

极市导读
做到保留离散 token 建模简单的优点,又可以保持连续 token 的强表示能力。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 TokenBridge:自回归生成中桥接连续和离散 token
(来自港大,字节跳动)
1.1 TokenBridge 研究背景
1.2 TokenBridge 的后训练量化
1.3 空间自回归主干 + channel 维度自回归头
1.4 自回归生成框架
1.5 实验设置
1.6 Tokenizer 实验结果
1.7 生成实验结果
太长不看版
离散模型的简洁性 + 连续模型的生成质量。
自回归视觉生成模型的一个重要部分是 tokenizer,它把图片压缩成 tokens,使之可以被序列预测出来。
但是,基于 token 做法的一个缺点是:离散的 token 支持使用标准 Cross-entropy Loss 来直接建模,但是会带来信息损失,以及训练的不稳定性。相比之下,连续 token 可以更好地保留视觉细节,但缺点是其分布的建模更加复杂。
本文提出的 TokenBridge 的意思就想结合这二者的优势:既做到保留离散 token 建模简单的优点,又可以保持连续 token 的强表示能力。
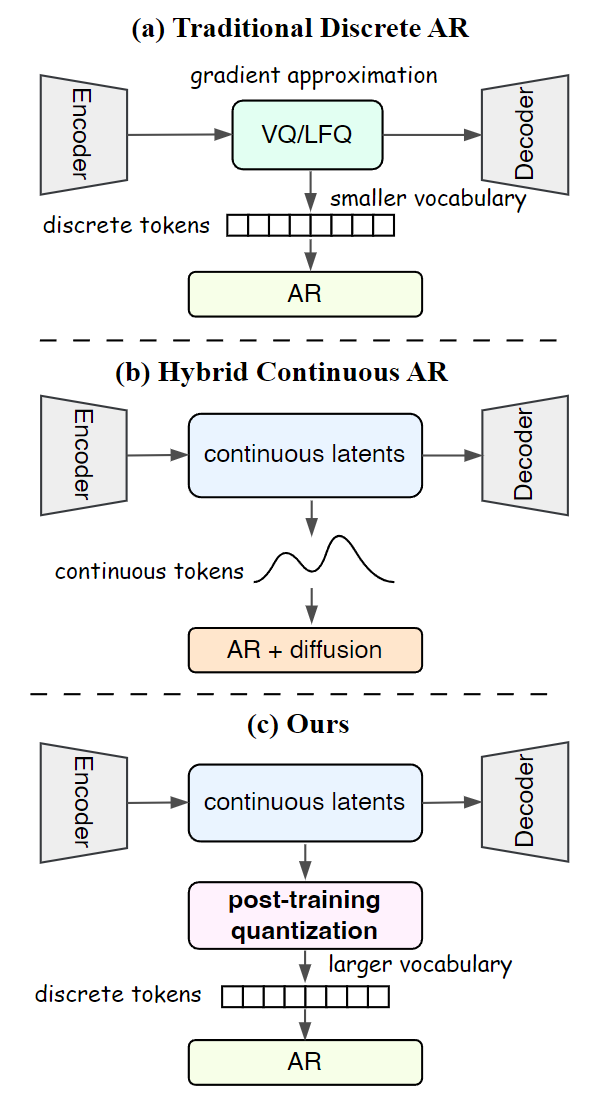
怎么做到的呢?将对 token 的离散化过程 (discretization) 与 tokenizer 的训练过程解耦。通过后训练量化 (post-training quantization),通过连续的表征直接量化出来离散 tokens。
TokenBridge 可以使用标准分类预测,同时可以实现与连续方法相当的重建和生成质量。TokenBridge 表明,桥接离散范式和连续范式可以有效利用两种方法的优势。

