
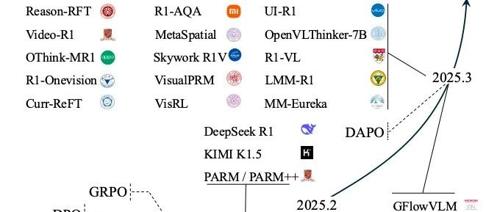
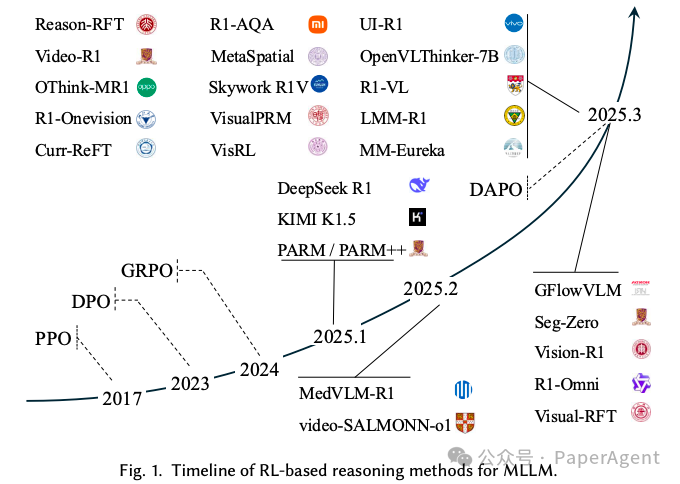

MLLMs与MM-CoT
-
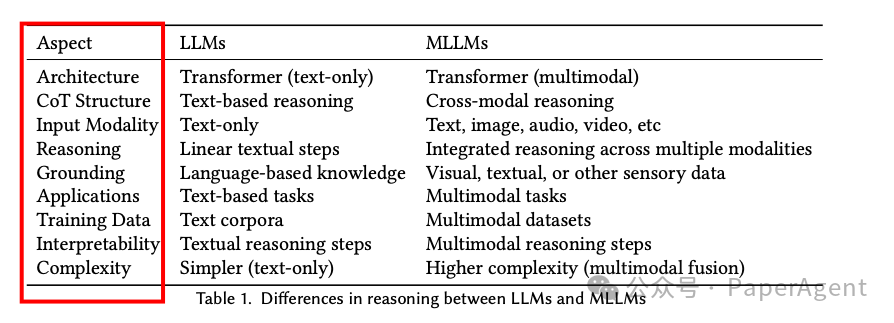
多模态大型语言模型(MLLMs):将大型语言模型(LLMs)与其他模态(如视觉、音频和视频)的模型结合,以处理多种模态的数据。MLLMs通过将LLMs作为核心认知引擎,并利用其他模态的基础模型提供高质量的非文本数据表示,从而扩展了LLMs的能力。
-
多模态链式推理(MM-CoT):在多模态推理任务中,模型生成中间推理步骤(链式推理),这些步骤可以仅依赖于文本信息,也可以整合多模态信号。MM-CoT的目标是通过逐步推理解决复杂问题,同时在推理过程中融入多模态信息。
强化学习(RL)
-
策略优化方法:
-
近端策略优化(PPO):通过最大化代理目标来优化LLMs,同时引入裁剪机制以稳定训练。PPO需要同时训练策略模型和价值模型,这在模型参数或标记数量较大时会带来显著的计算需求。
-
REINFORCE留一法(RLOO):省略了价值模型和GAE的使用,直接利用蒙特卡洛方法计算基线,通过留一法减少策略梯度估计的方差。
-
组相对策略优化(GRPO):通过直接比较生成的响应组来优化模型,省略了价值模型,通过相对奖励来评估响应的质量,减少了对硬件资源的需求。
-
奖励机制:
-
结果导向奖励机制(ORM):仅根据最终输出的正确性来评估模型,奖励信号稀疏且延迟,难以解决长期信用分配问题。
-
过程导向奖励机制(PRM):强调模型在推理过程中的中间行为,提供更细粒度的监督,但设计过程奖励依赖于对中间推理步骤的准确评估,具有挑战性。
-
训练效率:
-
课程强化学习:通过逐步引入任务,帮助模型逐步积累知识,提高在复杂任务上的收敛速度和性能。
-
数据高效学习:通过优先采样和选择高质量样本,提高样本效率,减少不必要的计算开销。
深入探讨了强化学习(RL)算法在大型语言模型(LLMs)和多模态大型语言模型(MLLMs)中的关键设计和优化策略:无价值方法(value-free)和基于价值的方法(value-based)。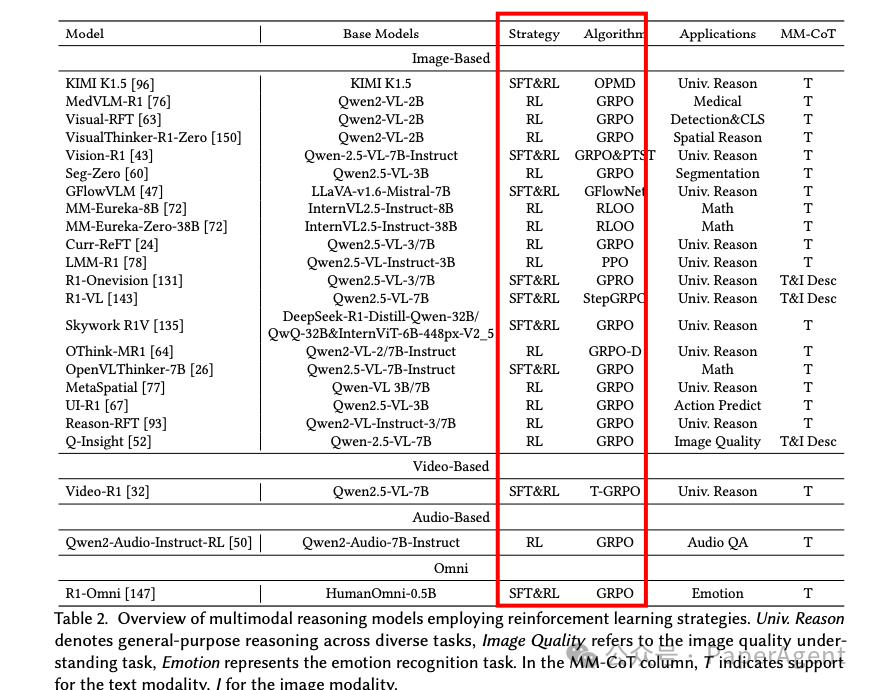
2.1 Value-Free 方法
