

在人工智能领域,尤其是大规模语言模型(LLMs)的发展中,数据标注一直是制约模型性能提升的重要因素。传统的强化学习方法依赖于明确的奖励信号,而在实际应用中,尤其是推理阶段,往往无法获取这些信号。为了解决这一问题,清华大学和上海人工智能实验室的研究团队提出了一种创新方法——测试时强化学习(Test-Time Reinforcement Learning,TTRL)。TTRL通过在无标签数据上利用强化学习技术优化模型性能,为AI模型的自我演化提供了一种全新的思路。
一、项目概述
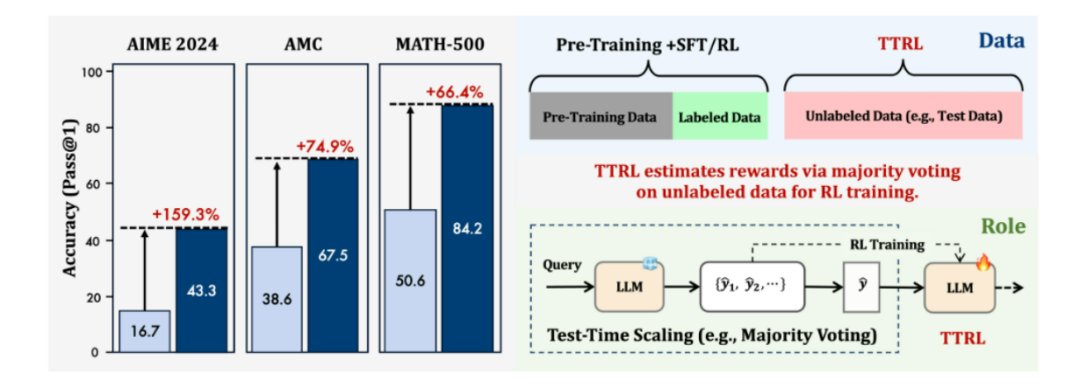
TTRL(Test-Time Reinforcement Learning)是一个开源项目,旨在探索在不具备显式标签的数据上进行推理任务的大规模语言模型(LLMs)的强化学习(RL)。该项目的核心在于,在推理过程中无法访问真实标签信息时,如何对奖励进行有效估计。TTRL通过利用测试时间缩放(Test-Time Scaling,TTS)中的常见实践,如多数投票(majority voting),来作为RL训练的奖励信号,从而在不依赖真实标签的情况下实现强化学习。TTRL的核心目标是使模型能够利用自身的先验知识,在无标签数据上自主优化,提升其在各种推理任务中的性能。
二、技术原理
(一)生成候选输出
对于给定的输入问题,LLM生成多个候选回答。这些候选回答是通过重复采样模型得到的。TTRL利用模型的采样能力,在不依赖外部标注的情况下,生成多样化的候选输出,为后续的奖励估计提供基础。
(二)估计真实标签
使用多数投票等方法从候选回答中估计出最可能的真实标签。这一步是奖励估计的关键,因为它决定了模型在后续优化过程中应该追求什么样的目标。多数投票机制通过统计多个候选输出的共识,为模型提供了一个近似的真实标签。
(三)计算奖励信号
根据估计出的真实标签和候选回答之间的差异,计算每个候选回答的奖励信号。奖励信号的大小反映了候选回答与真实标签之间的接近程度。TTRL通过规则定义奖励函数,将候选输出与估计标签的匹配程度转化为奖励信号,从而为模型优化提供方向。
(四)优化模型参数
利用计算出的奖励信号,通过梯度上升等方法优化LLM的参数,使模型在未来生成更接近于真实标签的回答。TTRL通过调整模型参数,使模型在不断学习中逐步提升性能。
(五)重复迭代
上述过程不断重复,直到模型性能达到收敛或达到预设的训练轮次。TTRL通过迭代优化,使模型在无标签数据上持续学习和改进。
三、主要功能
(一)创新性
TTRL提出了一种新颖的在不依赖真实标签的情况下进行强化学习的方法,为无标签数据的推理任务提供了新的解决思路。它打破了传统强化学习对显式奖励信号的依赖,使模型能够在无监督的环境下自主学习。
(二)有效性
实验证明,TTRL在各种任务和模型上都能显著提升性能。例如,它能够将Qwen-2.5-Math-7B在AIME 2024上的pass@1性能提升约159%。这一显著的性能提升验证了TTRL在实际应用中的有效性。
(三)通用性
TTRL不仅限于特定的模型或任务,而是可以广泛应用于各种大规模语言模型的强化学习。它适用于多种推理任务,如数学推理、自然语言处理和多模态任务等。
(四)易于实现
TTRL的实现主要通过对奖励函数的修改即可快速完成,为研究人员和工程师提供了极大的便利。其简洁的实现方式降低了技术门槛,使得更多的研究者能够快速应用和扩展TTRL。
四、应用场景
(一)数学推理
在数学推理任务中,TTRL能够显著提升模型的性能。例如,在AIME 2024数学竞赛中,TTRL将Qwen-2.5-Math-7B模型的pass@1性能从16.7%提升至43.3%,实现了近159%的跃升。TTRL能够帮助模型更好地理解和解决复杂的数学问题,提升其在数学推理任务中的准确性和可靠性。
(二)自然语言处理
TTRL可以应用于自然语言处理中的各种任务,如文本分类、情感分析等。通过在无标签数据上进行强化学习,TTRL能够提升模型的泛化能力和推理能力。它可以帮助模型更好地理解和处理自然语言,提高其在文本分析任务中的性能。
(三)多模态任务
TTRL还可以扩展到多模态任务中,例如在图像和文本联合推理任务中,通过多数投票机制估计奖励信号,提升模型的性能。TTRL能够使模型在处理多模态数据时更加智能和高效,拓展了其在多领域应用的潜力。
五、快速使用
以下是官方提供的,在AIME 2024上重现Qwen2.5-Math-7B的示例:
git clone git@github.com:PRIME-RL/TTRL.gitcd codepip install -r requirements.txtpip install -e .bash scripts/ttrl_aime_grpo_7b.sh ttrl_dir qwen_model_dir wandb_key
通过上述代码,可以快速搭建TTRL环境并开始实验。首先克隆代码仓库,然后安装所需的依赖包。最后,通过运行脚本启动TTRL训练过程。用户只需准备相应的模型目录和Weights & Biases的API密钥,即可在本地环境中复现TTRL的实验结果。
六、结语
TTRL作为一种创新的强化学习方法,为无标签数据的推理任务提供了一种有效的解决方案。它不仅显著提升了模型的性能,还拓宽了强化学习的应用范围。对于希望在不依赖大量标签数据的情况下提升模型性能的研究人员来说,TTRL无疑是一个值得关注的开源项目。TTRL的提出为AI模型的自我优化和持续学习提供了一种新的可能,预示着在无监督学习领域将有更多的创新和突破。
七、项目地址
GitHub地址:https://github.com/PRIME-RL/TTRL
论文地址:https://arxiv.org/abs/2504.16084
(文:小兵的AI视界)