

这篇笔记可能还有动态更新,笔记会放在 https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/large-language-model-note/sglang 这个目录下,感兴趣的小伙伴可以给这个仓库点个🌟🌟。
0x0. 前言
根据相关Benchmark 信息 SGLang 目前在单机H200上推理 DeepSeek V3/R1 应该是跑得最快的大模型开源推理框架,不过性能好坏其实也不是特别好说,因为各个框架都一直处于你追我赶的快速优化,随着时间随意领先幅度可能会缩小。我这里从开源技术分享的角度来盘点一下SGLang对单机规模推理的大量工程优化技巧,这里涉及的技巧其实也是我在参与SGLang开发中随时记录下的,自己也贡献了一部分,所以会比较详细一些。还要再说明一下,下面记录的是单机TP8不开MTP的相关优化。本文并且记录的都是在main分支上apply的优化,对于过时或者被删掉的优化技巧就忽略掉了。
目前的时间是2025年5月中旬,这里主要记录的是2025上半年针对 DeepSeek V3/R1 的优化,在这之前的一些优化可能更基操一些,就没有记录到,感兴趣可以参考一下SGLang之前比较老的版本的Release Blog之类的。这个时间线其实也是我参与SGLang开源的时间线,之前的我不是很熟悉就没回看了,并且在2025上半年前性能也不是太强,因为有太多值得优化的地方了。下面记录的优化有大有小,但是都是为单机规模的DeepSeek V3/R1推理性能提升做了贡献的,如果对应的优化所在的PR有性能数据我也会简单截图一下。需要说明一下,性能提升截图是控制变量的方式只突出当前优化的作用,所以你可以看到下面不同的图测出来的输出吞吐差异可能比大,这个是正常的因为main分支在不断合并优化导致性能在提升,只需要关注具体优化的有效性就可以了。
下面直接开始,我记录这个笔记是想到哪里记录到哪里的,并不是完全按照时间的先后顺序来。
0x1. FP8 Block GEMM 的演进
DeepSeek V3/R1 中单独的Linear对应的forward就是FP8 Block GEMM,经历了3次演进。首先是Triton的实现,代码仍保留在这里:https://github.com/sgl-project/sglang/blob/main/python/sglang/srt/layers/quantization/fp8_kernel.py#L743 ,当然这里也存在对各种参数在各种平台上的调优。由于性能比较差,后续演进到使用了Cutlass的实现,具体见sgl-kernel中的:https://github.com/sgl-project/sglang/blob/main/sgl-kernel/csrc/gemm/fp8_blockwise_gemm_kernel.cu 。