模型分别是 SiT-L/2 (Isotropic 模型) 和 SiT↓-L/2 (带有下采样的 U-Net 架构)。实验现象很有趣:虽然 SiT↓-L/2 在训练的早期相似性的提升稍快 (可能由于 skip-connection),但是在收敛的时候,与 ViT 的 token 相似性相比于 SiT-L/2 是更低的 (约 0.60 < 约 0.63)。
这个现象说明,通过这样的相似性度量方式对齐 U-Net 和 ViT 编码器,会受到架构不相容造成的限制的影响。
为此,作者没有采用严格的 token-wise 正则化,而是认为对齐来自同一特征空间的样本之间的相似性可能是一个解决方案。因此,定义 Manifold Loss 为:
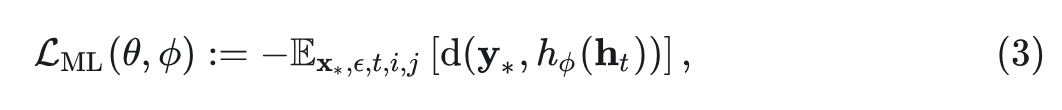
其中,
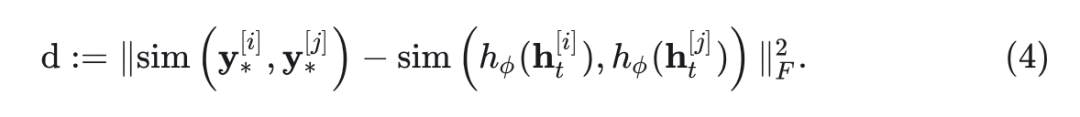
式中,采用余弦相似度作为相似度度量, 表示矩阵的 Frobenius Norm。通过引入超参数 ,整体优化目标可表示为:
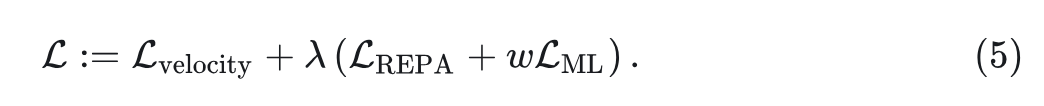
1.4 其他改进
Time-aware MLP
作者遵循之前工作的看法,在采样过程中,channel 维度对某个时间子集特别敏感。ViT Encoder 提取的特征是时不变特征,而 Diffusion 模型的特征是时变特征,因此作者认为,当 MLP 是 time-aware 的,可以从扩散模型中提取到时不变特征,以进行更好的对齐。
具体而言,作者加了一个模块来预测 channel-wise shift 和 scale 向量 。该模块与 MLP 并行,并遵循 DiT 的 AdaLN 的设计,是 SiLU 和线性层的串联。shift 和 scale 向量施加在输出 MLP 上,如下所示:
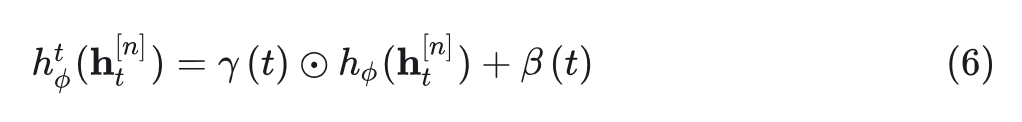
1.5 实验设置
模型配置
作者把本文的 U-REPA 架构在 channel 维度和 FLOPs 与标准的 DiT 或者 SiT 对齐。各种尺寸模型的配置如下。值得注意的是,当 FLOPs 对齐时,由于深度的增加,SiT↓ 通常比 SiT 有更多的宽度。

