

极市导读
解耦 Encoder-Decoder Transformer 能否加速收敛并增强样本质量? >>加入极市CV技术交流群,走在计算机视觉的最前沿
太长不看版
一个类似 MAR+REPA 的技术。
本文研究的是 Diffusion Transformers。Diffusion Transformers 在每个去噪步骤中,输入是带有噪声的图片,会对其进行编码 (Encode),以提取低频语义分量。编码之后,再通过解码 (Decode) 恢复高频预测的噪声。
本文认为,这个过程带来了一个优化的困境:Encode 的过程需要减少高频分量,而 Decode 过程又需要增加高频分量,就会带来优化的难度。
因此,本文的解耦扩散模型 (DDT) 就可以应对这个问题:把 condition encoder 和 velocity decoder 解耦。condition encoder 用于提取语义信息,velocity decoder 用于解码。
DDT 的结果:对于 ImageNet 256×256,DDT-XL/2 实现了 1.31 FID 的 SOTA 性能。对于 ImageNet 512×512,DDT-XL/2 实现了 1.28 的 SOTA FID。
DDT 还有一个额外的好处:可以增加推理速度。原因是对不同 denosing steps 可以共享 condition。还专门提出了一种基于统计动态规划的方法来识别出最佳的共享策略。


专栏目录:https://zhuanlan.zhihu.com/p/687092760
本文目录
1 DDT:解耦扩散模型
(来自南京大学,字节 Seed Vision)
1 DDT 论文解读
1.1 DDT 研究背景
1.2 Diffusion Transformer 困境:低频语义编码能力有限
1.3 DDT 方法:解耦编解码器
1.4 采样加速
1.5 实验结果
1 DDT:解耦扩散模型
论文名称:DDT: Decoupled Diffusion Transformer
论文地址:
http://arxiv.org/pdf/2504.05741
代码链接:
http://github.com/MCG-NJU/DDT
1.1 DDT 研究背景
图像生成是计算机视觉研究的一项基本任务,其目的是捕捉原始图像数据集的固有数据分布,并通过采样合适的分布来生成高质量的图像。
Diffusion 的前向过程按照 SDE 前向过程逐渐向原始数据添加高斯噪声。去噪过程从这个损坏过程中学习分数估计。一旦准确地学习了得分函数,就可以通过数值求解反向 SDE 来合成数据样本。
Diffusion Transformer 将 Transformer 架构引入扩散模型中,以取代传统的主流的基于 UNet 的模型。在给定足够的训练迭代的情况下,即使在不依赖长残差连接的情况下,Diffusion Transformer 也优于传统方法。然而,由于成本高,它们的收敛速度慢仍然给开发新的模型带来了巨大的挑战。
本文希望从模型设计的角度解决上述缺点。传统模型常使用 Encoder-Decoder 架构,本文探索的是解耦 Encoder-Decoder Transformer 能否解锁加速收敛和增强样本质量,希望回答这个问题:解耦 Encoder-Decoder Transformer 能否加速收敛并增强样本质量?
本文的结论是:Diffusion Transformer 在 “提取抽象结构信息” 以及 “恢复详细细节信息” 之间存在优化的困境。此外,由于原始像素监督,DiT 在提取语义表征方面受限。
本文的解决方案:解耦 Encoder 和 Decoder,即解耦低频语义编码和高频细节解码。将此 Encoder-Decoder DiT 模型称为 Decoupled Diffusion Transformer (DDT)。DDT 包含一个 condition encoder 来提取语义特征。提取的自条件和 noised latent 一起被送入 velocity decoder 来计算速度场。为了保持相邻步骤的 Self Condition 特征的局部一致性,对解码器的速度回归损失进行间接监督,对表征对齐进行直接监督。
1.2 Diffusion Transformer 困境:低频语义编码能力有限
本文分析的主题是 Flow-based Model。 代表纯噪声。如图 3 所示,扩散模型其实相当于是对谱分量 Autoregressive 的细化[1]。Diffusion Transformer 对 noisy latent 进行编码,以捕获低频语义,然后再解码高频细节。然而,这种语义编码过程不可避免地会衰减高频信息,造成优化困境。
因此,DDT 觉得应该将传统的 Decoder-Only 的扩散模型架构解耦为显式的 Encoder-Decoder 架构。