无价值方法通过直接优化策略,而无需计算价值函数,从而简化了训练过程并提高了计算效率。这些方法在处理长推理链(long-CoT)任务时表现出色,但可能会遇到熵崩溃(entropy collapse)和奖励噪声(reward noise)等问题:
-
GRPO(Group Relative Policy Optimization):
-
核心思想:通过比较生成的响应组来优化模型,避免了复杂的价值模型训练。
-
挑战:熵崩溃和奖励噪声,可能导致模型生成低质量的输出。
-
优化策略:引入动态采样机制,避免梯度信号消失;采用token-level策略梯度损失,确保长序列中的每个token都能公平地贡献梯度。
-
DAPO(Dynamic Asymmetric Policy Optimization):
-
不对称裁剪策略:通过解耦裁剪上下界,增强低概率token的探索能力。
-
动态采样:过滤掉准确率为0或1的样本,确保每个批次中都有有效的梯度信号。
-
token-level策略梯度损失:确保长序列中的每个token都能公平地贡献梯度。
-
过长奖励塑形:通过逐步增加长度依赖的惩罚,减少奖励噪声,稳定训练过程。
-
核心思想:在GRPO的基础上,引入不对称裁剪策略、动态采样机制、token-level策略梯度损失和过长奖励塑形(overlong reward shaping)。
-
优化策略:
-
Dr.GRPO(Debiased Group Relative Policy Optimization):
-
消除长度归一化:避免模型偏好生成更长的错误响应。
-
消除标准差归一化:确保不同难度的问题在优化过程中被平等对待。
-
核心思想:通过消除GRPO中的长度偏差和问题难度偏差,提高模型的公平性和稳定性。
-
优化策略:
-
CPPO(Completion Pruning Policy Optimization):
-
剪枝策略:仅保留具有最高绝对优势值的top-k完成项,减少冗余计算。
-
动态完成分配策略:结合剩余剪枝的完成项和新查询的高质量完成项,充分利用GPU的并行计算能力。
-
核心思想:通过剪枝策略减少计算开销,同时保持或提高模型性能。
-
优化策略:
3.2 Value-Based方法
基于价值的方法通过精确的逐步信用分配来优化策略,适合处理复杂推理任务。这些方法在长推理链任务中面临挑战,但通过创新的优化技术,可以提高训练的稳定性和性能:
