



任务背景以及 Motivation
随着深度视觉-语言预训练的飞速发展,文本驱动的行人检索(Text-based Person Search)已成为公共安全与智能监控领域的热门方向。
然而,现有方法为了解决隐私保护和繁琐的人工标注,往往在大规模合成数据集进行预训练与微调。尽管理论上合成数据的数量是无限的仍面临两大核心挑战:
(1)数据冗余:海量合成的行人图像文本对虽可无限扩增,但噪声多、对齐差,使性能提升边际效益递减;
(2)训练庞大:全模型预训练+微调参数量超两亿,训练时长长、算力负担重。
针对上述难题,北京理工大学、澳门大学与新加坡国立大学研究团队联合提出 Filtering-WoRA 范式,首次从“数据精炼+轻量微调”双轮发力,实现无需全量训练的高效行人检索:

论文标题:
From Data Deluge to Data Curation: A Filtering-WoRA Paradigm for Efficient Text-based Person Search
论文链接:
https://dl.acm.org/doi/10.1145/3696410.3714788
项目主页:
https://github.com/JT-Sun/Filtering-WoRA

主要创新
双阶段数据过滤:基于 BLIP-2 跨模态检索能力,先在 1.51M 合成数据集 MALS 的图像文本对上按相似度 top50 剔除了 21% 噪声,构建 1.19M 的 Filtered-MALS 数据集用于预训练;再在 CUHK-PEDES 数据集真实对上剔除 10%,得到更纯净的微调集。
Weighted Low-Rank Adaptation(WoRA):为了减少模型参数并提高计算速度,我们选择冻结部分预训练中的权重,通过优化在自适应过程中发生变化的秩分解矩阵,间接训练神经网络中的一些密集层。
在 LoRA 低秩分解基础上引入可学习标量 α、β,同时调控预训练权重与低秩增量的幅度与方向,以便于修改权重矩阵和秩分解矩阵。

核心技术解析
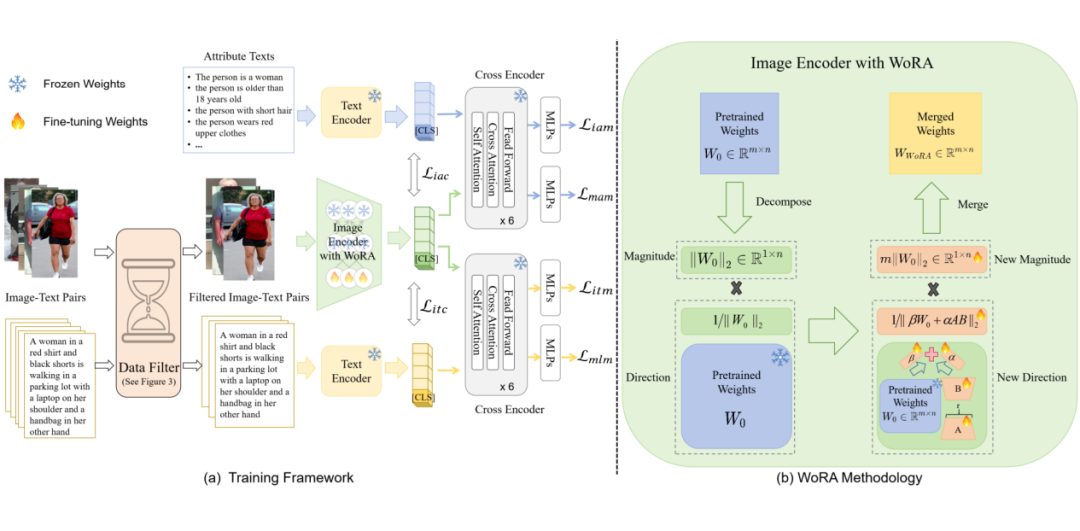
▲ 框架概述
Filtering-WoRA 范式:首先应用我们的数据过滤方法得到过滤后的训练图像-文本对。然后,我们根据关键词将文本扩充为属性文本。我们通过图像编码器、文本编码器和交叉编码器提取相应的特征训练文本-图像匹配和属性-图像匹配任务总共六个损失目标。
由于图像编码器消耗了大部分的 GPU 内存和时间。因此在图像编码器之中我们应用了 WoRA 方法,将预训练的权重分解为幅度和方向分量,并在 LoRA 的基础上同时添加 alpha 和 beat 两个可学习参数,从而达到更新幅度和方向分量。
框架的核心技术主要集中在两个方面:
1. 两阶段数据过滤(Filtering)
问题:海量合成的行人图像文本数据集存在冗余和噪声。
方案:构建两阶段数据过滤架构,在预训练和微调阶段分别提取每对图文的自相似度与干扰相似度,基于特点阈值保留高质量行人图像文本对,提升信噪比。

