
计算所王颖研究员团队联合华北电力大学和上海科技大学团队,在计算机体系结构顶级会议ASPLOS 2025(ACM International Conference on Architectural Support for Programming Languages and Operating Systems)上发表并开源了COMET框架。该框架通过系统-算法协同优化,实现了权重(W4)、激活(A4)和KV缓存(KV4)全4比特推理的实际性能突破,在LLaMA-70B等大模型上仅造成0.32的困惑度微增,同时实现2.02倍的端到端推理加速,创造了大模型量化推理技术领域的新标杆。
技术亮点
-
三大量化维度全破壁:权重、激活、KV缓存全面压缩至4比特,精度损失仅0.32
-
GPU算力压榨术:独创通道重排+异步流水线,硬件利用率冲上76%
-
开源即战:5行代码集成TensorRT-LLM,LLaMA-3、Qwen全家族适配
-
实测数据炸场:70B模型长序列推理最高可达3.27倍加速,端侧设备部署成本直降70%
大模型“瘦身”生死局
全球大模型军备竞赛已陷入“能耗地狱”——GPT-4单次训练耗电堪比5000户家庭年用电量,推理成本更是高居不下。传统量化技术如同“瘸腿赛跑”:
-
权重量化(W4A16):权重压到4比特,但激活值仍用16比特计算,GPU算力浪费超70%
-
权重激活双量化(W8A8):为保精度牺牲性能,加速比仅1.3倍,长序列场景内存照样崩