-
PPO(Proximal Policy Optimization):
-
Open-Reasoner-Zero:通过简单的规则化奖励函数和大量的训练数据,显著提高了响应长度和基准性能。
-
VC-PPO:通过值初始化偏差和解耦GAE(Decoupled-GAE)来优化PPO,减少训练过程中的方差。
-
核心思想:通过最大化代理目标来优化策略,同时引入裁剪机制以稳定训练。
-
挑战:在长推理链任务中,PPO可能会遇到训练不稳定和性能下降的问题。
-
优化策略:
-
VC-PPO(Value Corrected PPO):
-
值预训练:通过离线训练价值模型,确保其能够准确估计预期回报。
-
解耦GAE:通过为策略和价值优化分别设置不同的𝜀值,独立优化偏差-方差权衡。
-
核心思想:通过值预训练和解耦GAE来优化PPO,减少训练过程中的方差。
-
优化策略:
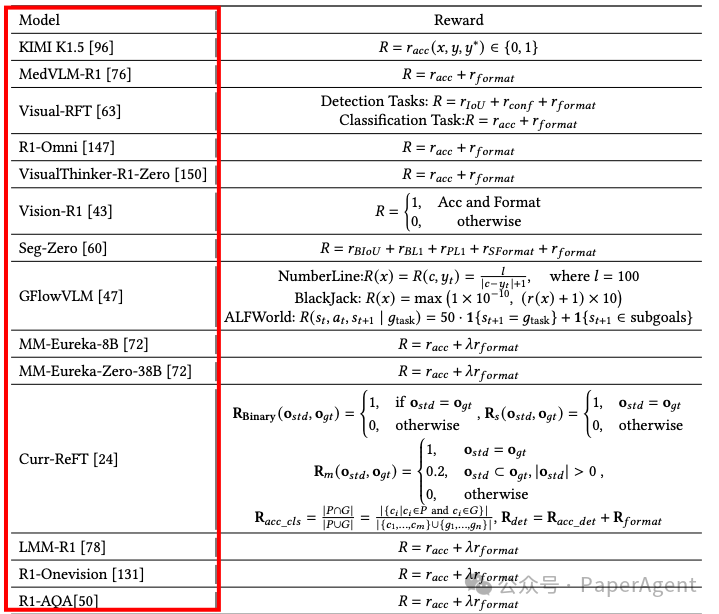

三、RL的多模态大模型推理
系统回顾了基于强化学习(RL)的多模态大型语言模型(MLLMs)推理的最新进展,涵盖了关键的算法设计、奖励机制创新以及实际应用。
3.1 从LLMs到MLLMs的RL训练范式
-
标准化R1训练范式:
-
Kimi K1.5:通过在线策略镜像下降(OPMD)算法,将强化学习应用于MLLMs,增强了其在多模态领域的推理能力。
-
DeepSeek R1:通过验证性奖励机制(Verifiable Reward Mechanism, VRM),展示了如何通过简单的规则化激励机制和轻量级的RL算法,使LLMs能够自主发展复杂的推理能力。
-
ORM(Outcome Reward Mechanism):基于最终输出的正确性来评估模型,适用于数学问题解决和代码生成等任务,但存在奖励信号稀疏和延迟的问题。
-
PRM(Process Reward Mechanism):通过评估推理过程中的中间步骤来提供更细粒度的监督,有助于提高模型的逻辑一致性和可解释性。
-
MLLMs中的R1训练范式:
-
MedVLM-R1:将DeepSeek R1的训练范式扩展到医学领域的视觉问答任务中,通过显式的推理路径提高预测准确性和泛化能力。
-