引理1: 对于一个第 步的 flow-matching noise scheduler,定义 为干净数据 的最高频率。noisy latent 的最大保持频率为:

代表纯噪声。当 增加,噪声降低,此时语义编码变得更容易了(因为噪声降低),而解码变得更加困难(因为从低频的输入预测高频输出,这步需要预测的频率差大了)。
考虑第 去噪步骤的最坏情况,Diffusion Transformer 将频率编码为 ,直到第 步,它需要解码至少 的残差频率。如果没能在第 步解码此残差频率,就会为后续步骤创造瓶颈。
-
如果将更多的计算分配给噪声较大的时间步能够获得提升,意味着 Diffusion Transformer 难以编码低频信息,以提供语义信息。 -
如果将更多的计算分配给噪声较小的时间步能够获得提升,意味着 Flow-matching Transformer 难以解码出更高的频率,来提供更精细的细节。
如下图 4 所示,证明了与 uniform scheduling 相比,将更多的计算分配给早期时间步可以提高最终性能。这表明扩散模型面对的挑战,更多的是在比较 noisy 的时间步。
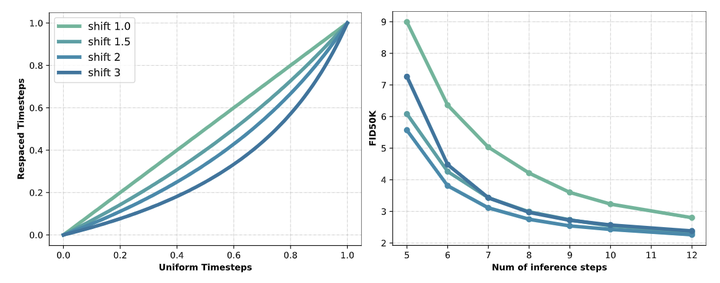
这就引出了一个关键的结论:Diffusion Transformer 从根本上受到低频语义编码能力的限制。 因此,本文探索了 Encoder-Decoder 的架构。
之前的研究 MAR 中,轻量级的 diffusion MLP head 的解码能力受限,因此 MAR 通过 Backbone 得到的语义 latent 做辅助,以完成高质量图像生成。
之前的研究 REPA 中,通过预训练的 vision foundations 的表征对齐,来增强低频编码。
1.3 DDT 方法:解耦编解码器
Decoupled Diffusion Transformer 包括一个 condition encoder 和一个 velocity decoder。
DDT 的整个框架是 linear flow diffusion。
Condition Encoder
condition encoder 的输入包括 noisy input ,时间步 ,以及 class label 。它提取的低频分量 self-condition 作为 velocity decoder 的输入条件。
其结构按照 DiT 和 SiT 设计,一系列 Attention 和 FFN 的堆叠。
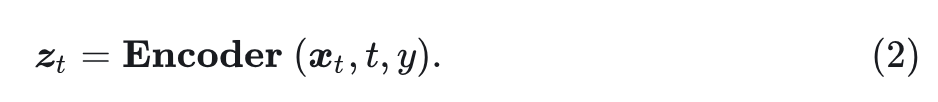
其中,noisy input 被 patchfied 为连续 token,然后通过 Condition Encoder 提取 self- condition 。时间步长 和类标签 作为额外的 condition 信息输入。这些外部 condition embedding 在每个 Block 中通过 AdaLN-Zero 逐渐注入到 noisy input 的编码特征中。
为了在相邻时间步中保持 的局部一致性,还采用了 REPA 的表征对齐技术。如式 3 所示,该方法将 Encoder 第 层的中间特征 与 DINOv2 表征 对齐。 是可学习投影 MLP:
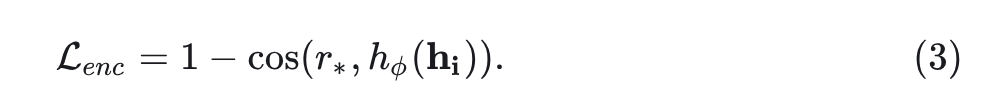
这种简单的正则化加速了训练收敛,促进了相邻步骤之间 的局部一致性。它允许在相邻步骤之间共享编码器的输出 。实验表明,这种编码器共享策略显着提高了推理效率,且性能下降可忽略不计。
Velocity Decoder
Velocity Decoder 采用与 Condition Encoder 相同的架构设计,由堆叠的 Attention 和 FFN 组成,类似于DiT/SiT。
Velocity Decoder 的输入包括 noisy input ,时间步 ,以及 Condition Encoder 提供的 condition ,目标是估计出高频速度 。Decoder 的额外输入只有时间步 ,以及 self- condition 。

