
【CUDA编程】关于矩阵乘加操作的四个指令(ldmatrix、mma、stmatrix、movmatrix)详解
rix)详解
写在前面
:在 GPU Tensor Core 的编程实践中,笔者此前通过矩阵乘法优
rix)详解
写在前面
:在 GPU Tensor Core 的编程实践中,笔者此前通过矩阵乘法优

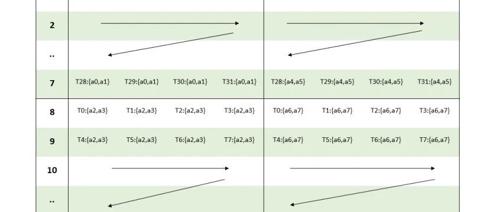
CUDA kernel执行重叠可以通过调整blocks_per_grid的值来实现。通过使用不同的blocks_per_grid值,可以观察到不同kernel执行之间的重叠效果。隐式同步可能导致默认流中的CUDA命令间的同步问题,并可通过启用per-thread default Stream来解决。