随后,DeepSeek的DEEPGEMM开源,SGLang更进一步使用了DEEPGEMM的实现,并且解决好了缓存JIT编译结果的问题,具体见:https://github.com/sgl-project/sglang/blob/main/python/sglang/srt/layers/quantization/deep_gemm.py & https://github.com/sgl-project/sglang/blob/3e350a931e990c2b09cd18bc117ba219310bcda9/python/sglang/srt/layers/quantization/fp8_kernel.py#L784 。
现在SGLang中默认开启了DEEPGEMM,这个实现相比于sgl-kernel的cutlass实现,Triton实现基本上所有的case下都有优势,使用逻辑截图下:

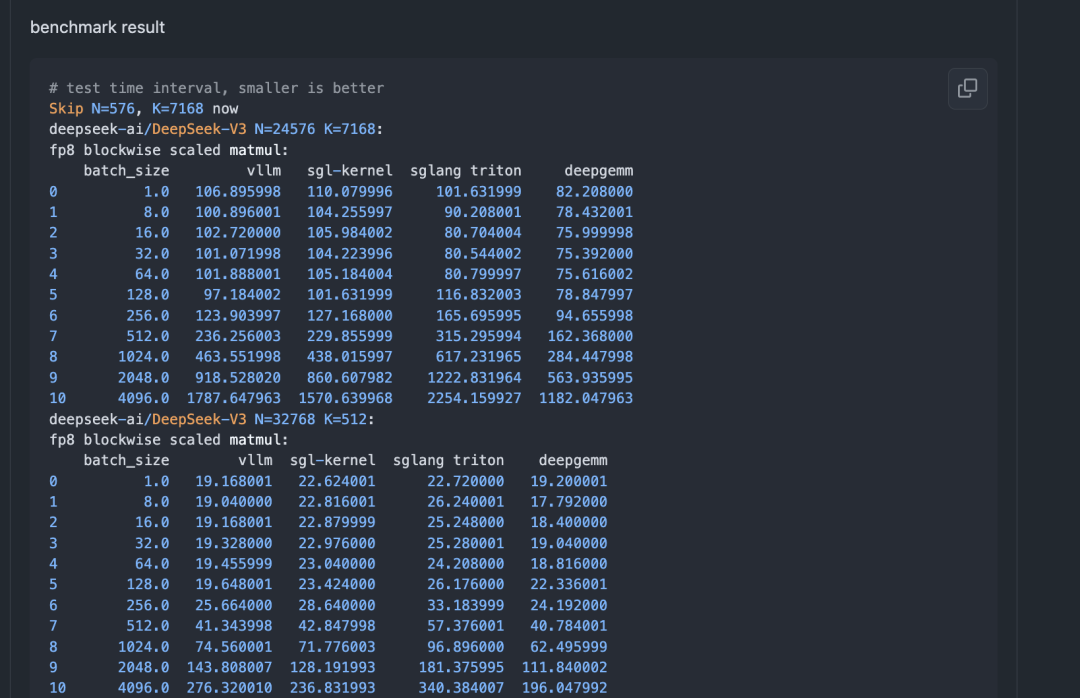
端到端的提升幅度和输入/输出数据长短有关系,例如10k-500这组数据输出吞吐端到端提升5%,256-4k这组数据输出吞吐端到端提升10%,这里的提升是相比于sgl-kernel cutlass实现来说的。
此外,基于DeepGEMM,SGLang还尝试将模型中的一系列BMM进行改写,核心idea是:per-token-group quant+deep_gemm's grouped_gemm_masked 比 per-tensor quant+bmm_fp8 更快 (https://github.com/sgl-project/sglang/pull/5432) 。不过这个优化可能会导致准确率出现问题,没有在生产环境中默认使用。
0x2. FusedMoE 模块的优化
这里分点列一下。
0x2.1 per_token_group_quant 和 moe_align_block_size 的kernel优化
代码见:https://github.com/sgl-project/sglang/blob/main/sgl-kernel/csrc/gemm/per_token_group_quant_8bit.cu & https://github.com/sgl-project/sglang/blob/main/sgl-kernel/csrc/moe/moe_align_kernel.cu 。
这两个操作都是FusedMoE模块的预处理部分,kernel整体占比没有很大,都是memory bound的kernel,但是通过优化可以把单个kernel的性能都提升很多倍。具体可以见PR开发时的micro benchmark结果,例如:https://github.com/sgl-project/sglang/pull/5086 。
num_tokens num_experts topk SGL Triton VLLM
160 1024.0 8.0 1.0 18.031999 52.512001 20.416001
161 1024.0 8.0 2.0 18.432001 67.135997 27.327999