本文贡献
-
提出 TokenBridge,一种连接连续和离散 token 表征的新方法,使用交叉熵损失的标准自回归建模,保持离散方法的简洁性,但却可以实现与连续方法相当的视觉质量。 -
引入后训练量化直接离散化预训练的 VAE 特征,消除了 discete tokenizer 的优化不稳定性,同时保留了连续表征的高保真度。 -
提出一种 dimension-wise 的量化和预测策略,有效处理超大的词汇空间:消除 token 化过程中对大量 codebook 尺寸的需求,使得在如此大的空间进行自回归预测在计算上可行。
1TokenBridge:自回归生成中桥接连续和离散 token
论文名称:Bridging Continuous and Discrete Tokens for Autoregressive Visual Generation
论文地址:
http://arxiv.org/pdf/2503.16430
1.1 TokenBridge 研究背景
自回归视觉生成模型模型依赖 image tokenizer,将图像内容转换为离散或连续 token,然后通过 next token prediction 的范式通过自回归建模来进行。这种建模方法可以灵活地与多模态任务的文本 token 集成到一起。
但是问题也有,就是出在离散和连续 token 的选择上面,选择哪种 token 关系到生成质量以及整个流程的复杂性。离散 token 的方法采用了矢量量化技术 (vector quantization),在训练过程中将连续特征映射成离散 token。但是离散 token 的方法有两个问题:1) 量化本质上不可微,需要引入复杂优化和训练不稳定性的梯度近似。2) 离散 tokenizer 的 codebook 存在一个大小权衡的问题:codebook size 如果不大,则不能完全捕获精细的视觉细节,codebook size 如果很大,则 codebook 的利用率差,建模复杂度很高。
还有一类方法采用基于 VAE 的 tokenizer,借助 VAE 提供的连续特征来保留丰富视觉信息。但是连续的 latent token 不能用分类预测的自回归方法训练。因此一些方法比如 MAR 这种就使用诸如 Diffusion Loss 来替换分类目标函数完成建模。但是这样的做法会使得整个技术路线更加复杂。
因此,本文探索的目标就是如何连接连续 token 和离散 token,使得整个技术路线既可以保持连续 token 模型的强表征能力,又可以保持离散 token 模型的简洁性。
TokenBridge 的关键是:不按照惯例在 tokenizer 训练期间做量化,而是在完全训练好连续 tokenizer 之后,应用特征的后训练量化。
1.2 TokenBridge 的后训练量化
如图 3 所示,TokenBridge 从预训练的 VAE 提取的连续 latent 特征 \bm{X} \in \mathbb{R}^{H\times W\times C} 开始。目标是在保持丰富的视觉信息的同时对这些连续特征进行离散化。前文提到,一种方案是矢量量化技术 (vector quantization),但是用这种方案实现近乎无损的压缩,需要很大的 codebook (特征维度的指数量级),技术上令人望而却步。
TokenBridge 对每个 channel 独立地进行量化 (图 3,中间)。量化的时候,单独量化每个维度,而非整个向量。
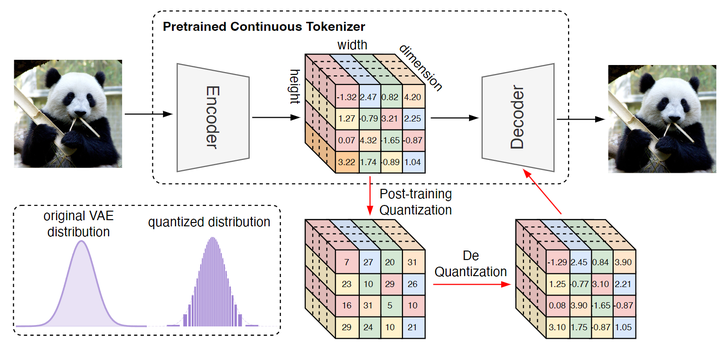
这种方法其实利用了 VAE 的两个优势:
-
VAE 在训练时由于 KL 约束,导致其特征的值域是有界的,这就允许量化所有特征时的 level 是有限的。 -
特征的近乎高斯分布允许进行高效非均匀量化,将更多的量化级别分配给频繁出现的值。
量化过程
对于特征图 中的特征向量 ,首先对每个维度进行归一化,让特征更接近高斯分布,然后确定实际边界 ,然后将它们映射到 :
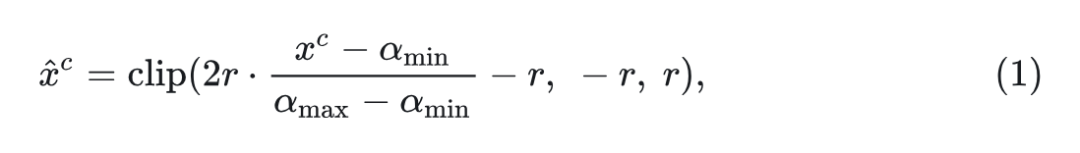
其中, 约束输入 位于边界 和 之间。这种归一化保留了相对分布,同时实现了基于高斯的量化。
接下来,通过将标准正态分布划分为概率相等的 个区域来建立量化边界 :
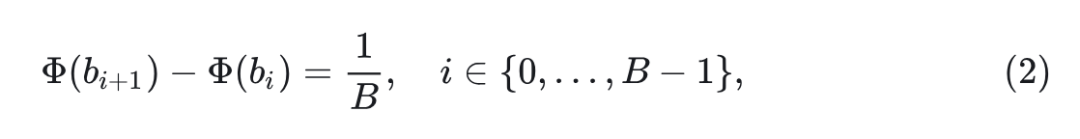
其中, 表示累积分布函数。这种非均匀方法将更多的量化 level 分配给高概率区域,高效利用有限的量化资源。对于每个区间 ,计算重建值作为该范围内的期望值:
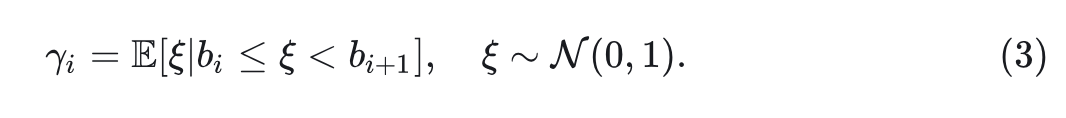
量化过程,即对每个归一化值 寻找量化索引值 :