▲ 数据过滤过程
我们首先使用 Blip-2 从输入的图像文本对(I,T)和干扰文本 TC(CUHK-PEDES)中提取特征。接下来,我们计算相似度并对结果进行相应的排序,最终生成过滤后的数据集。

数据过滤的可视化。图像左侧部分显示了经过我们的筛选策略后保留的高质量图像及其对应的红色文本描述,而右侧的人物图像则表示被过滤掉的低质量图像文本对,这些文本对超过了阈值。
效果:在预训练阶段,从 MALS 数据集中筛选出 79% 高质量数据;在微调阶段,从 CUHK – PEDES 数据集中筛选出 90% 高质量数据,有效去除噪声数据,提升数据质量和训练效率。
2. 加权低秩适配(WoRA)
问题:TBPS 通过大规模合成数据集的预训练-微调范式存在计算成本高,训练参数过多的情况。
方案:受 LoRA 和 DoRA 启发,引入新的可学习参数 α 和 β,通过调整预训练权重的幅度和方向进行高效微调。下面是 WoRA 的公式表达:

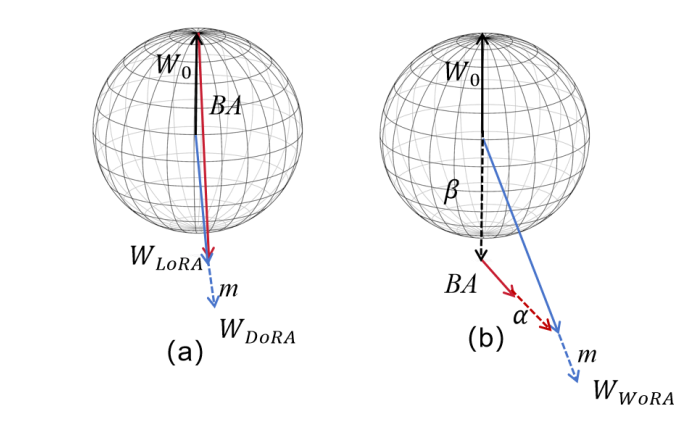
LoRA、DoRA 和我们提出的 WoRA 的直观比较,我们只需要小幅度的 BA 变化即可达到所需效果。
我们在 WoRA 中应用了两个可学习参数,即 α 和 β,它们可以有效地调整向量,并提供更好的灵活性。
效果:相比 LoRA 和 DoRA,WoRA 学习性能更优,虽训练时间略长,但提升效果明显,且空间复杂度与 DoRA 相同。WoRA 仅更新极少参数,即可灵活实现正/负相关与幅度微调,大幅缩减微调开销。

