


0x00 前言
后续会陆续更新一些CUDA和Triton Kernel编程入门向的文章,虽然比较浅显简单,但我自己挺喜欢这种温故而知新的感觉。
本人更多的技术笔记以及CUDA学习笔记,欢迎来LeetCUDA(https://github.com/xlite-dev/LeetCUDA)查阅。LeetCUDA包括了本人的LLM/VLM文章整理,以及对FlashAttention、SGEMM、HGEMM、GEMV等常见CUDA Kernel的示例实现,目前已经累计3k+ stars,传送门:xlite-dev/LeetCUDA(https://github.com/xlite-dev/LeetCUDA)

LeetCUDA: Modern CUDA Learn Notes with PyTorch for Beginners
本人Triton相关笔记列表如下:
-
DefTruth:[Triton编程][基础] Triton极简入门: Triton Vector Add(https://zhuanlan.zhihu.com/p/1902778199261291694) -
DefTruth:[Triton编程][基础] Triton Fused Softmax Kernel详解: 从Python到PTX(https://zhuanlan.zhihu.com/p/1899562146477609112) -
DefTruth:[Triton编程][基础] vLLM Triton Merge Attention States Kernel详解(https://zhuanlan.zhihu.com/p/1904937907703243110) -
DefTruth:[Triton编程][进阶] vLLM Triton Prefix Prefill Kernel图解(https://zhuanlan.zhihu.com/p/695799736)
本文内容包括:
-
0x00 前言 -
0x01 Triton编程基础 -
0x02 Triton Vector Add -
0x03 PyTorch封装 -
0x04 PTX Gen code -
0x05 性能 -
0x06 总结
0x01 Triton编程基础
核心点:Triton的编程粒度是Block(每个Block只会被调度到一个SM上),而不是Thread。我们只需要考虑每个Block需要做什么,至于Thread/Warp的分布和调度,Triton自动给我们处理了。
关于OpenAI Triton,这里只做简单的介绍。网上可以找到大量入门的文章,本文也先不重复了。本文主要关注Prefix Prefill Kernel的实现,而非深挖Triton的底层的原理。
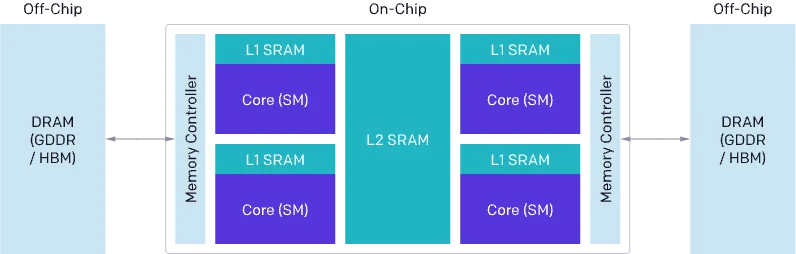
传统的基于 CUDA 进行 GPU 编程难度较大,在优化 CUDA 代码时,必须考虑到数据流在DRAM、SRAM 和 ALU之间的Load/Store的问题,还需要仔细考虑到Grid、Block、Thread和Warp等不同级别的调度优化问题。这些问题包括但不限于:
1. 从 DRAM 的内存传输必须合并成大型事务,以利用现代内存接口的大总线宽度(内存合并访问)。
2. 数据必须在重复使用前手动存储到 SRAM 中,并进行管理来最小化bank conflict。
3. 计算必须仔细地进行划分和调度,不仅是在流式多处理器(SMs)之间,还包括在其内部,以促进指令/线程级并行性,并利用专用的 ALU(例如,Tensor Cores)。
因此,哪怕是CUDA熟练工,也得花费不少的精力,才能写出一个性能接近理论峰值的Kernel。Triton 的出现,降低了CUDA Kernel编写的难度,它将一些需要精心设计的优化策略进行自动化,比如内存事务合并、SRAM分配和管理、流水线优化等,从而使得编程人员可以将更多的精力放在算法本身。

从官方放出的这个表格中,我们可以看到,如果使用Triton,内存事务合并、SRAM管理以及SM内的线程调度都是自动进行的,我们只需要把精力花在SM之间管理即可,这也就是说,Triton的编程粒度是Block(每个Block只会被调度到一个SM上),而不是Thread。我们只需要考虑每个Block需要做什么,至于Thread/Warp的分布和调度,Triton自动给我们处理了。那么,Block这个概念,在Triton中通过什么进行表达呢?答案是:program。

