

Sora、可灵等视频生成模型令人惊艳的性能表现使得创作者仅依靠文本输入就能够创作出高质量的视频内容。然而,我们常见的电影片段通常是由导演在一个场景中精心布置多个目标的运动、摄像机拍摄角度后再剪辑而成的。例如,在拍摄赛车追逐的场景时,镜头通常跟随赛车运动,并通过扣人心弦的超车时刻来展示赛事的白热化。而如今的视频生成模型无法实现 3D 场景中目标、相机联合控制的文本到视频创作,限制了 AI 影视制作的能力。
近期,可灵研究团队在「3D 感知可控视频生成」领域做出了首次尝试,推出了电影级文本到视频生成框架 CineMaster,允许用户在提供全局文本描述的基础上,通过提出的交互式工作流辅助用户像专业导演一样布置场景,设定目标与相机的运动,指导模型生成用户想要的视频内容。目前该论文已录用于 SIGGRAPH 2025。

-
论文标题:CineMaster: A 3D-Aware and Controllable Framework for Cinematic Text-to-Video Generation
-
论文地址:https://arxiv.org/abs/2502.08639 -
项目主页:https://cinemaster-dev.github.io/

CineMaster 支持 3D 感知的目标、相机运动控制
a) 目标相机联合控制

b) 目标运动控制

c) 相机运动控制

可以观察到,CineMaster 可以根据用户提供的多模态细粒度的控制信号生成期望的视频,支持较大幅度的目标、相机运动的可控生成。
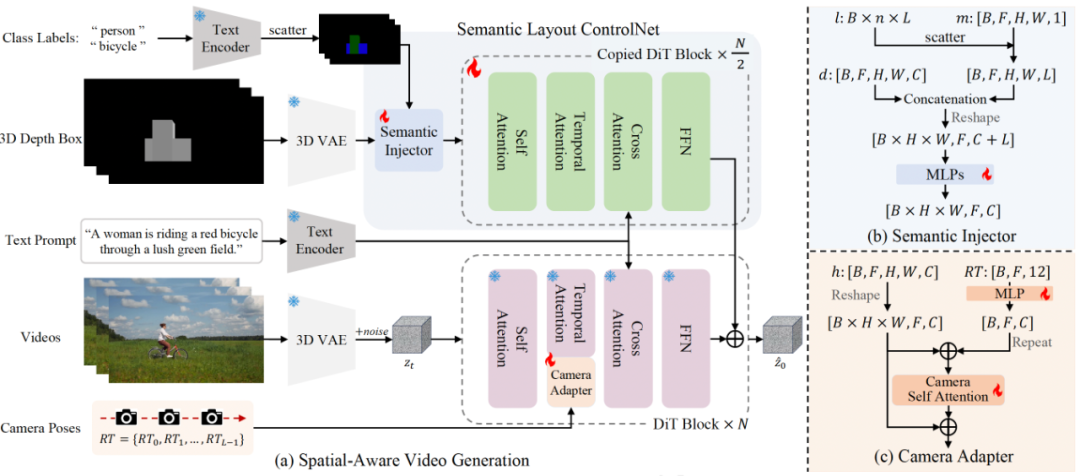
CineMaster 框架
CineMaster 通过两阶段的工作流,实现高度可控的文本到视频生成:
阶段 1:构建 3D 感知的控制信号。用户可以通过交互式界面在 3D 空间中调整物体的边界框(3D Bounding Box)和摄像机位置,这个过程类似于真实的电影拍摄过程,即导演多次调整演员在场景中的排布和相机的运动。随后,导出相机轨迹和每帧的投影深度图,作为后续生成的条件信号。
阶段 2:如图所示,该方法框架通过语义布局 ControlNet 的架构集成了物体的运动控制信号和物体的类别标签信息,从而明确地控制每个目标的运动。此外,通过 Camera Adapter 集成了相机运动控制信号表示视频序列的全局运动。
CineMaster 训练数据构建流程
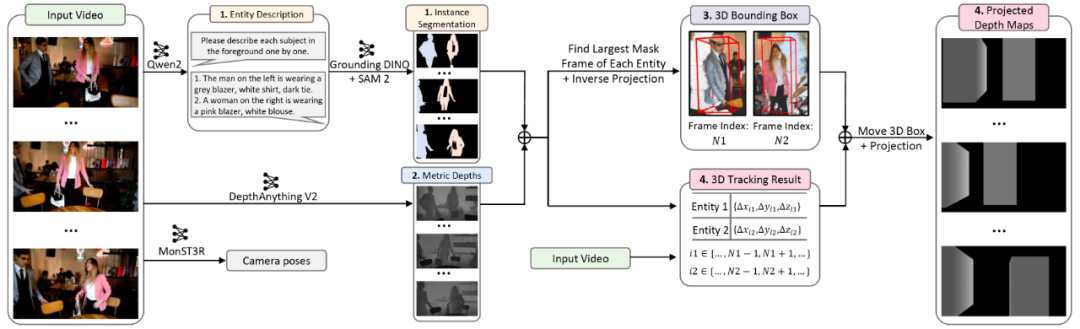
数据构建流程旨在从任意视频中提取 3D bounding boxes、类别标签、视频相机轨迹,主要包含 4 个步骤:
-
通过 Qwen2-VL 增强的实体描述提升开放词汇目标检测模型 Grounding DINO 的性能,并通过 SAM v2 实现视频实例分割;
-
利用 DepthAnything V2 估计视频的绝对深度;
-
在每个目标的 Mask 最大帧通过深度投影分割结果到点云空间计算 3D bounding box;
-
访问由 Spatial Tracker 实现的 3D 点跟踪结果,计算所有目标在视频序列中的 3D bounding box,并投影整个 3D 场景得到深度图。
对比结果

上图中研究者将 CineMaster 与基线方法进行了比较。据观察,基线方法无法显式地关联给定的运动条件和相应的目标,也存在目标运动和相机运动耦合的问题。而 CineMaster 可以合成符合文本提示、目标、相机控制信号的高质量视频。请访问项目主页查看视频结果。
总结
在本文中,研究者期望为用户提供强大的 3D 感知的可控视频生成能力,让用户能够像专业导演一样创作。为此,首先设计了一个 3D 感知的交互工作流,允许用户直观地编辑目标和相机的运动;随后开发了一个多模态条件控制视频生成模型,生成用户想要的视频。此外,该方法精心设计了一套从任意视频中提取 3D 控制信号的数据构建流程,为 3D 可控视频生成领域的研究提供了实践经验。
更多细节请参阅原论文。
快手视觉生成与互动中心 (Kuaishou Visual Generation and Interaction Center)是「可灵」视频生成大模型背后的核心团队,主要技术方向是视觉内容生成和多模态互动。我们致力于通过计算机视觉/图形学、多模态机器学习、XR/HCI等多领域的交叉,一方面帮助每个人更好的表达自己和创作优质内容,另一方面为每个人提供更好的内容体验和交互方式。
我们长期招聘GenAI、多模态等方向的优秀人才(社招、校招、实习生),欢迎加入我们!
邮箱:zhangluowa@kuaishou.com
©
(文:机器之心)