162 1024.0 8.0 4.0 20.032000 116.640002 41.632000
163 1024.0 8.0 8.0 21.952000 205.136001 69.760002
164 1024.0 32.0 1.0 18.368000 55.071998 22.304000
165 1024.0 32.0 2.0 19.040000 55.583999 29.536000
166 1024.0 32.0 4.0 20.256000 55.264000 43.712001
167 1024.0 32.0 8.0 23.104001 71.744002 77.408001
168 1024.0 64.0 1.0 19.760000 56.031998 22.304000
169 1024.0 64.0 2.0 20.368000 54.095998 26.144000
170 1024.0 64.0 4.0 21.648001 55.103999 40.544000
171 1024.0 64.0 8.0 24.224000 58.272000 63.904002
172 1024.0 128.0 1.0 21.088000 56.848001 32.000002
173 1024.0 128.0 2.0 21.984000 55.551998 35.583999
174 1024.0 128.0 4.0 23.024000 55.808000 42.367999
175 1024.0 128.0 8.0 24.992000 56.127999 54.111999
176 1024.0 256.0 1.0 25.072001 52.480001 66.431999
177 1024.0 256.0 2.0 25.264001 52.576002 67.199998
178 1024.0 256.0 4.0 26.848000 52.416001 70.703998
179 1024.0 256.0 8.0 29.120000 57.663999 81.055999
这个也是我入坑SGLang开源的头几个贡献。
0x2.2 biased_grouped_topk 的 fuse kernel 优化
我们在SGLang中针对biased_grouped_topk(https://github.com/sgl-project/sglang/blob/main/python/sglang/srt/layers/moe/topk.py#L144)引入了一个fuse cuda kernel的优化,将十多个算子fuse成一个cuda kernel大大改进了grouped topk这块的性能。之前也写了一篇blog介绍这个优化:图解DeepSeek V3 biased_grouped_topk cuda融合算子fused_moe_gate kernel ,感兴趣可以查看,这里就不多赘述了。