实验结果
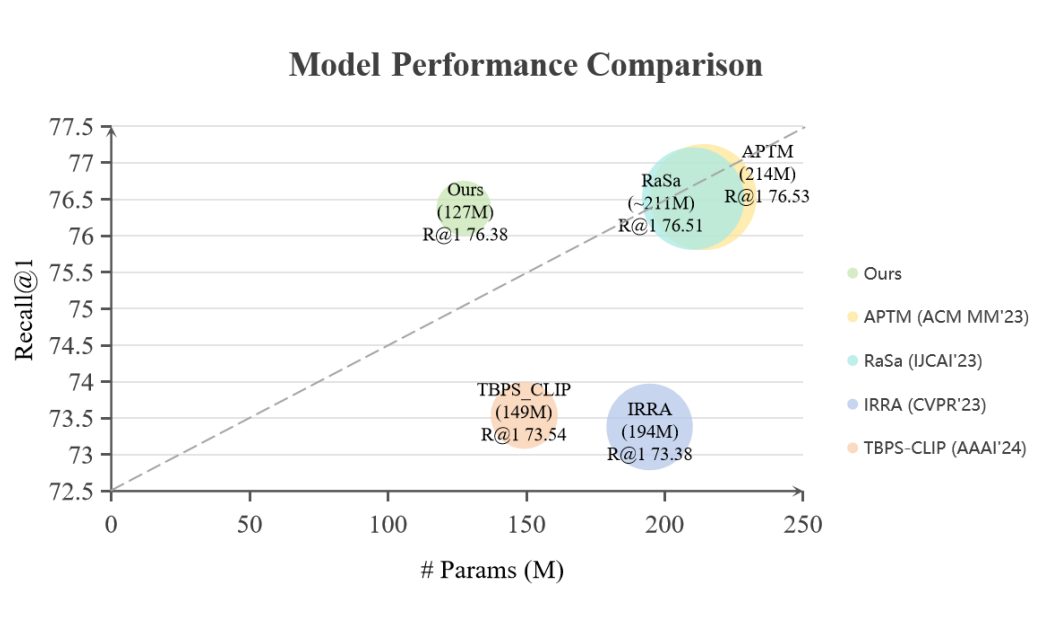
我们的 Filtering-WoRA 方法与最近方法的性能和参数比较。可以看到我们的方法在保持模型 Recall@1 性能的同时大大缩减了模型参数。
1. 定量结果:
下面是应用我们的 Filtering-WoRA 范式在三个数据集 CUHK-PEDES,RSTPReid,和 ICFG-PEDES 上面取得的定量结果:
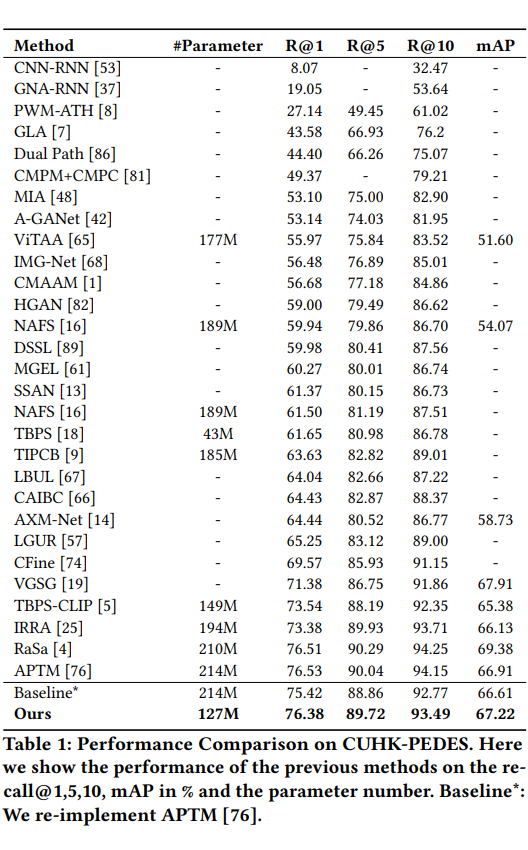


检索性能:CUHK-PEDES Recall@1 75.42%→76.38%(↑0.96%),mAP 66.61%→67.22%(↑0.61%)在 RSTPReid 与 ICFG-PEDES 同样取得或超越现有 SOTA 水平。
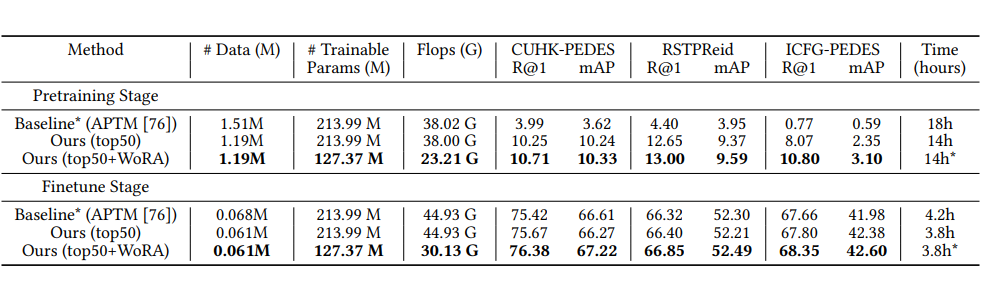
与 APTM 方法在 CUHK-PEDES、RSTPReid 和 ICFG-PEDES 数据集上的召回率 @1 和 mAP 结果进行了比较。同时,我们还比较了模型的数据量、参数(M)和 Flops(G)。
2. 训练效率:预训练 + 微调总时长由 23h 降至 18h,节省 19.82%;
3. 资源消耗:参数量 214M → 127M(↓41%),FLOPs 38G → 23G(↓39%);
4. 可视化:

使用我们的方法进行文本查询的定性人物搜索结果,根据匹配概率从左到右按降序排列。绿色框中的图像为正确匹配,红色框中的图像为错误匹配。绿色文本表示我们的结果匹配成功。

总结与未来方向
Filtering-WoRA 打破大规模合成与全模型微调的瓶颈,实现了更少数据 + 更少参数 + 更高精度的行人检索新范式。未来可继续探索:
-
动态阈值选择策略,实现对不同数据分布的自适应过滤;
-
扩展其他大规模预训练-微调任务,如属性识别、姿态估计、结合大模型等。
(文:PaperWeekly)