
给大家介绍一款新发布的开源 TTS 模型:Muyan-TTS,专为播客场景设计的开源文本转语音(TTS)模型。

它以超低延迟(0.33秒生成1秒音频)实现零样本语音合成,预训练10万+小时播客数据,支持长篇内容的高连贯性生成。
是一个特别适合播客、有声书或长视频场景的高效 TTS 模型。
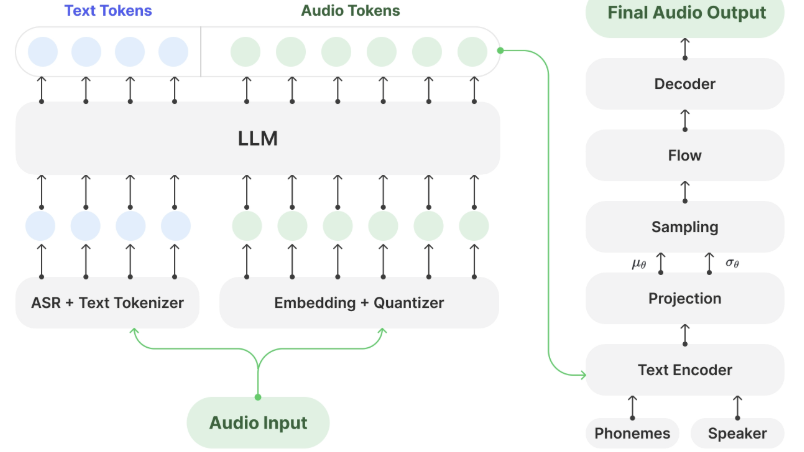
主要特点
-
• 快速生成:约 0.33 秒生成 1 秒音频,适合批量生成长语音内容; -
• 说话人适配:支持自定义说话人,进行个性化语音定制; -
• 支持长内容连贯合成:无需打断,可自然连续地朗读 5 分钟甚至更长文本; -
• 离线部署友好:Hugging Face 提供模型权重,支持本地推理。
快速使用
Muyan-TTS支持本地部署,需Python和GPU环境。以下是详细步骤:
依赖:需要本地安装 FFmpeg 工具。
① 克隆项目
git clone https://github.com/MYZY-AI/Muyan-TTS.git
cd Muyan-TTS② 创建虚拟环境并编译项目
conda create -n muyan-tts python=3.10 -y
conda activate muyan-tts
make build③ 下载模型
huggingface-cli download MYZY-AI/Muyan-TTS --local-dir ./models然后运行 python tts.py 即可快速使用。
核心代码如下:
async def main(model_type, model_path):
tts = Inference(model_type, model_path, enable_vllm_acc=False)
wavs = await tts.generate(
ref_wav_path="assets/Claire.wav",
prompt_text="Although the campaign was not a complete success, it did provide Napoleon with valuable experience and prestige.",
text="Welcome to the captivating world of podcasts, let's embark on this exciting journey together."
)
output_path = "logs/tts.wav"
with open(output_path, "wb") as f:
f.write(next(wavs))
print(f"Speech generated in {output_path}")需要指定提示语,包括 ref_wav_path 及其 prompt_text,以及要合成的 text。默认情况下,合成的语音保存到 logs/tts.wav。
当你将 model_type 指定为 base 时,可以更改提示语音,使其适用于任意说话人进行零样本TTS合成。
当你将 model_type 指定为 sft 时,需要保持提示语不变,因为sft模型是在Claire的声音上训练的。
同时还可以进行 API 方式的使用:
python api.py使用 API 模式会自动启用 vLLM 加速,上述命令将在默认端口 8020 上启动服务。
同样,需要将 model_type 指定为 base 或 sft,默认值为 base。需要注意的是,model_path应与你指定的model_type一致。
API使用示例:
import time
import requests
TTS_PORT=8020
payload = {
"ref_wav_path": "assets/Claire.wav",
"prompt_text": "Although the campaign was not a complete success, it did provide Napoleon with valuable experience and prestige.",
"text": "Welcome to the captivating world of podcasts, let's embark on this exciting journey together.",
"temperature": 0.6,
"speed": 1.0,
}
start = time.time()
url = f"http://localhost:{TTS_PORT}/get_tts"
response = requests.post(url, json=payload)
audio_file_path = "logs/tts.wav"
with open(audio_file_path, "wb") as f:
f.write(response.content)
print(time.time() - start)适用场景
-
• 播客语音生成:长段文字自然合成,节奏、语气稳定 -
• 有声书自动生成:可一次性生成整章内容,支持语音风格控制 -
• 英文视频配音:快速合成英文脚本,适配角色声音 -
• AI 角色朗读:零样本克隆任意声音,生成特色人物对话 -
• 自动新闻播报:文本转语音+语速控制,适合智能音箱或语音 UI
写在最后
Muyan-TTS 是一个新开源的、可训练的 TTS 模型,专为播客场景设计出来的。
虽然目前仅支持英文,但其零样本适配 + 快速合成 + 长文本能力也毋庸置疑。如果你正在做播客剪辑、有声书录制、AI 视频生成,Muyan-TTS 也会是你不可错过的开源新选择!
GitHub 开源地址:https://github.com/MYZY-AI/Muyan-TTS
HF 模型地址:https://huggingface.co/MYZY-AI/Muyan-TTS

● 一款改变你视频下载体验的神器:MediaGo
● 字节把 Coze 核心开源了!可视化工作流引擎 FlowGram 上线,AI 赋能可视化流程!
● 英伟达开源语音识别模型!0.6B 参数登顶 ASR 榜单,1 秒转录 60 分钟音频!
● 开发者的文档收割机来了!这个开源工具让你一小时干完一周的活!
● PDF文档解剖术!OCR神器+1,这个开源工具把复杂排版秒变结构化数据!

(文:开源星探)