kernel对应的PR见:https://github.com/sgl-project/sglang/pull/4530
DeepSeek V3/R1 推理性能端到端提升是5%-8%左右。
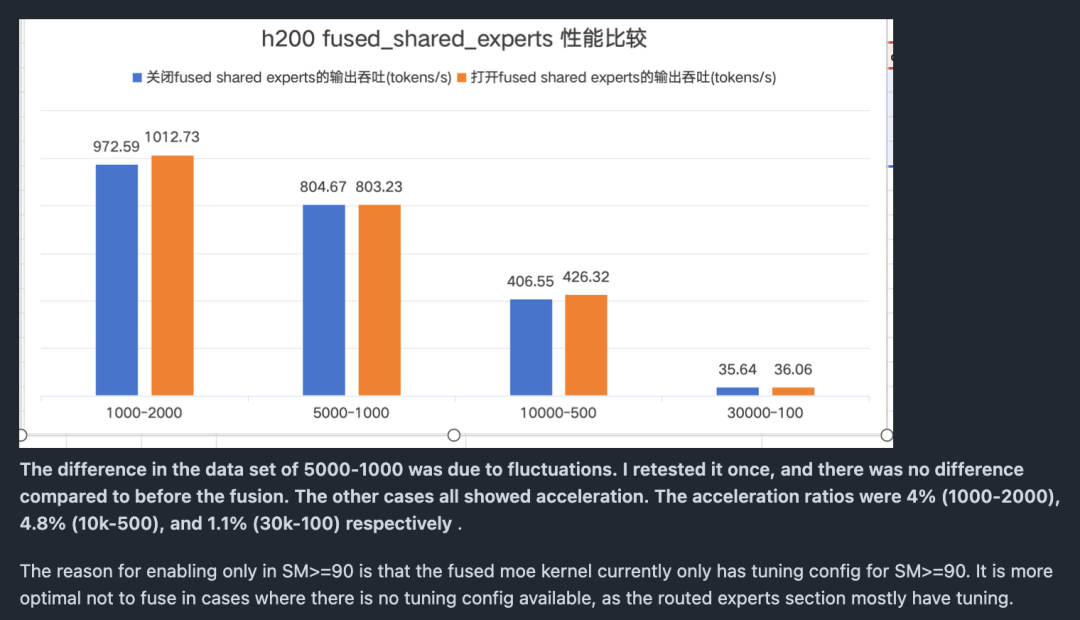
0x2.3 将Shared Experts和Route Experts融合
具体细节可以参考我之前写的这篇blog,这个优化花了我挺多时间去测试的,也是一个比较solid提升,分享一个DeepSeek V3和R1中 Shared Experts和普通Experts融合的一个小技巧 。下面是端到端的性能提升图:
0x2.4 Triton Fused MoE Retuning
升级PyTorch Triton版本之后社区小伙伴发现重新Tuning fused MoE kernel之后可以带来明显的性能提升,例如在Triton 3.2.0中如果继续延用Triton 3.1.0 tuning的config,则性能反而会下降,但如果重新Tuning则可以取得相比于Triton 3.1.0更好的性能。https://github.com/sgl-project/sglang/pull/5716 & https://github.com/sgl-project/sglang/pull/5740 ,通过重新Tuning Fused MoE kernel,在DeepSeek V3/R1上取得了性能提升。
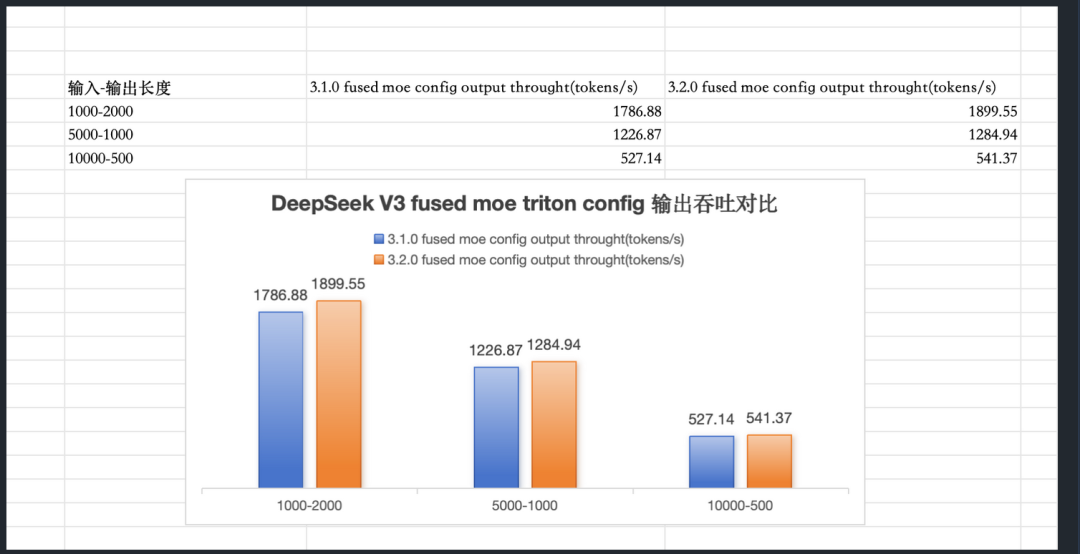
我还测试了一下Triton 3.2.0升级为Triton 3.3.0的提升:

基本也是符合这里的Retuning结论的。然后 https://github.com/vllm-project/vllm/pull/17934#issuecomment-2868822690 这里的一个 micro benchmark 性能测试也佐证了这一点。
0x2.5 Fuse routed scaling factor in topk_reduce kernel
把expert计算完之后最后乘以routed_scaling_factor的逻辑fuse到Fused MoE模块的最后那个topk_reduce_sum kernel中,具体可见:https://github.com/sgl-project/sglang/pull/6220 ,端到端提升如下:

0x2.6 一些额外的探索
在SGLang中也探索了一下TP模式下的基于Cutlass Grouped GEMM和DEEPGEMM的fused moe kernel实现,并跑通了正确性测试和性能测试,但是在TP8模式下相比于DeepSeek V3/R1的Triton Fused MoE kernel没有看到性能提升效果,这里就不详细介绍了。
0x3. Attention Backend的优化
0x3.1 Flash Attention V3 Backend