Vision-R1:通过逐步推理抑制训练(PTST)策略,逐步扩展推理链的长度,同时分离格式和准确性奖励,缓解了过思考的问题。
-
LMM-R1:采用两阶段训练策略,先在纯文本数据上进行RL训练,再扩展到图像-文本数据,以提高模型在视觉感知和其他多模态任务中的泛化能力。
3.2 多模态感知中的奖励机制设计
-
结果导向奖励机制(ORM):
-
任务导向奖励策略:根据任务的内在属性设计奖励,如图像分类任务使用标签匹配作为奖励信号,目标检测任务优化IoU(交并比)。
-
跨模态交互奖励策略:通过联合评估不同模态的输出来促进更积极的跨模态交互,例如UI-R1通过评估预测的动作类型、参数选择和输出格式的有效性来建立模态之间的对齐反馈。
-
过程导向奖励机制(PRM):
-
结构化奖励框架:通过引入结构化奖励,如逻辑一致性、信息完整性和引用可靠性,来提高模型的可解释性和用户信任度。
-
R1-VL:通过StepGRPO框架,引入StepRAR(关键中间推理步骤评估)和StepRVR(推理链逻辑连贯性评估)两个结构化奖励组件,显著提高了模型在复杂任务中的逻辑一致性。
3.3 训练效率与稳定性
-
课程学习:
-
Kimi K1.5:通过课程采样逐步训练模型,从简单任务到复杂任务,同时结合优先采样,优化学习过程。
-
Curr-ReFT:将训练分为三个阶段:二元分类、多项选择和开放式问答,每个阶段都由特定任务的奖励函数引导,逐步发展模型的推理能力。
-
样本效率:
-
Reason-RFT:通过GPT-4o过滤低质量或错误样本,重构高质量数据集,确保数据质量和适用性。
-
Skywork R1V:通过自适应长度链式推理蒸馏和混合优化框架,动态调整推理链长度,减少对大规模标注数据的依赖。
-
灾难性遗忘:
-
Curr-ReFT:通过拒绝样本的自我改进机制,选择性地从高质量的多模态和文本示例中学习,以保持MLLMs的基本能力,缓解灾难性遗忘问题。
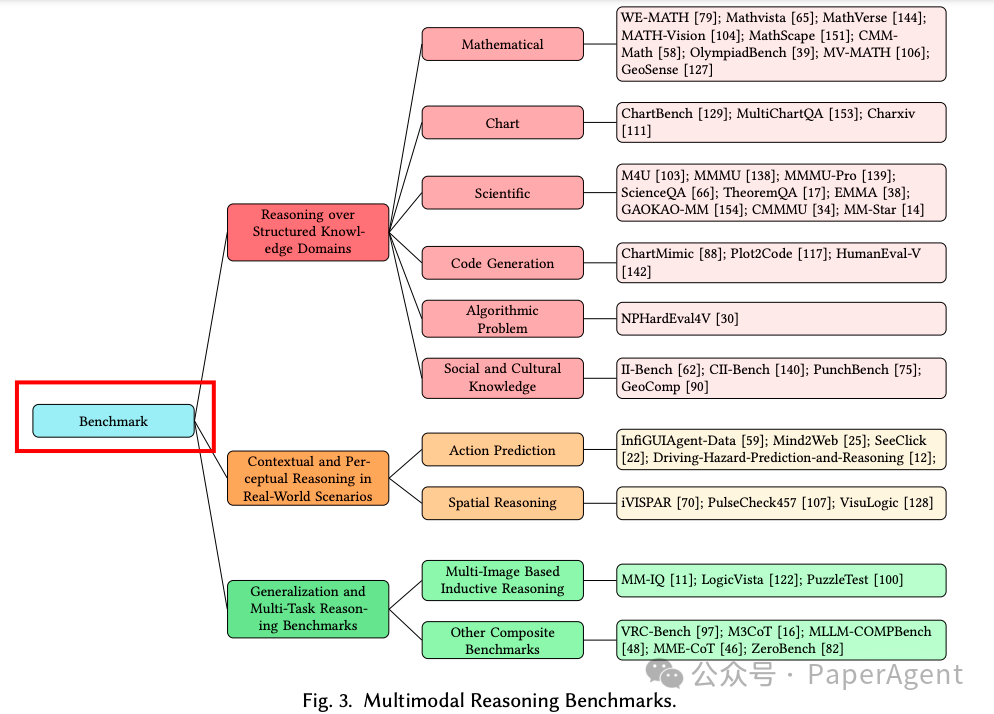
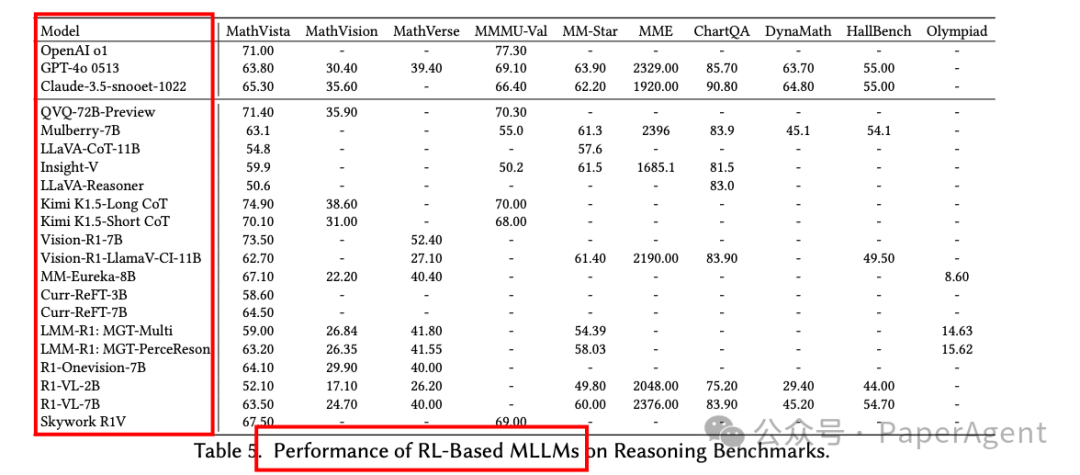

https://arxiv.org/pdf/2504.21277Reinforced MLLM: A Survey on RL-Based Reasoning in Multimodal Large Language Models
(文:PaperAgent)