当全球AI团队还在为“权重量化精度损失”和“激活量化性能瓶颈”焦头烂额时, COMET框架给出了一个完美答案:让算法设计与硬件特性深度咬合,在4比特的极限压缩下实现近乎无损的推理性能。
传统量化方案往往陷入“顾此失彼”的困境:权重量化虽能压缩存储,但激活值仍占用高精度计算资源;权重激活双量化又因硬件适配不足,导致实际加速比远低于理论值。COMET从GPU底层架构出发,重新解构量化逻辑与计算内核优化,在三个关键维度实现突破:
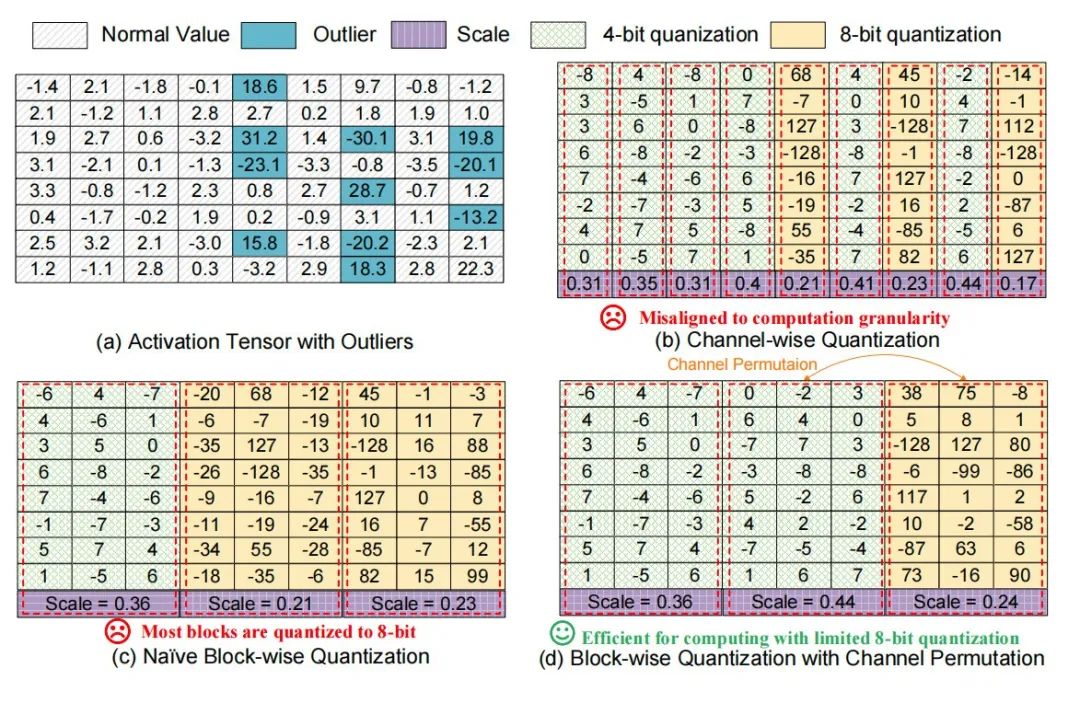
1.离群点分布规律的重定义
通过对LLaMA等主流大模型的深入分析,研究团队首次发现,激活中的异常值并非随机分布,而是高度集中在约10%的特定通道中。这一关键发现为提出的细粒度混合精度量化算法(FMPQ)的设计奠定了基础。在实际落地过程中,团队提出了一种兼顾精度与效率的创新方案:首先,采用硬件友好的分块方式,将激活张量按128通道划分,使其天然适配现代GPU张量核心的64×64×32计算结构,从而确保量化操作与底层执行单元高度对齐。同时,为应对激活离群值的非均匀分布,算法引入了动态精度调控机制——将8比特高精度分配给异常值密集的“重点区域”,而其余部分则压缩为4比特,在保证模型精度的前提下显著提升运算效率。
更进一步,FMPQ还引入了通道重排策略,通过智能置换,将分散的离群点集中到相同的计算块中,从而减少高精度计算资源的消耗。