来自LinkedIn的优化,详情可见在 SGLang 中实现 Flash Attention 后端 – 基础和 KV 缓存 ,端到端吞吐提升结果如下所示:
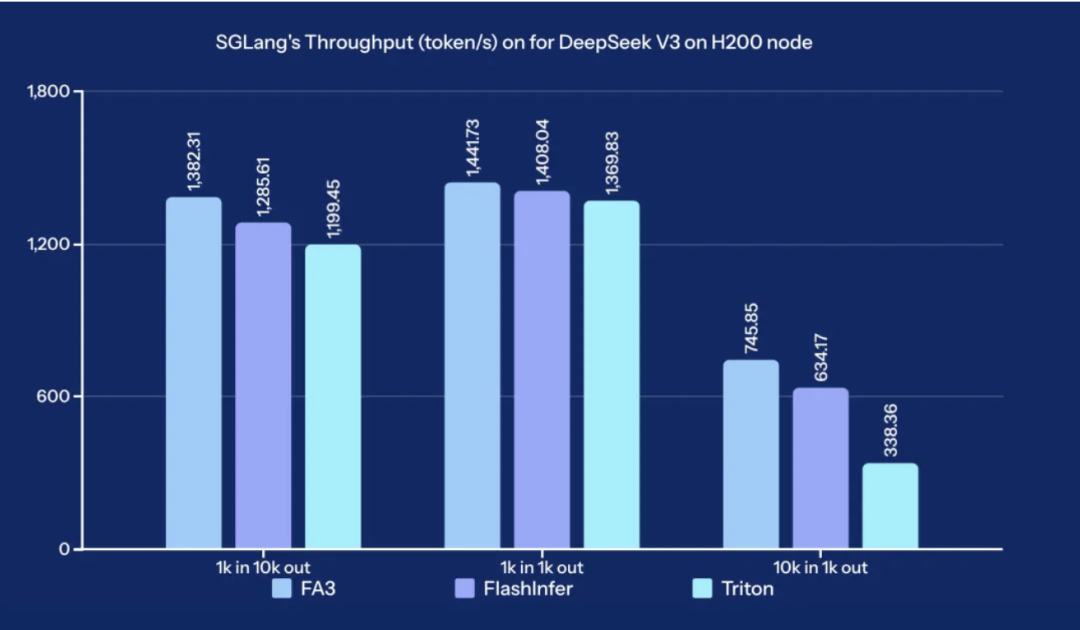
效果非常显著,然后SGLang社区也在推进hybrid Attention Backend以获得更加广泛的加速,可以参考:https://github.com/sgl-project/sglang/pull/6151 。
0x3.2 Cutlass MLA attention backend & FlashMLA Attention Backend
PR见:https://github.com/sgl-project/sglang/pull/5390 ,https://github.com/sgl-project/sglang/pull/4514 , https://github.com/sgl-project/sglang/pull/6034 等等。
虽然有很多的Attention Backend可选,例如最开始用的是FlashInfer的Backend,不过目前SGLang默认使用了Flash Attention V3 Backend,至少在H200上大多数Case下都拥有最好的性能。
0x4. MLA的优化
0x4.1 forward_absorb 中多余的copy
对应https://github.com/sgl-project/sglang/pull/5578,这个优化移除了q_input和k_input等临时变量的创建和处理,去掉了多个涉及self.kv_lora_rank的复制和切片操作。修改如下所示:
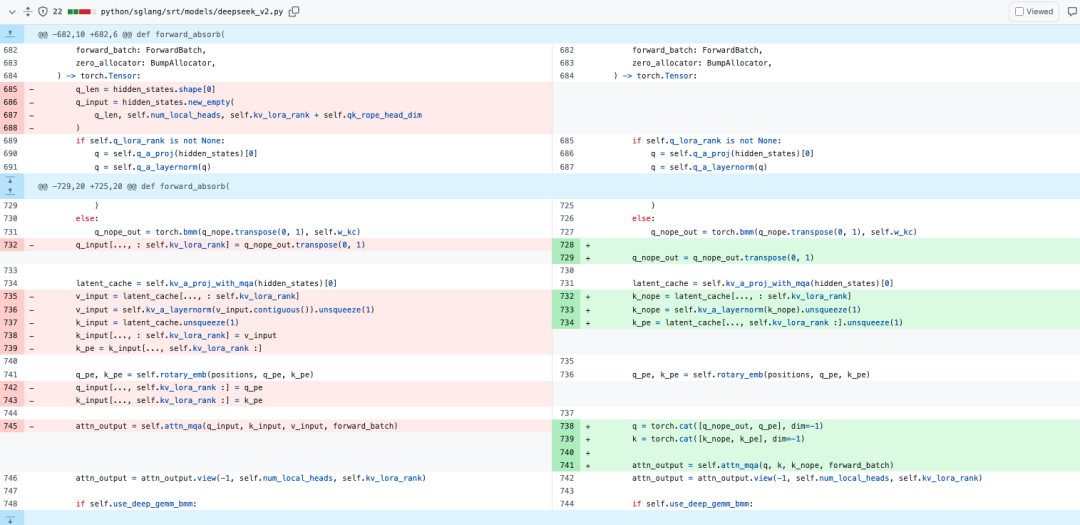
benchmark结果如下所示:

0x4.2 MHA和MQA的选择策略优化
推荐阅读:vLLM在Prefill阶段和Decode阶段对MLA的不同实现的对比分析(https://zhuanlan.zhihu.com/p/1897225385751585767) 了解idea的细节
这篇文章里面提到MLA在一次推理中,Prefill阶段使用的是MHA实现方式,Decode阶段使用的是MQA的实现方式,两种不同主要是Q * K的矩阵计算顺序不同带来的差异,所以矩阵不需要真正意义上的吸收,改变只是计算的顺序。此外,在SGLang中如果考虑了Chunked Prefix Cache,并且满足batch中所有序列的prefix长度之和大于等于chunked_prefix_cache_threshold,仍然使用MHA实现方式(这里是MHA_CHUNKED_KV)。可以参考下面的代码片段:
elif self.attention_backend == "fa3":
# Flash Attention: Use MHA with chunked KV cache when prefilling on long sequences.
if forward_batch.extend_prefix_lens_cpu isnotNone:
sum_extend_prefix_lens = sum(forward_batch.extend_prefix_lens_cpu)
if (
forward_batch.forward_mode.is_extend()
andnot self.disable_chunked_prefix_cache
andnot forward_batch.forward_mode.is_target_verify()
andnot forward_batch.forward_mode.is_draft_extend()
and (
sum_extend_prefix_lens >= self.chunked_prefix_cache_threshold
or sum_extend_prefix_lens == 0
)
):
return AttnForwardMethod.MHA_CHUNKED_KV
else:
return AttnForwardMethod.MLA
详情可以参考:https://github.com/sgl-project/sglang/pull/5113 ,也是2025上半年的优化 。下面是一些Benchmark结果截图:
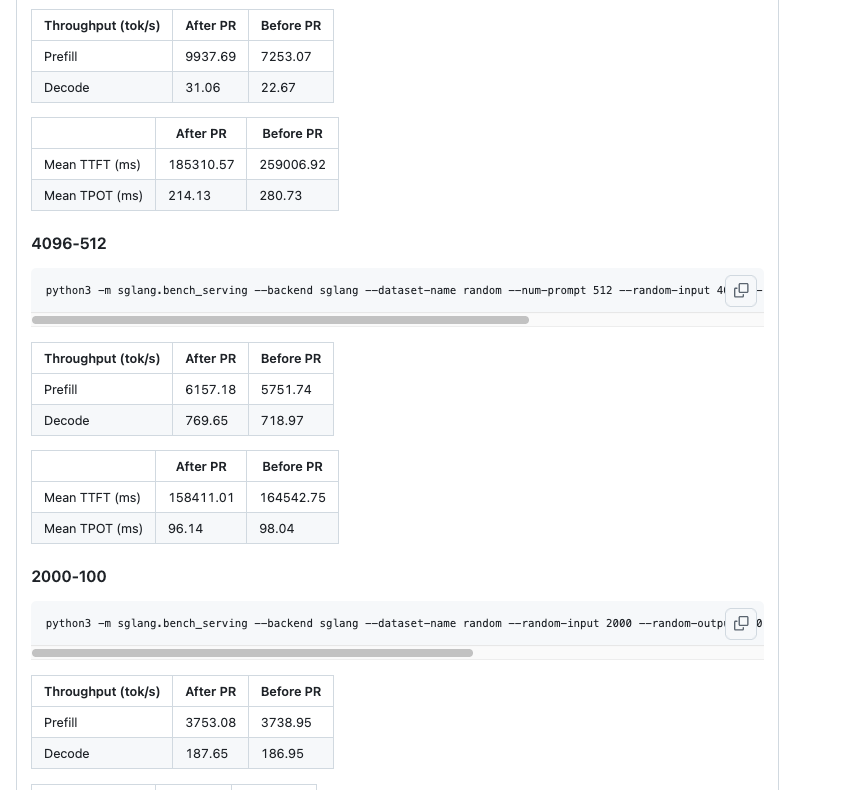
可以看到对整体的端到端吞吐提升也是明显的。
0x4.3 Merge Attention States kernel优化
来自 @DefTruth(https://www.zhihu.com/people/qyjdef) 的 kernel 优化,他在知乎上也针对这个算子写了几篇blog,感兴趣可以看:
-
[vLLM实践][算子]📚vLLM算子开发流程: “保姆级”详细记录 (https://zhuanlan.zhihu.com/p/1892966682634473987) -
[Triton编程][基础]📚vLLM Triton Merge Attention States Kernel详解 (https://zhuanlan.zhihu.com/p/1904937907703243110)
在SGLang中的PR为:https://github.com/sgl-project/sglang/pull/5381 ,Benchmark可以参考:https://github.com/sgl-project/sglang/pull/5381#issue-2993195410
对整体的影响比较小,因为kernel的micro benchmark显示提升普遍比较有限,这个是用在上面介绍到的MHA_CHUNKED_KV模式下。
0x4.4 Fuse q_a_proj 和 kv_a_proj
这个优化对应的PR见:https://github.com/sgl-project/sglang/pull/5619