这个过程在保持基本分布特征的同时,将连续特征转换为离散 token,从而实现标准分类预测。
反量化过程
由于自回归模型预测离散索引值,而 VAE 解码器需要连续特征,因此需要反量化。每个量化索引 映射到其对应的重构值 ,然后转换回原始特征范围:

这个过程可以直接使用预训练的 VAE 解码器,性能下降最小。完整的反量化过程如图 3 右侧所示。
尽管这个方法是由高斯分布驱动的,但作者发现使用线性量化,加上足够的细粒度,也可以表现良好,性能略低,表明方法对不同训练后量化方案的鲁棒性。
1.3 空间自回归主干 + channel 维度自回归头
TokenBridge 的后训练量化虽可以保住连续 token 的表征能力,但是带来计算量过大的问题。每个空间位置 个 channel,每个 channel 的值又有 种可能,共 种可能的组合。
这使得通过标准 softmax 分类在计算上是不可行的。一种简单的方法是独立建模和对每个维度进行分类,但本文实验表明,通道维度之间的显着相互依赖关系对于高质量的图像生成至关重要,使得这种并行独立预测不切实际。
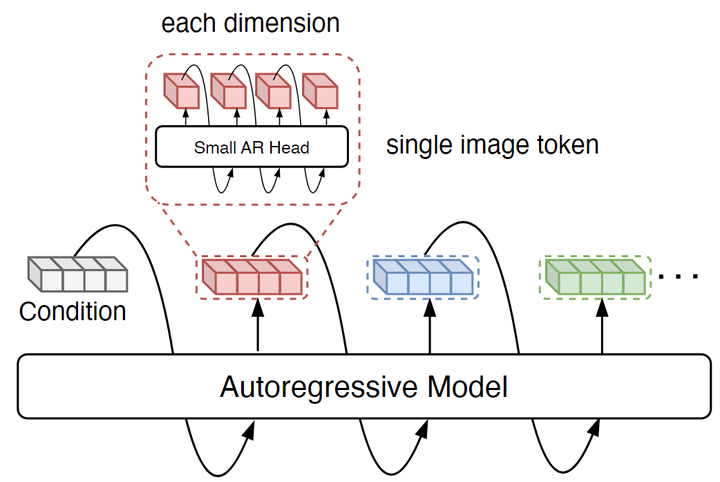
为了解决这个问题,本文引入了一个轻量级的自回归头,这个头对每个空间位置,在 channel 维度进行自回归预测:预测当前空间位置的下一个 channel 的值,如图4所示。
具体来说,对于给定的空间位置,对于量化索引向量 ,在通道维度上对它们的联合分布 进行建模:

其中, 表示通道 的量化值, $\boldsymbol{q}^{<c}$ 表示先前=”” channel=”” 的所有量化值,$z$=”” 表示空间自回归模型的上下文特征。<=”” p=””>
这个自回归头做的分类任务就是个 分类,因为只需要预测每个 channel 的分布即可,以先前生成的 token 和上下文特征为条件。
通过将 token 预测分解为一系列较小的分类问题,使得对指数级大的词汇空间进行建模计算上可行,并保留关键的通道间依赖关系。
作者还通过快速傅里叶变换 (Fast Fourier Transform, FFT) 根据维度低频能量的比例对维度进行排序。这是为了优先考虑那些携带更多低频信息的顺序,提高生成质量。
1.4 自回归生成框架
TokenBridge 将空间自回归生成与维度标记预测相结合。所有空间位置和通道的联合概率分布表示为:
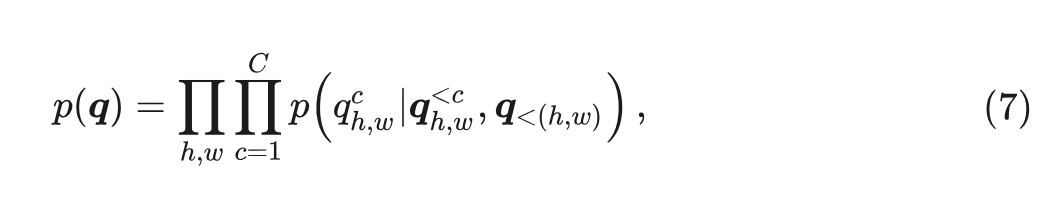
自回归主干的作用是为每个位置提供上下文特征,作为连接空间维度和 channel 维度自回归过程的中间表征。 在自回归头中充当 condition。TokenBridge 中,空间维度的自回归与 channel 维度的自回归被解耦开。自回归头在所有空间位置之间共享,只向模型添加了少量参数。
训练时
优化标准交叉熵损失 (dimension-wise token prediction),实现了简单的分类训练。
推理时
生成过程如下:
-
骨干网络根据先前生成的 token 自回归计算每个空间位置的上下文特征。 -
对于每个位置,自回归头顺序预测所有 channel 的值。 -
在每个空间 token 完全生成后,立刻将离散索引重新反量化为连续特征,然后将它们输入到空间自回归模型中以进行下一个位置的预测。这个反量化步骤很重要,因为自回归模型将连续特征表示作为输入条件,确保网络始终接收原始 VAE latent 空间中的特征,从而在保持离散 token 预测优势的同时保持丰富的表示能力。
在生成完成后,使用预训练的 VAE 解码器将所有预测的特征解码为图像。
1.5 实验设置
作者使用的 VAE 是 KL-regularized 的 LDM tokenizer,预训练权重来自 MAR 的。这个 tokenizer 使用 16 维 channel 向量将 256×256 图像映射到 16×16 个 token。
量化的时候,使用 ,对于自回归模型,为了与连续方法进行比较,采用了 MAR 中的掩码自回归模型架构。默认 Transformer 由 32 个 Block 组成,宽度为 1024 (L 模型,~400M),用于消融研究,而最终结果使用更大的 H 模型 (40 个 Block 和 1280 个宽度,~910M)。
1.6 Tokenizer 实验结果
作者首先对比了本文的 tokenizer 与其他 tokenizer 的对比实验结果,如图 5 所示。
连续 tokenizer:使用 MAR 的 VAE。
离散 tokenizer:使用 LlamaGen 的 VQGAN tokenizer,OpenMAGVIT2 的 LFQ。
如图5所示,连续 tokenizer 保留了更多的细节,特别是在文本和面部特征中,而离散 tokenizer 经常会遇到困难。但本文的离散 tokenizer 实现了与其连续 tokenizer 相当的重建质量。