2.混合精度计算的动态调度
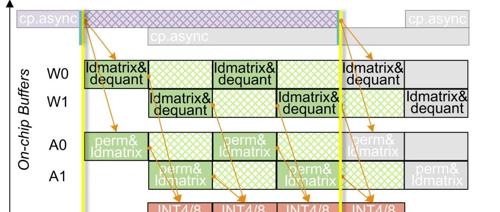
在实际部署中,W4A4与W4A8混合精度计算往往会带来计算负载的不均衡,成为系统性能的瓶颈。为此,研究团队构建了一套三层异步流水线架构,以最大化GPU资源的利用率。
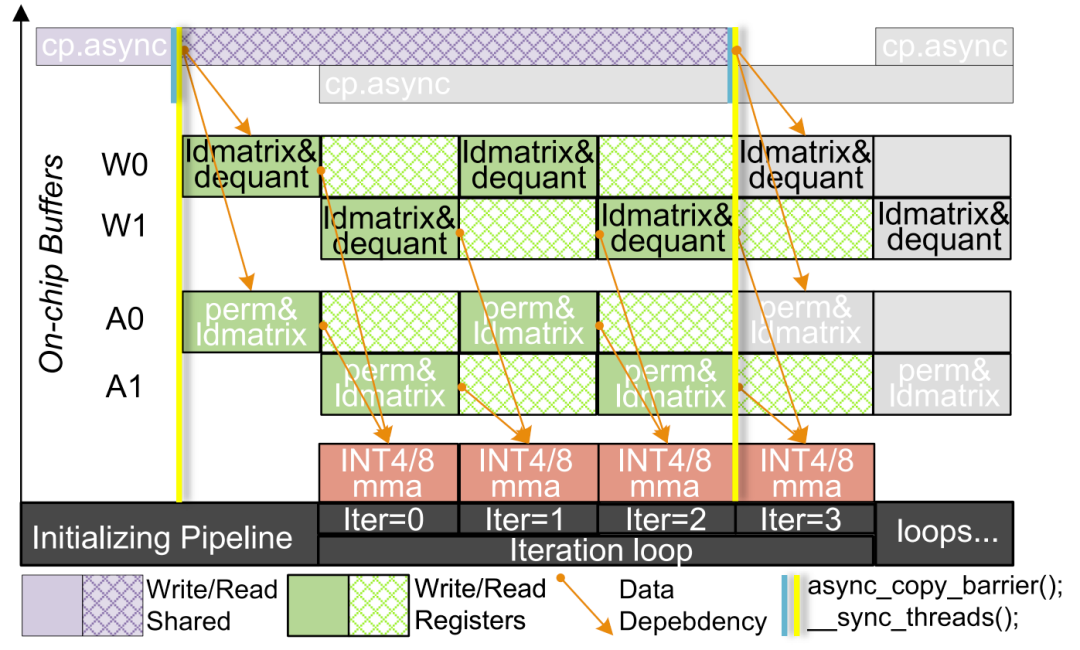
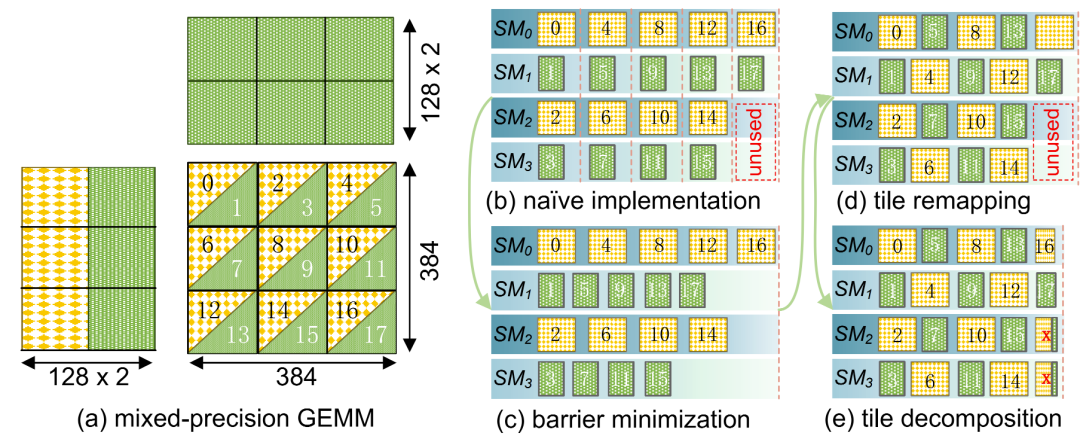
整个架构设计从数据传输和计算重叠入手,借助双缓冲机制,在数据预取的同时启动计算,有效隐藏了加载延迟,确保张量核心始终处于高效运行状态。同时,团队打破了传统“Tile一SM(Streaming Multiprocessor)”的固定分配策略,引入了更灵活的SM协作机制,使空闲的计算单元可以动态接管邻近任务,极大缓解了局部资源闲置的问题。
更进一步,提出的COMET还在任务调度上实现了细粒度优化。系统会根据实际计算强度,动态调整INT4和INT8任务的分配比例,从而将不同SM核心间的负载差异控制在5%以内,实现几乎均衡的算力分布。
3.硬件指令集的极限挖掘
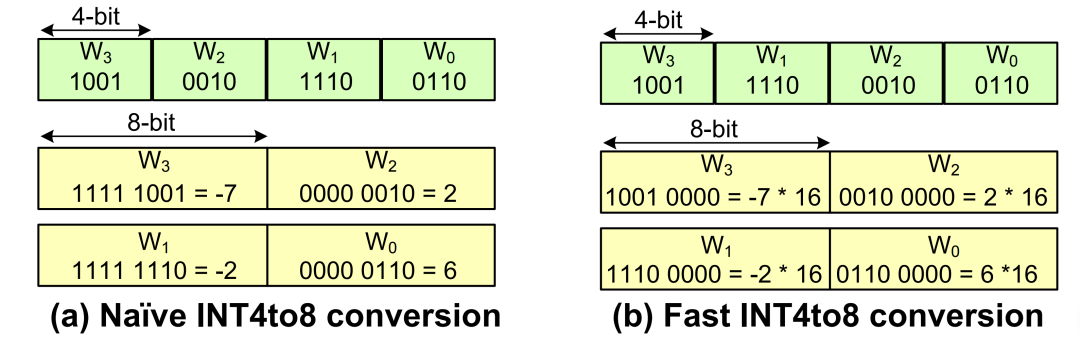