在 DeepSeek v3 的自注意力模块中,q_a_proj 和 kv_a_proj 都以隐藏状态作为输入,因此它们可以被融合成一个模块,从而节省一次 DeepGemm 的启动。对应的改动是:当 q_lora_rank 大于 0 时(这对 DeepSeek V3 和 R1 来说是成立的), self.q_a_proj 和 self.kv_a_proj_with_mqa 会被融合成一个新的模块 self.fused_qkv_a_proj_with_mqa。在加载权重时,q_a_proj 和 kv_a_proj 的权重和 block scales 会被拼接并加载到 self.fused_qkv_a_proj_with_mqa 中。benchmark结果如下所示:
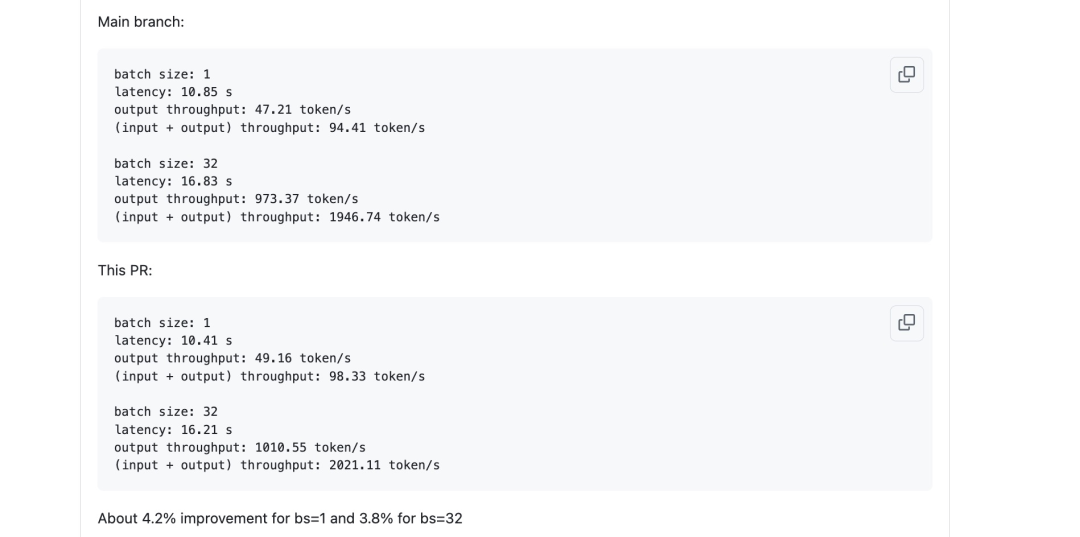
对于bs=1时提升了约4.2%,对于bs=32时提升了约3.8%。
0x4.5 Fuse MLA set kv cache kernel
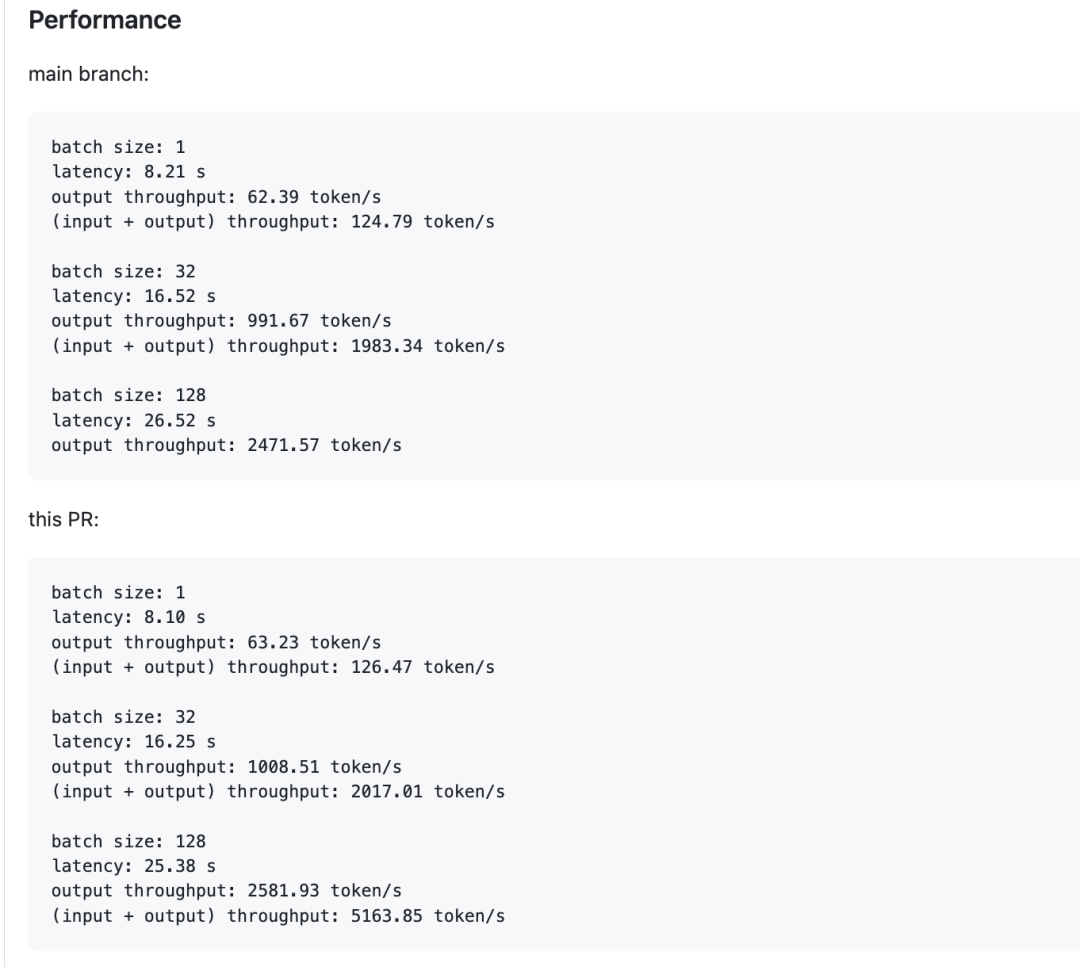
这个优化对应的PR见:https://github.com/sgl-project/sglang/pull/5748
它做的事情是融合 MLA set kv cache kernel 并移除 k concat 操作。目前仅支持 FA3 后端。后续验证后可以应用到其他后端。
0x5. DeepSeek V3/R1 其它的优化技巧记录
0x5.1 Overlap qk norm with two streams
通过2个CUDA Stream把DeepSeek V3/R1 Attention 部分的 forward_absorb 实现中对q, k分别做rmsnorm的无数据依赖的操作overlap起来。PR见:https://github.com/sgl-project/sglang/pull/5977
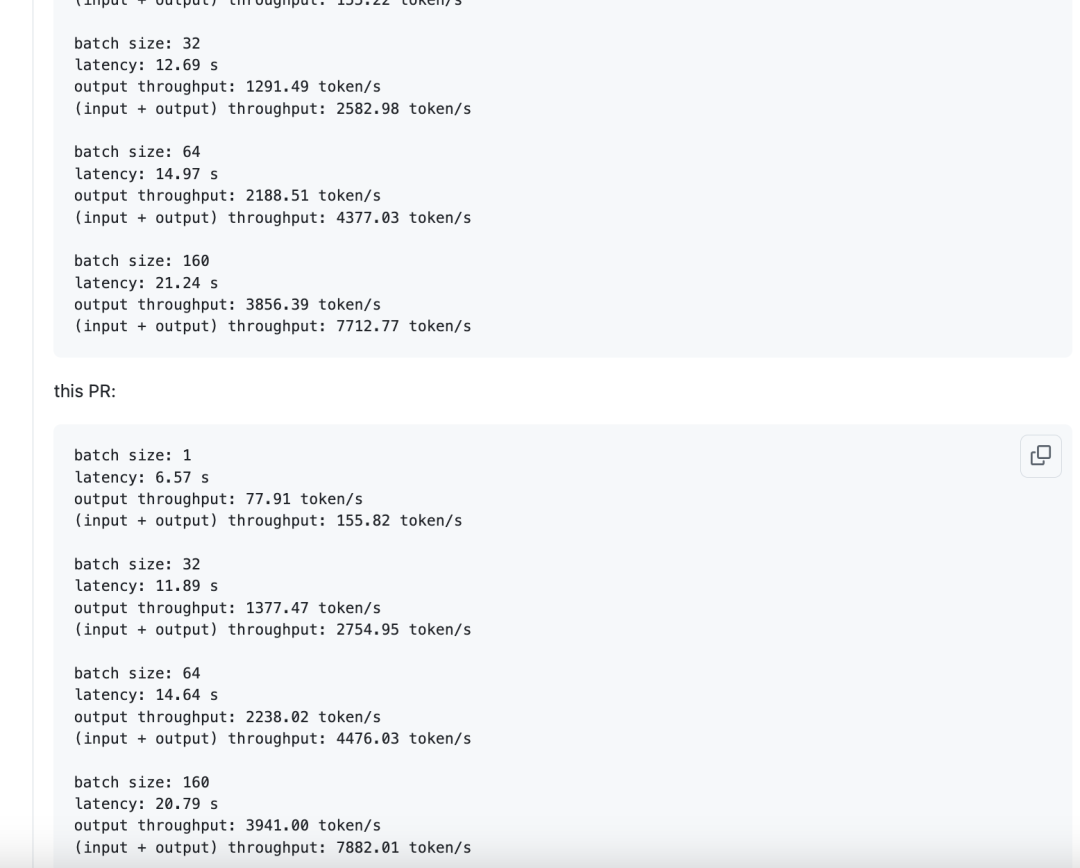
0x5.2 层间复用的 BumpAllocator
这里的出发点是每一层Layer我们都要做输入做量化,然后做量化的时候都需要给量化算子申请一个新的zero scalar tensor,为了避免重复申请Tom做了一个BumpAllocator,达到可以层间内存复用的目的,减少不同层重复创建torch.zeros的目的。PR见:https://github.com/sgl-project/sglang/pull/5549
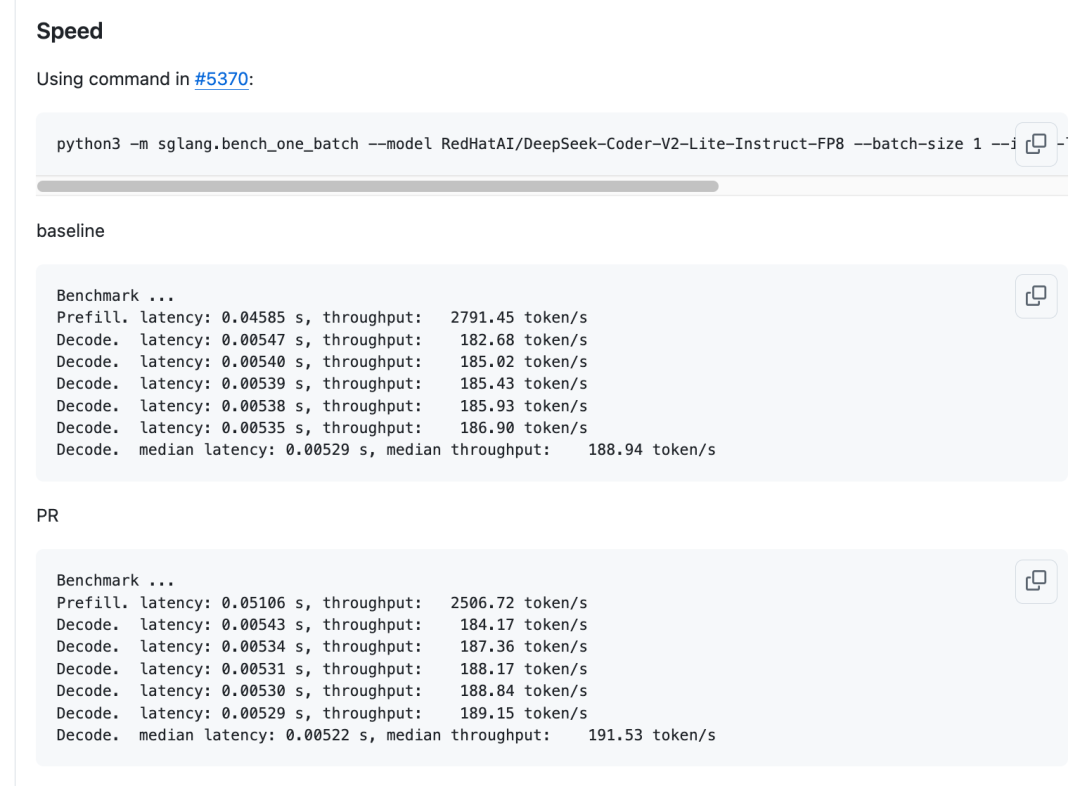
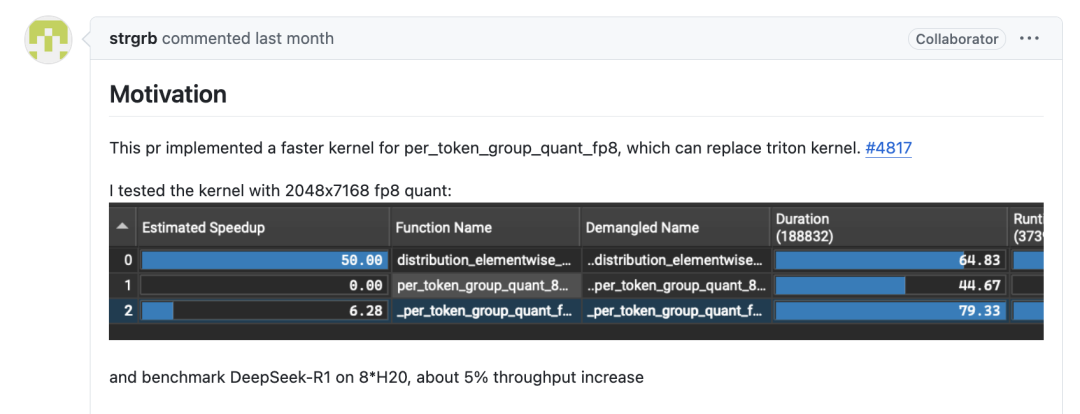
0x5.3 使用sgl-kernel 的 sglang_per_token_group_quant_fp8 算子而不是Triton实现
PR见:https://github.com/sgl-project/sglang/pull/5473
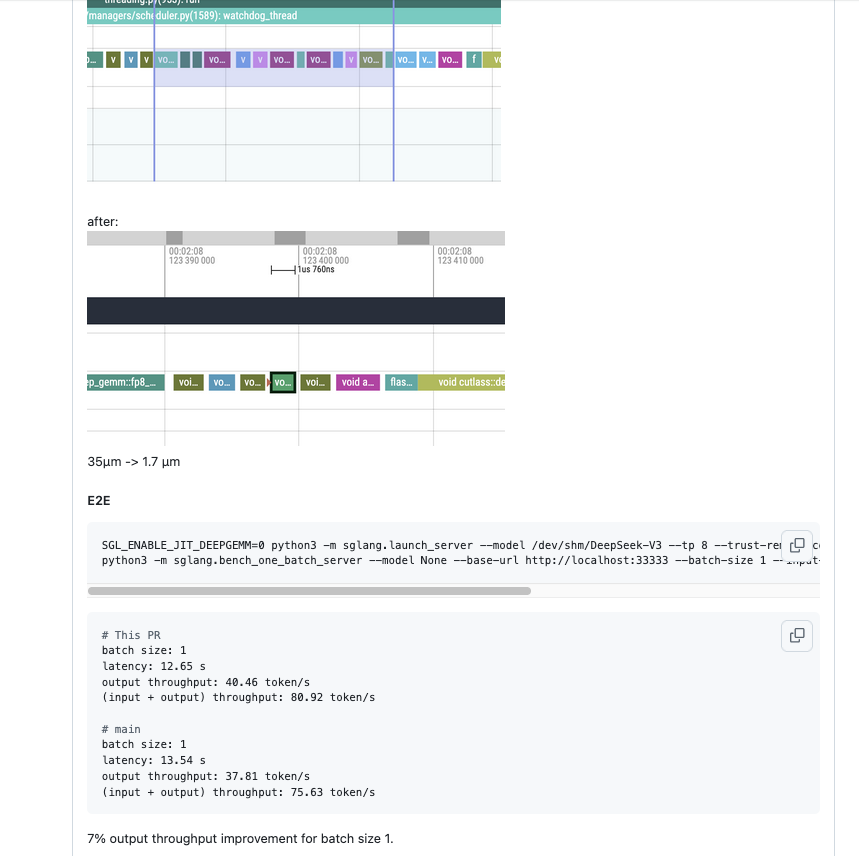