对于主实验,作者采用 1.65 的 cfg,与 SiT 不一样,guidance 间隔 [0, 0.7]。对于所有消融实验,训练 100K 次迭代的模型,足以展示模型性能的趋势;采样是使用官方 REPA 代码库的默认设置进行的,即 ODE 中的 cfg = 1.8,guidance 间隔 [0, 0.7]。
1.6 实验结果
不同尺度的 SiT↓ 与 SiT 进行比较
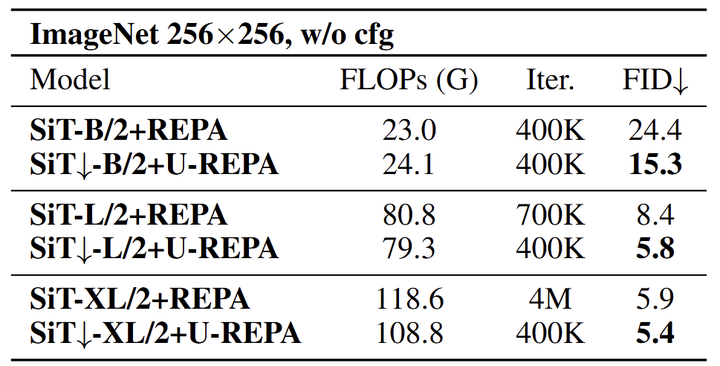
作者在 cfg = 1 的设置下在 ImageNet 256 上评估了本文的 U-REPA 对齐方法。如下图 6 所示,本文的方法不断提高生成质量,同时显著降低了模型的计算成本。对于基本的 SiT-B/2 模型,U-REPA 在 FID 上实现了 39.3% 的改进 (使用相当的 FLOPs 和训练迭代数),表明特征对齐在不增加训练开销的情况下提高了参数效率。在更大的模型中,加速度效应变得更加明显:对于 SiT-L/2,U-REPA 将所需的迭代次数减少了 42.9% (700K→400K),同时降低了 FLOPs (79.3G 与 80.8G),并实现了 30.9% 的 FID 改进 (8.4→5.8)。如图 7 所示,具有 U-REPA 的 SiT-XL/2↓ 模型与基线相比,使用 90% 的迭代轮数 (400K 与 4M) 和更少的 FLOPs (108.8G 与 118.6G) 实现了最先进的 FID 是 5.4,证明本文方法的快速收敛性。

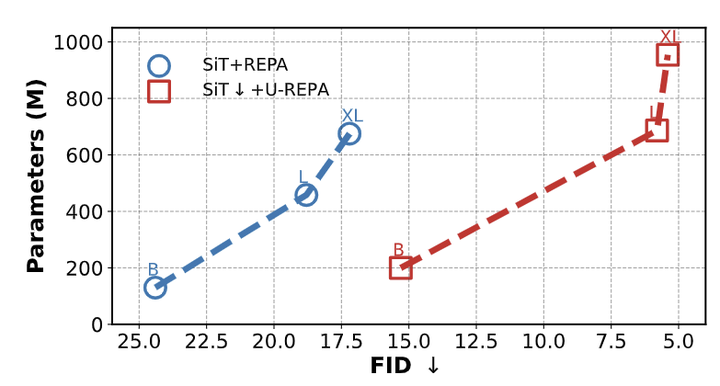
作者还展示了 U-REPA 在参数量上的优势,如图 8 所示。虽然当 FLOP 与 DiT 对齐时,U-Net 带来了额外的参数,但 SiT↓+U-REPA 的优势显而易见。
收敛性能
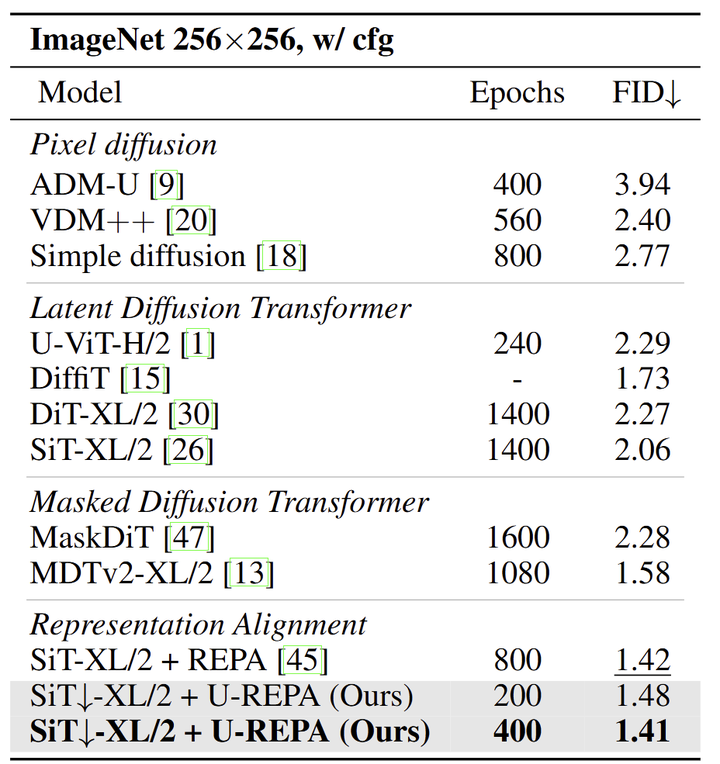
将本文方法与之前的最新技术进行了比较,如图 9 所示,SiT↓+U-REPA 在只训练 200 Epochs 的情况下实现了 1.48 的 FID,显着优于现有方法。值得注意的是,像 MDTv2-XL/2 这样的最先进的 masked diffusion transformer 需要 1,080 Epochs 才能达到 1.58 的 FID,本文方法获得了更好的性能 (1.48),迭代次数减少了80%。