为了提高相邻步骤之间 condition 的一致性,通过 AdaLN-Zero 把 condition 引入 Decoder 特征。
Decoder 使用 Flow-matching 损失进行训练,如式 5 所示:
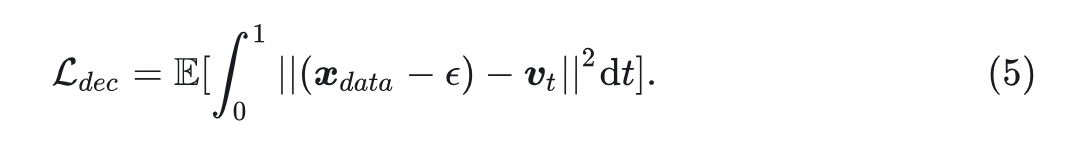
1.4 采样加速
通过将显式表示对齐合并到 Encoder 中,并将隐式 Self-condition 注入 Decoder 中,在训练期间跨相邻步骤实现 的局部一致性。这使我们能够在适当的局部范围内共享 ,从而减少 Encoder 的计算量。

给定总推理步骤 和 Encoder 的计算预算 ,共享率为 ,定义 为计算 Self- condition 的时间步,如式 6 所示。如果当前时间步 不在 中,将先前计算的 重用为 。否则,使用 Encoder 和当前 noise latent 重新计算 :
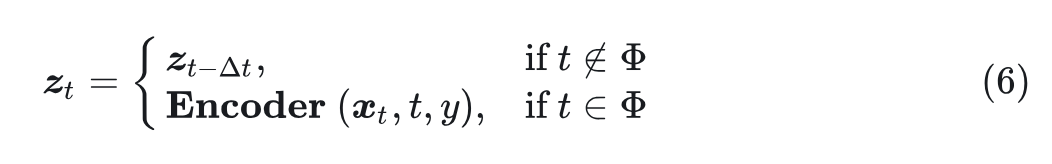
一种简单的方法 Uniform Encoder Sharing 是每 步计算一次 。以前的工作,例如 DeepCache,使用这种范式来加速 UNet 模型。
本文还提出一种统计动态规划的方法计算最优 集。具体细节不展开了。
1.5 实验结果
首先是 ImageNet 256×256 实验。batch size 是 256,使用的 VAE 是 VAE-ft-EMA,下采样 8 倍,channel 为 4 (SDf8d4)。
架构改善:SwiGLU, RoPE 和 RMSNorm。
训练加速:lognorm sampling。
通过结合这些先进技术开发了改进的基线模型。
这些改进基线的性能如图 6 所示。为了验证我们实现的可靠性,作者还复现了 REPA-B/2 的结果,实现了略高于 REPA 中最初报告的指标。
图 6 中本文方法的结果,在没有 REPA 的情况下始终优于之前方法。但在使用 REPA 时,性能迅速接近饱和点。这在 XL 模型大小中尤为明显,其中这些增加的技术带来的收益逐渐下降了。