图 6 显示了量化 level 数 对重建质量的影响。可以观察到,全局的结构在所有量化 level 上都保持良好保留,差异主要在于细节的保留程度。
当 时,会发生显着的信息损失( ),可见纹理和边缘的伪影。 当 时,质量显着提高( ),只有很小的细节损失可见 当 和 时的重建在视觉上与原始输入无法区分, 的结果( )可以完美匹配连续 VAE。

1.7 生成实验结果
自回归生成策略
如图7和8所示,本文提出的 dimension-wise 的自回归生成策略显著提高了生成质量。结果说明建模 channel 之间的依赖关系对于高质量的图像生成至关重要。


量化 level 的影响
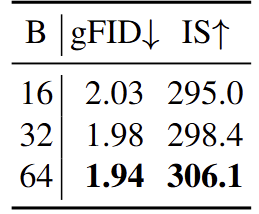
作者研究了量化粒度如何影响生成性能。如图9所示,生成质量随着更精细的量化而不断提高。即使使用粗略的量化,本文在 上也可以实现合理的质量( ),而更精细的量化产生了最好的结果( 的 gFID=1.94)。这种结果与重建实验一致,并确认生成受益于更细粒度的离散化。
自回归头尺寸的影响
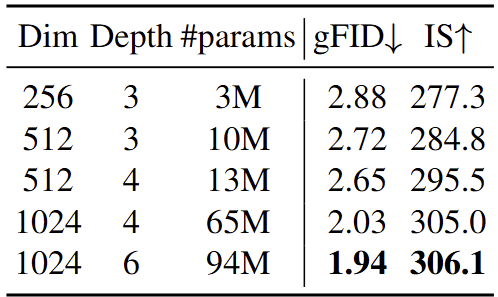
作者分析了自回归头对生成质量的影响。如图10所示,即使只用 3M 参数也能达到合理的质量 (gFID=2.88),证明了方法的有效性。尺寸的增加不断提高性能,最大的配置 (94M 参数) 取得了最好的结果(gFID=1.94)。
与其他方案对比
图 11 将本文的方法在 ImageNet-256 上与典型视觉生成方法进行了比较。作者将这些方法分为3组:传统的离散 token 的模型、连续 token 的模型,以及本文后训练量化的离散 token 模型。

本文实现了很好的 FID 分数,比大多数方法更好。例如,具有 3.1B 参数的 LlamaGen 的 FID 为 2.18,而 Ours-L 的 1.76 只有 486M 参数。与连续 token 方法相比,Ours-L 大大优于 GIVT (FID 1.76 vs 3.35),Ours-H 比 FlowAR-H (FID 1.65) 取得更好的结果,尽管后者的参数几乎两倍。
与采用 Diffusion Loss 的 MAR 直接比较,Ours-L 实现了与具有相似参数的 MAR-L 相当的性能。具体而言,Ours-H 在 FID (1.55) 上与 MAR-H 相当,同时以更少的参数实现了更高的 IS 和 Recall。
这些结果说明 TokenBridge 方法有效地弥合了离散和连续 token 的表征,既可以实现与连续方法相当的高质量视觉生成结果,也可保持离散方法 cross-entropy loss 建模的简洁性。

(文:极市干货)