block -> program,在Triton中,使用program_id来标识一个唯一的program。编程人员只需要考虑一个program(block)内的编程逻辑,比如这个最简单的add_kernel。x_ptr,y_ptr, 和output_ptr分别是指向第一个输入向量、第二个输入向量和输出向量的指针。这些向量存储在 GPU 的内存中。比较常见的就是PyTorch和Triton一起使用,Triton将会传入的Tensor当成指针来处理,而非数据张量。BLOCK_SIZE: tl.constexpr表示一个triton的编译时常量,表示每个 block需要处理的元素数量。mask = offsets < n_elements表示创建一个mask以防止内存操作超出范围。tl.load和tl.store分表表示triton中的数据加载和写入的操作,这也是需要注意的,Triton为了能更好地进行性能优化,它是在指针级别上做操作的,而非数据Tensor级别。
0x02 Triton Vector Add
importtriton
importtriton.languageastl
@triton.jit
defadd_kernel(x_ptr,# *Pointer* to first input vector.
y_ptr,# *Pointer* to second input vector.
output_ptr,# *Pointer* to output vector.
n_elements,# Size of the vector.
BLOCK_SIZE:tl.constexpr,# Number of elements each program should process.
# NOTE: `constexpr` so it can be used as a shape value.
):
# There are multiple 'programs' processing different data. We identify which program
# we are here:
# 有多个'程序'(也就是block)处理不同的数据。我们在这里标识我们是哪个程序:
pid=tl.program_id(axis=0)# We use a 1D launch grid so axis is 0.
# This program will process inputs that are offset from the initial data.
# For instance, if you had a vector of length 256 and block_size of 64, the programs
# would each access the elements [0:64, 64:128, 128:192, 192:256].
# Note that offsets is a list of pointers:
# 该程序将处理与初始数据偏移的输入。
# 例如,如果您有长度为 256 的向量和块大小为 64,程序
# 将分别访问元素[0:64, 64:128, 128:192, 192:256]。
# 请注意,偏移量是指针的列表:
block_start=pid*BLOCK_SIZE
offsets=block_start+tl.arange(0,BLOCK_SIZE)
# Create a mask to guard memory operations against out-of-bounds accesses.
# 创建一个mask以防止内存操作超出范围。
mask=offsets<n_elements
# Load x and y from DRAM, masking out any extra elements in case the input is not a
# multiple of the block size.
x=tl.load(x_ptr+offsets,mask=mask)
y=tl.load(y_ptr+offsets,mask=mask)