0x5.4 在DeepSeek V3/R1 应用cuda rope
PR见:https://github.com/sgl-project/sglang/pull/5385
0x5.5 优化 MLA 的 fp8 quant kernel
这个优化的出发点是下面这张图右上角的bmm要用deepgemm或者cutlass fp8 bmm 来做,所以需要把输入从bf16转换为fp8。
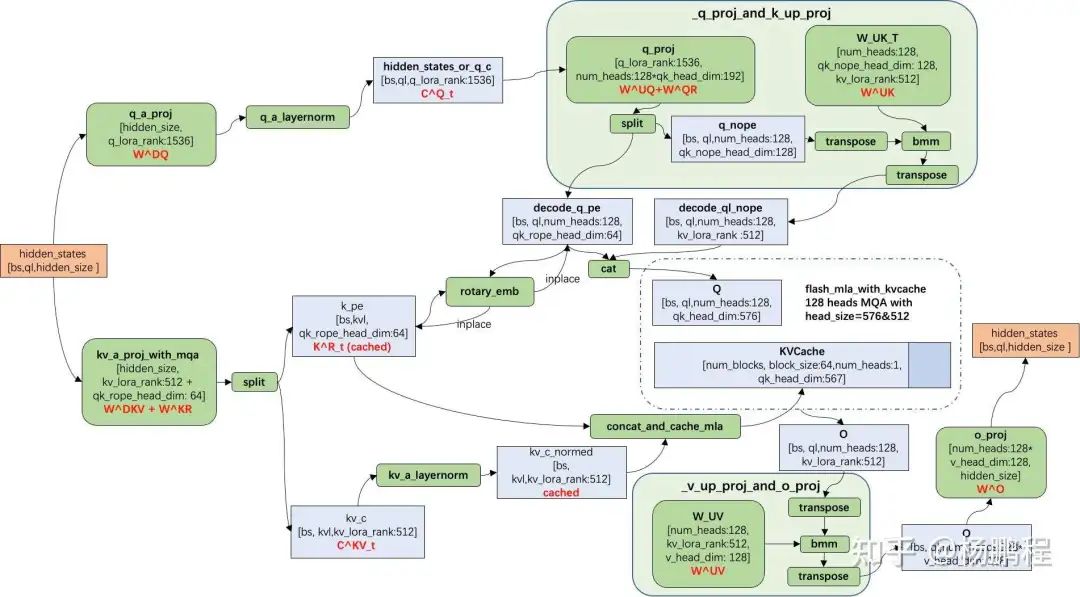
例如我们以deepgemm bmm为例子,代码如下:
q_nope, q_pe = q.split([self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
k_pe = latent_cache[..., self.kv_lora_rank :].unsqueeze(1)
if self.use_deep_gemm_bmm:
q_nope_val, q_nope_scale, masked_m, expected_m, aligned_m = (
per_token_group_quant_mla_deep_gemm_masked_fp8(q_nope.transpose(0, 1))
)
q_nope_out = q_nope.new_empty(
(self.num_local_heads, aligned_m, self.kv_lora_rank)
)
deep_gemm_grouped_gemm_nt_f8f8bf16_masked(
(q_nope_val, q_nope_scale),
(self.w_kc, self.w_scale_k),
q_nope_out,
masked_m,
expected_m,
)
q_nope_out = q_nope_out[:, :expected_m, :]
这个PR做的事情就是用Triton实现了一个per_token_group_quant_mla_deep_gemm_masked_fp8 kernel,在这之前这个操作是由一堆小算子组成的,所以这个也是CUDA kernel fuse的技巧,为了方便这里是直接用Triton实现了一个kernel。
0x6. 总结
我目前的记录大概就是这些,然后需要说明的是对于某一个优化并不是一个PR就能完成的,可能是一个十分长期的过程。例如一个kernel可能在几个月的时间里都有更新,再例如Flash Attention V3根据这个feature的roadmap做了长时间的优化和解决bug,都是非常不容易的工程优化。如果大家对SGLang单机H200推理DeepSeek V3/R1感兴趣的可以阅读源码获得一手信息。
综合上面的各种优化,DeepSeek V3/R1在单机H200上推理的吞吐相比于年初应该被提升了几倍,如果本文对你有帮助,欢迎转发,点赞以及给SGLang点赞,谢谢支持。
(文:GiantPandaCV)