即使与 SOTA SiT-XL/2 + REPA 基线 (800 Epochs,1.42 的 FID) 相比,本文方法仅训练 400 Epochs,同时实现了更好的生成质量 (1.41 的 FID)。这些结果证明了 U-REPA 的性能和效率。
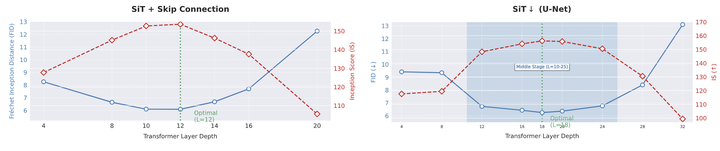
在什么深度进行对齐
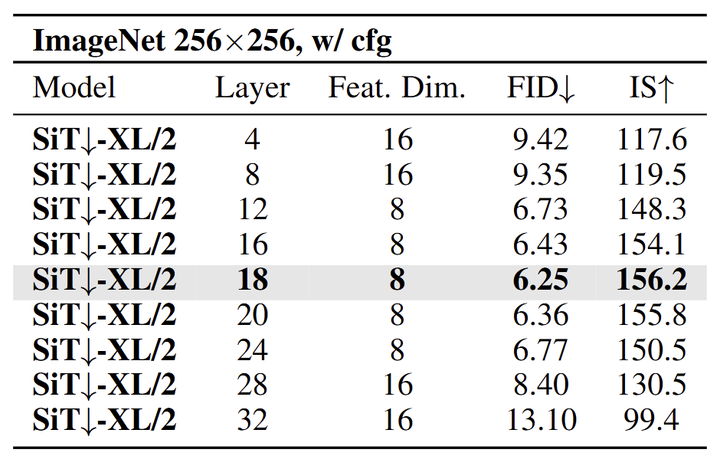
如图 10 所示,尽管渐进式的下采样会降低空间分辨率,但是在中间层进行对齐的结果是最好的。对于 SiT↓-XL/2 模型,在第 18 层对齐特征实现了 6.25 FID 和 156.2 的 IS,优于在浅层或者更深的层对齐的结果。中间层的特征维度只有 8×8,小于前面和后面层的 16×16,但是 FID 却更低,说明语义丰富度对于生成质量的影响超过了空间分辨率。
特征上采样方式
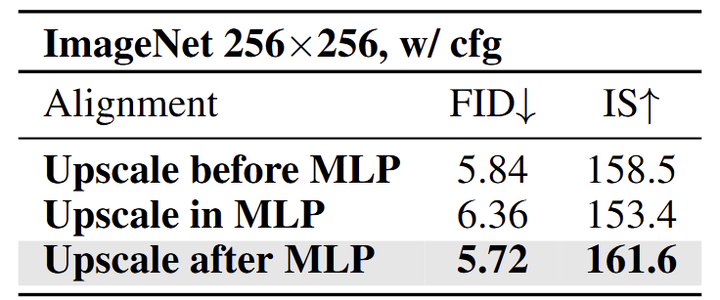
如图 11 所示,作者发现通过 MLP 后上采样 U-Net 的隐藏状态是最好的选择,达到 5.72 FID 和 161.6 IS。
Manifold Loss 的权重
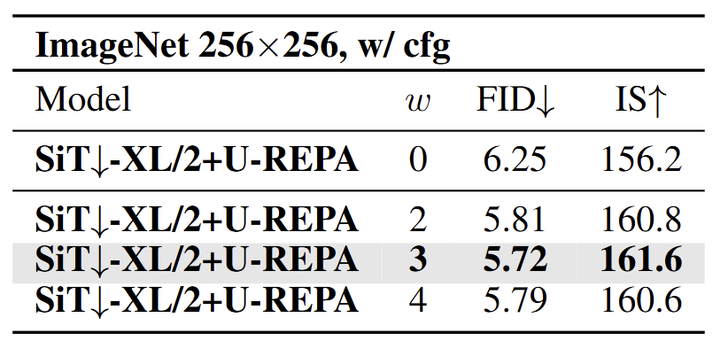
如图 12 所示,Manifold Loss 的权重 实现了最低的 FID(5.72)和最高的 IS(161.6)。这个最佳的权重很好地平衡了 Manifold Loss 与原始的 REPA loss 和 Diffusion 损失。正则化不足( 会限制特征空间的协调,过度正则化 则会使得 FID 低到 5.79 的结果。
参考
-
^abcRepresentation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think -
^U-dits: Downsample tokens in u-shaped diffusion transformers -
^Dic: Rethinking conv3x3 designs in diffusion models
(文:极市干货)