在4比特量化领域,真正的技术挑战并不在于量化本身,而在于数据转换的效率瓶颈。传统方法往往需要多达10条指令才能完成一次4比特到8比特的转换操作,严重制约了实际部署性能。为此,研究团队从底层硬件指令集出发,深入挖掘GPU的潜力,通过对数据存储格式和指令流的重构,将这一过程优化至只需两条指令即可完成。
这种极简方案的核心在于两项关键突破:其一,团队充分利用GPU PTX指令的特性,使得打包在16位中的4个4比特数值可以被同时提取,极大提升了解包效率;其二,巧妙地用“零扩展”替代了传统的“符号扩展”策略,通过缩放参数的补偿机制,等价保持了整体精度表现的稳定性。得益于这一设计,转换效率相比传统方法实现了高达5倍的提升。
实测性能碾压现有方案
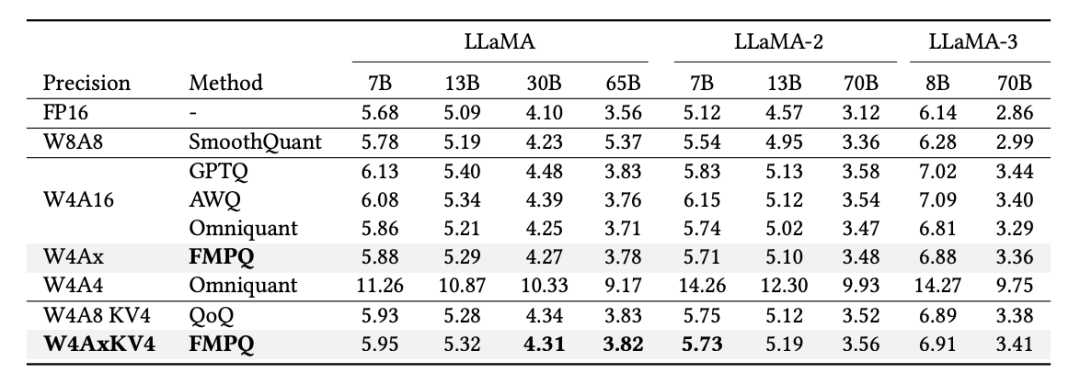
在4比特极致压缩的背景下,COMET框架通过细粒度混合精度量化技术,有效抑制了量化带来的精度损失。在实际测试中,LLaMA-7B模型在WikiText2数据集上的困惑度仅从5.68小幅上升至5.95,误差控制在5%以内,显示出高度鲁棒性。更具代表性的是,在LLaMA-3-70B这样的大模型上,困惑度提升更是被压缩至0.36,精度表现相比传统方案提升超过三倍。此外,COMET还对KV缓存结构进行了优化,首次将键值存储压缩至4比特,不仅将长序列场景下的内存占用削减了75%,同时额外引入的精度损失控制在0.05以内,几乎可以忽略。更令人瞩目的是,COMET在精度表现上已逼近FP16的浮点基准,显著优于W4A4和W8A8等主流量化策略的效果。