output=x+y
# Write x + y back to DRAM.
tl.store(output_ptr+offsets,output,mask=mask)0x03 PyTorch封装
提示:Triton将会传入的Tensor当成指针来处理,而非数据张量
defadd(x:torch.Tensor,y:torch.Tensor):
# 我们需要预先分配输出。
output=torch.empty_like(x)
assertx.is_cudaandy.is_cudaandoutput.is_cuda
n_elements=output.numel()
# SPMD启动网格表示并行运行的内核实例数。
# 它类似于CUDA启动网格。对于add_kernel我们使用一个1D网格,其大小是块的数量:
grid=lambdameta:(triton.cdiv(n_elements,meta['BLOCK_SIZE']),)
# 注意:
# - 每个torch.tensor对象都隐式地转换为指向其第一个元素的指针。
# - `triton.jit`'ed函数可以通过一个启动网格索引来获得一个可调用的GPU内核。
# - 不要忘记将元参数作为关键字参数传递。
add_kernel[grid](x,y,output,n_elements,BLOCK_SIZE=1024)
# 我们返回一个指向z的句柄,但是,由于`torch.cuda.synchronize()`尚未被调用,内核此时仍在异步运行。
returnoutput需要注意的是,Triton将会传入的Tensor当成指针来处理,而非数据张量。并且,由于Triton Kernel也是异步调用的,因此在测试性能的时候,需要在函数返回后添加torch.cuda.synchronize()。更详细的Triton 入门,推荐阅读:如何入门 OpenAI Triton 编程? (https://www.zhihu.com/question/622685131)以及 科密中的科蜜:OpenAI Triton 入门教程(https://zhuanlan.zhihu.com/p/684473453),讲解地很详细,本文Triton部分内容参考自这两篇文章(侵删)。
1. Program相当于CUDA编程中的Block,program_id相当于block id。
2. CUDA的编程模型从grid-block-thread,被简化为Block-wise,kernel启动时,只需要考虑一个grid中block的布局。比如,grid=(M,N,D/BLOCK_K)表示这个gird是一个3D的block布局。
0x04 PTX Gen code
明确地知道Triton到底生成了什么代码(PTX),对于我们分析性能瓶颈是有帮助的。这里记录一下一个简单有效的分析Triton kernel的方法(当然ncu,nsys用上就更好了)。通常,我们也想知道,到底Triton实际上生成了啥kernel,比如说,生成的kernel PTX是怎么样的,有没有用上向量化,有没有cp.async,合并访存到底做好了没有。这个时候,我们可以指定TRITON_CACHE_DIR环境变量,把Triton生成的中间IR文件给保存下来,进行分析。
exportTRITON_CACHE_DIR=$(pwd)/cache
python3 triton_vector_add.py
# tree gen codes
cd cache && tree .
.
├── QLAEYTJR4KV5WSBGJKRUAKVP475DE47NW7P4XMI2RFXBOIE5TZ4Q
│ └── cuda_utils.so
├── ZARIVSGCNM2WWDVKCRVGVJENDT5COGJCEQYAY47GLLIBDH2FTW2A
│ ├── add_kernel.cubin
│ ├── add_kernel.json
│ ├── add_kernel.llir
│ ├── add_kernel.ptx
│ ├── add_kernel.ttgir
│ ├── add_kernel.ttir
│ └── __grp__add_kernel.json
└── ZQ5DTL26WSB4LIKU54SE5N3EGMWSTLNP3XSOKNNVT6YBZ3ECSBOA
└── __triton_launcher.soTriton会生成多级的中间IR,其中ttir->ttgir->ttllir是Triton的编译过程中源语言生成 AST后,产生的MLIR表达式,逐层降级(Lowering)最后经过 MLIR 分析器,生成目标硬件程序(Backend),具体编译器的实现细节暂且不管(也不是我擅长的);而最后生成的PTX和cubin,则是与目标硬件相关的代码/二进制(这里的case是NVIDIA GPU, CUDA);推荐阅读:液态黑洞:窥探Triton的lower(一)(https://zhuanlan.zhihu.com/p/695171704);因此,就我个人而言,大部分情况下,只要去关注PTX就可以了,即add_kernel.ptx,本案例生成的部分PTX汇编代码如下:
@%p2ld.global.v4.b32{%r13,%r14,%r15,%r16},[%rd4+0];
//endinlineasm
mov.b32%f13,%r13;
mov.b32%f14,%r14;
mov.b32%f15,%r15;
mov.b32%f16,%r16;
.loc15417//triton_vector_add.py:54:17
add.f32%f17,%f1,%f9;
add.f32%f18,%f2,%f10;
add.f32%f19,%f3,%f11;
add.f32%f20,%f4,%f12;
add.f32%f21,%f5,%f13;
add.f32%f22,%f6,%f14;
add.f32%f23,%f7,%f15;
add.f32%f24,%f8,%f16;
.loc15626//triton_vector_add.py:56:26
add.s64%rd5,%rd9,%rd10;
add.s64%rd6,%rd5,2048;
.loc15635//triton_vector_add.py:56:35
mov.b32%r17,%f17;
mov.b32%r18,%f18;
mov.b32%r19,%f19;
mov.b32%r20,%f20;
//begininlineasm
@%p1st.global.v4.b32[%rd5+0],{%r17,%r18,%r19,%r20};通过分析生成PTX汇编代码,我们发现,Triton对add_kernel正确地使用了ld.global.v4.b32和st.global.v4.b32这两个向量化访存的指令;而我们在python代码中,只需要在kernel中调用tl.load/tl.store,线程级别的访存合并,Triton会自动进行。
0x05 性能
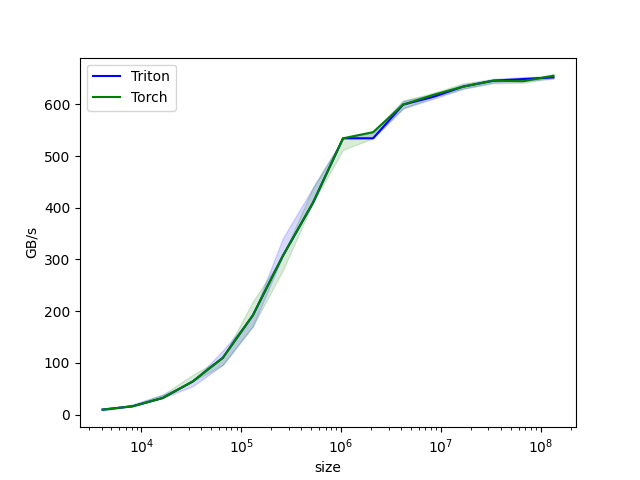
最后,再简单对比一下Triton Verctor Add Kernel和pytorch中cuda实现的add算子的性能。案例修改自Triton官方示例,Vector Addition – Triton documentation(https://triton-lang.org/main/getting-started/tutorials/01-vector-add.html#sphx-glr-getting-started-tutorials-01-vector-add-py),可以来 LeetCUDA/openai-triton/elementwise(https://github.com/xlite-dev/LeetCUDA/tree/main/kernels/openai-triton/elementwise) 直接开跑。从下图可见,Triton Verctor Add Kernel和pytorch的add算子,性能基本一致。
0x06 总结
本文简单对比了Triton Kernel编程和CUDA编程的主要区别,说明了Triton的编程粒度是Block,而不是Thread,我们只需要考虑每个Block需要做什么即可;并且,介绍了通过PTX分析Gen code的方式,便于我们判断Triton生成的算子是否符合预期;最后,通过Vector Add的示例来讲解Triton kernel的编程方式,其生成的kernel和pytorch原生算子性能相当,代码在 LeetCUDA/openai-triton/elementwise(https://github.com/xlite-dev/LeetCUDA/tree/main/kernels/openai-triton/elementwise)。
本人更多的技术笔记以及CUDA学习笔记,欢迎来LeetCUDA(https://github.com/xlite-dev/LeetCUDA)查阅。LeetCUDA包括了本人的LLM/VLM文章整理,以及对FlashAttention、SGEMM、HGEMM、GEMV等常见CUDA Kernel的示例实现,目前已经累计3k+ stars,传送门:https://github.com/xlite-dev/LeetCUDA
老样子,错误先更后改……
– The End –

长按二维码关注我们
本公众号专注:
1. 技术分享;
2. 学术交流;
3. 资料共享。
欢迎关注我们,一起成长!
(文:GiantPandaCV)