作者在图 6 中展示了不同大小的模型在 400K 训练步骤的性能。DDT 在各种模型大小上表现出一致且显着的改进。DDT-B/2(8En4De) 模型超过 Improved-REPA-B/2 2.8 的 FID。DDT-XL/2(22En6De) 超过 REPA-XL/2 1.3 的 FID。虽然 decoder-only 的 DiT 使用 REPA 接近性能饱和,但 DDT 继续提供更好的结果。架构改进以及其他训练技术在模型尺寸增加时的收益递减,但 DDT 模型保持了显著的性能优势。
ImageNet 256×256 结果
图 7 报告了 DDTXL/2 (22En6De) 和 DDT-L/2 (20En4De) 的最终指标。
DDT 展示了卓越的效率,与 REPA 和其他 DiT 模型相比,使用近 1/4 的 Epochs 即实现收敛。
为了与 REPA 保持方法的一致性,DDT 在区间 [0.3,1] 中使用了 2.0 的 CFG,结果是 DDT-L/2 达到了 1.64 的 FID,DDT-XL/2 在 80 个 Epochs 获得了 1.52 的 FID。通过将训练扩展到 256 Epoch,DDT-XL/2 在 ImageNet 256×256 上实现了 1.31 的 FID,优于以前的 DiT。在将训练扩展到 400 个 Epoch 后,DDT-XL/2 (22En6De) 实现了 1.26 的 FID,几乎达到了 SD-VAE-ft-EMA-f8d4 的上限,在 ImageNet256 上有一个 1.20 rFID。

图 8 是 512×512 分辨率的结果。为了验证 DDT 模型的优越性,作者在 256 Epoch 下在 ImageNet 256×256 上训练的 DDT-XL/2 作为初始化,在 ImageNet 512×512 上微调 DDT-XL/2 100K 步。本文实现了 1.90 的 FID ,比 REPA 高出 0.28。在将更多的训练步骤分配给 DDT-XL/2 时,在 500K 步上实现了 1.28 个 FID,时间间隔为 CFG 3.0 [0.3, 1.0]。

Encoder sharing 加速效果
如图 5 所示,Condition Encoder 中得到的 condition 具有很强的局部一致性。即使 与 的相似度高于 0.8 。这种一致性提供了一个机会,通过共享相邻步骤之间的 Encoder 来加速推理。
作者采用 uniform encoder sharing 策略和统计动态规划策略。具体来说,对于 uniform 策略,每 步重新计算 。对于统计动态规划,通过动态规划求解相似度矩阵上的最小求和路径,并根据求解的策略重新计算 。如图 9 所示,当 小于 6 时,可以在实现显著推理加速的情况下,几乎没有视觉质量损失。如图 10 所示,指标损失微不足道,推理却显著加速。新提的统计动态规划策略略微优于原始的 uniform encoder sharing 策略。


消融实验:Encoder-Decoder 比例
作者系统地探索了 不同模型大小下从 2:1 到 5:1 的 Encoder-Decoder 比例。图 11 和图 12 显示了对架构优化的关键见解。
作者观察到,随着模型尺寸的增加,更大的 Encoder 有利于进一步提高性能。对于图 11 中的基本模型,最佳配置显示为 8 Encoder+ 4 Decoder,提供卓越的性能和收敛速度。值得注意的是,图 12 中更大的模型表现出明显的偏好,使用 20 Encoder+ 4 Decoder 实现了峰值性能,这个 Encoder-Decoder 的比例更激进。这种意想不到的发现促使作者将 DDT-XL/2 比例缩放到 22 Encoder+ 6 Decoder 来探索 DiT 架构的性能上限。


参考
-
^Diffusion is spectral autoregression
(文:极市干货)