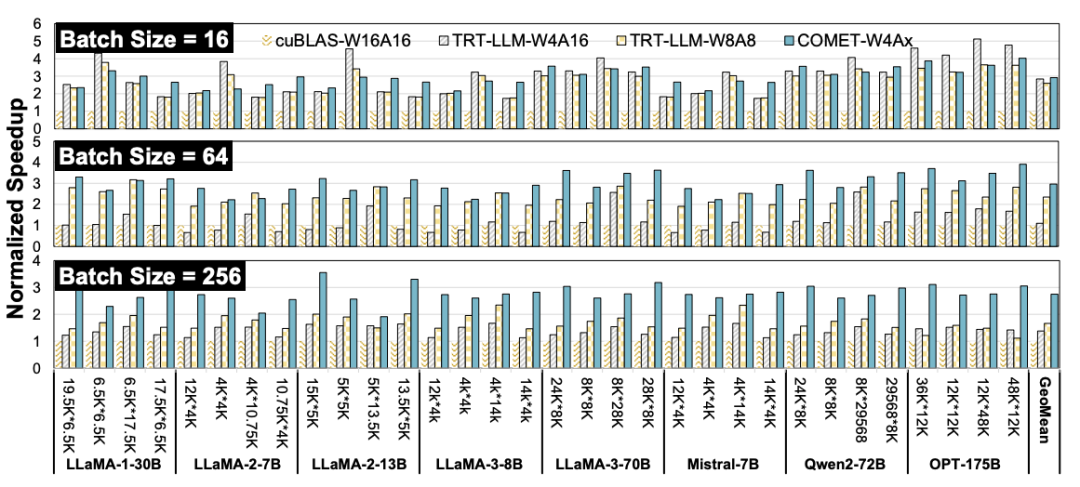
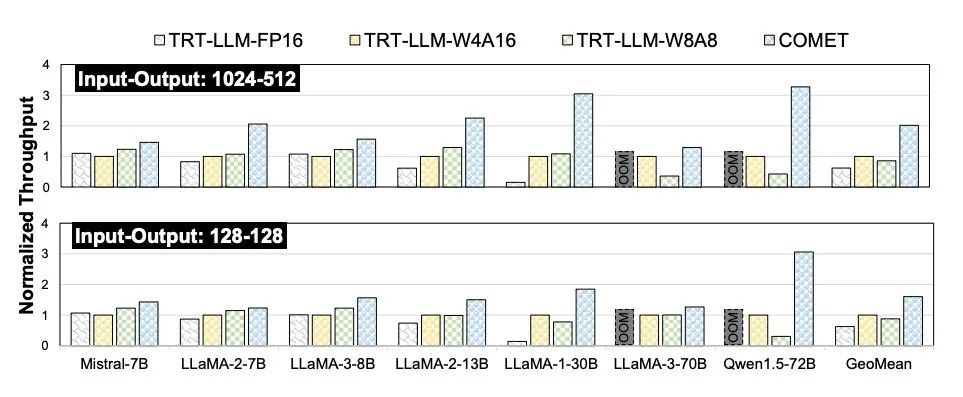
而在性能层面,COMET同样展现出跨越性的突破。以A100 GPU为例,深度优化的COMET-W4Ax计算内核在适配LLaMA、Mistral、Qwen等主流模型时,实现了对cuBLAS内核2.75至2.97倍的加速。更重要的是,这种性能优势在端到端推理过程中得到了充分延续,在长序列任务中(如1024 token输入),整体吞吐量提升达到3.27倍,即使在短序列场景(128 token),也能获得1.63倍的增益。借助异步流水线与动态调度机制,GPU SM的利用率从原本的45%大幅提升至76%,极大释放了底层硬件的潜力。

目前,COMET-W4Ax的内核与接口已正式开源,开发者只需短短5行代码,即可将其集成至TensorRT-LLM框架,实现从压缩到加速的一体化部署,进一步推动大模型落地的普及与平民化。
目前,论文《COMET: Towards Practical W4A4KV4 LLMs Serving》已正式出版,通过论文链接https://dl.acm.org/doi/pdf/10.1145/3676641.3716252可直接下载。论文详细介绍了研究成果,并提供了完整的框架开源代码地址,欢迎大家评论。
本文为投稿文章,作者:华北电力大学程龙教授。
(文:AIGC开放社区)